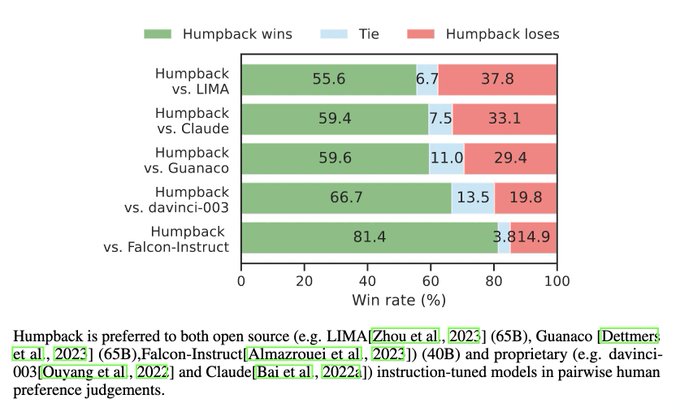
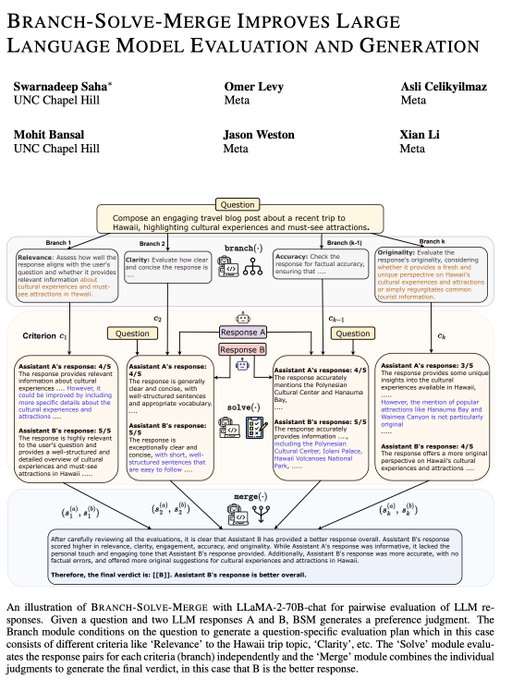
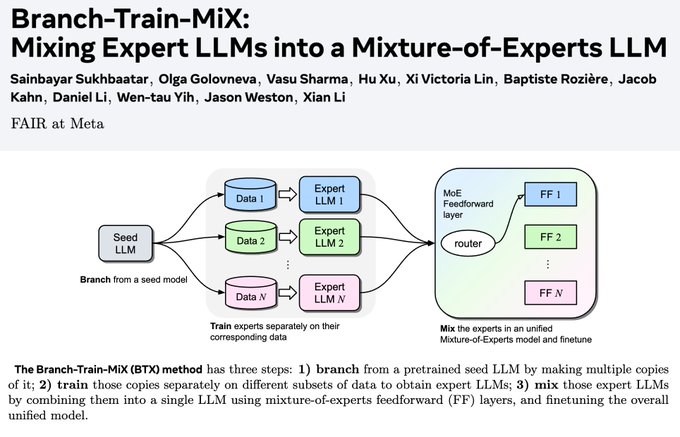
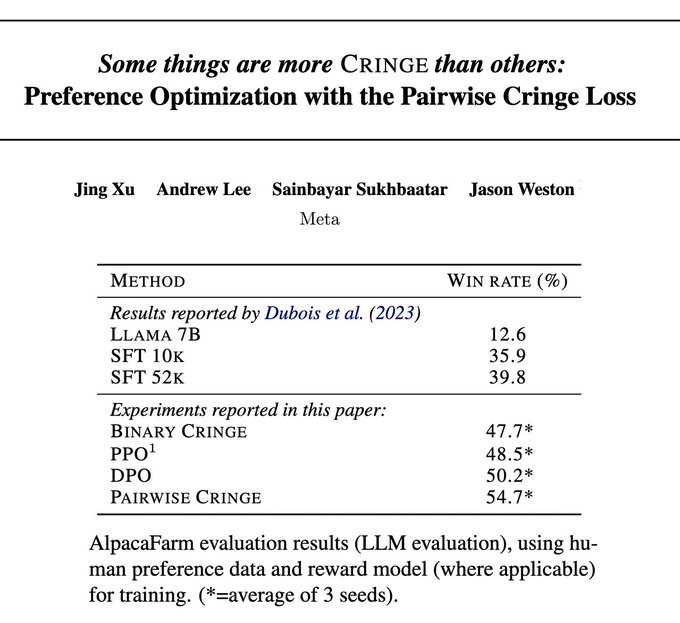
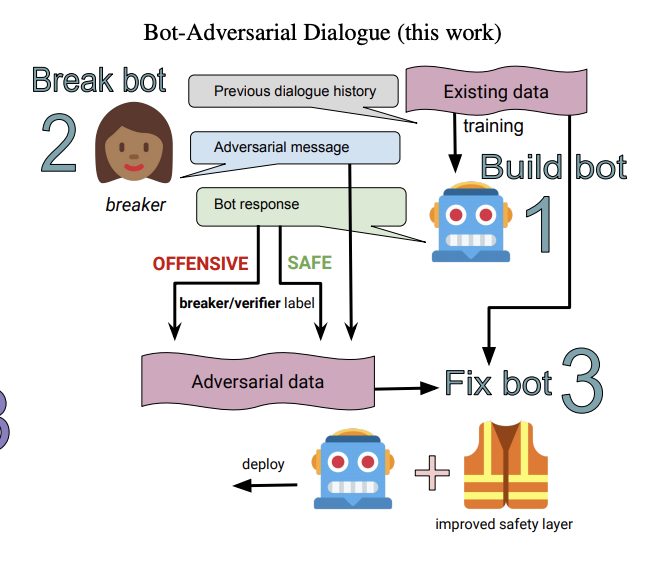
