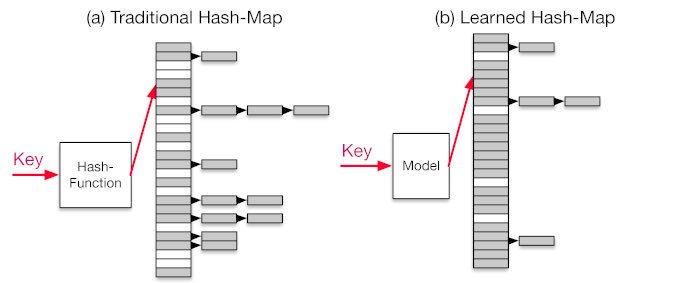
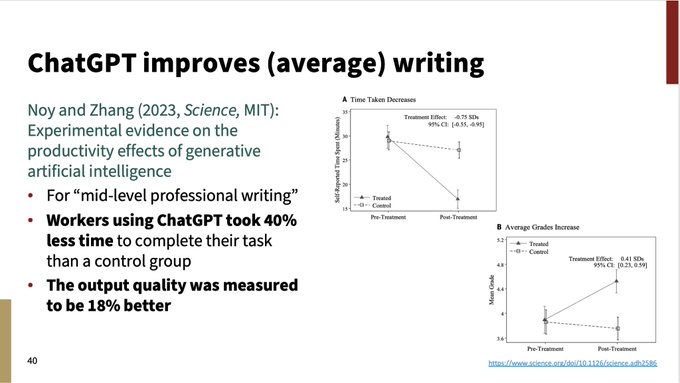
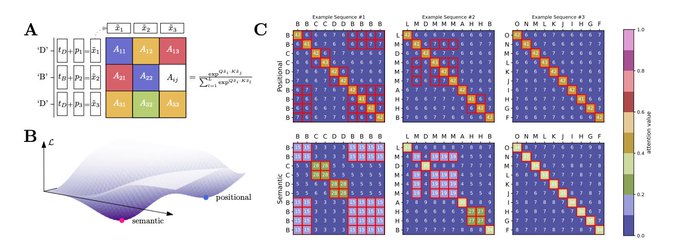
Christopher Manning
@chrmanning
126,509
Followers
116
Following
132
Media
2,337
Statuses
Director, @StanfordAILab . Assoc. Director, @StanfordHAI . Founder, @stanfordnlp . Prof. CS & Linguistics, @Stanford . IP @aixventureshq . 🇦🇺 Do #NLProc & #AI . 👋
Don't wanna be here?
Send us removal request.