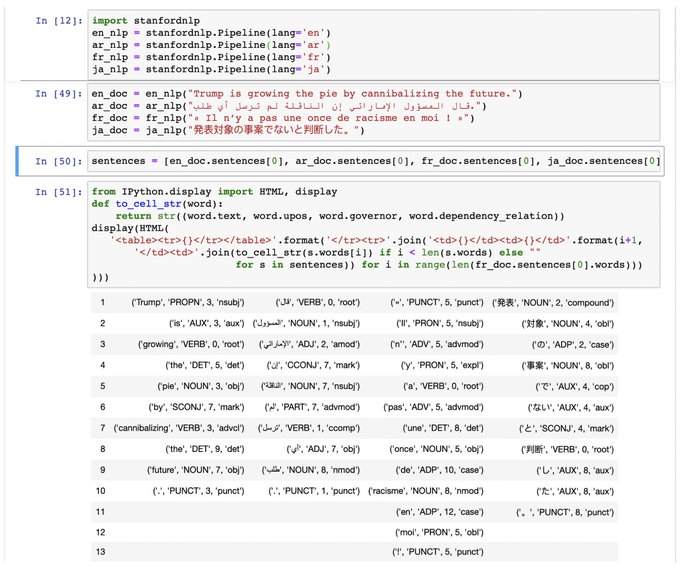
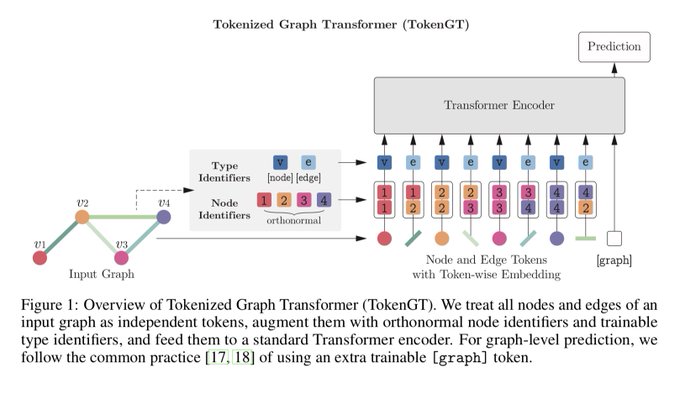
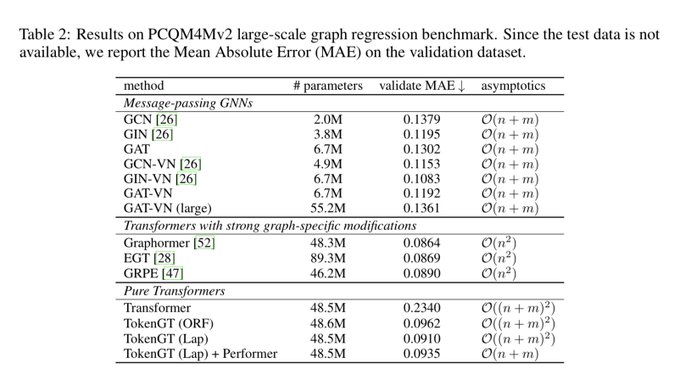
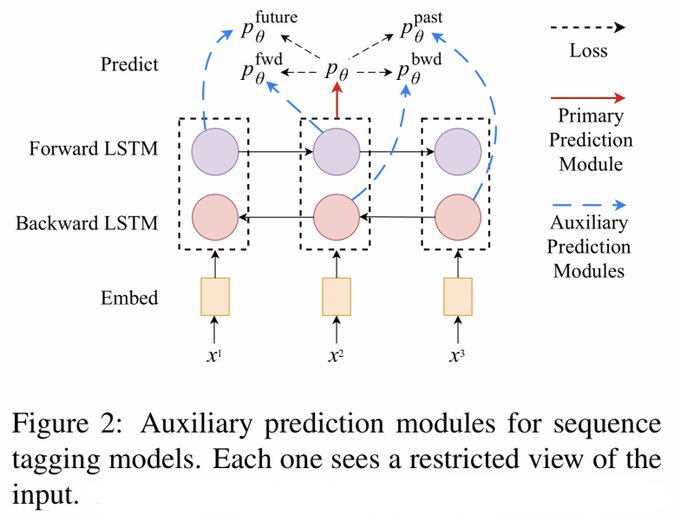
Stanford NLP Group
@stanfordnlp
144,641
Followers
179
Following
461
Media
12,556
Statuses
Computational Linguists—Natural Language—Machine Learning @chrmanning @jurafsky @percyliang @ChrisGPotts @tatsu_hashimoto @MonicaSLam @Diyi_Yang @StanfordAILab
Don't wanna be here?
Send us removal request.