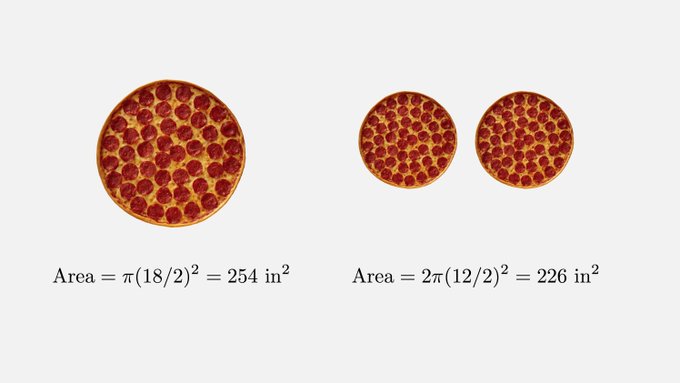
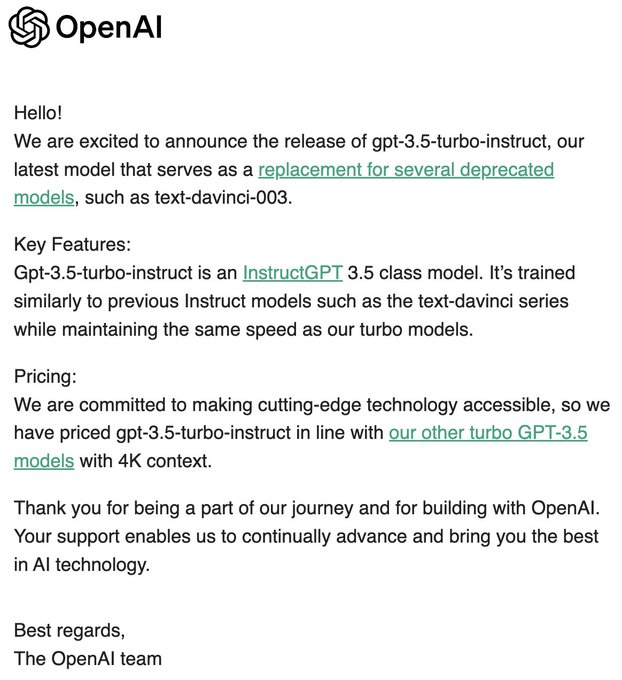
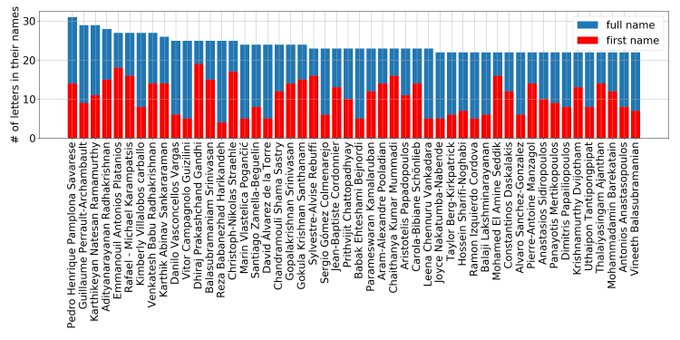
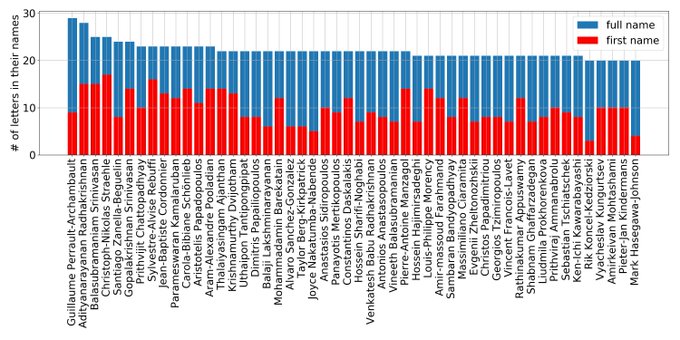
Kyunghyun Cho
@kchonyc
61,607
Followers
2,247
Following
1,369
Media
12,488
Statuses
a combination of a mediocre scientist, a mediocre manager, a mediocre advisor & a mediocre PC at @nyuniversity ( @CILVRatNYU ) & @genentech ( @PrescientDesign ).
Don't wanna be here?
Send us removal request.