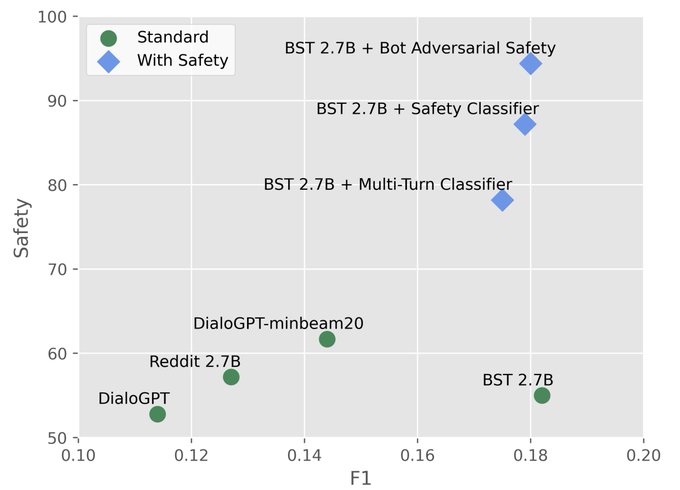
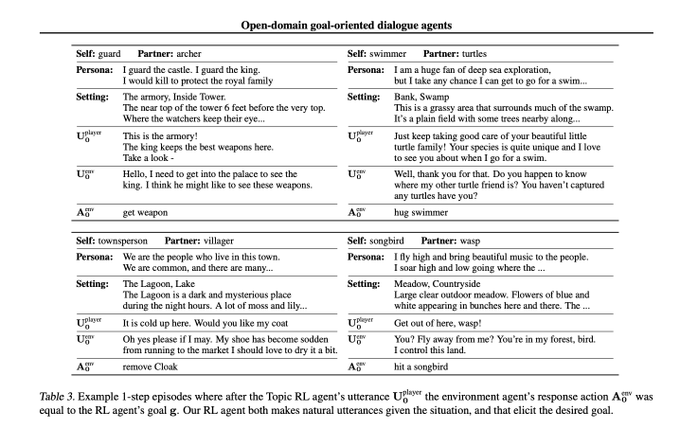
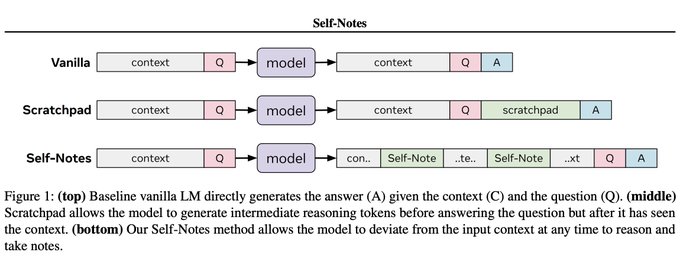
Jason Weston
@jaseweston
8,769
Followers
569
Following
63
Media
246
Statuses
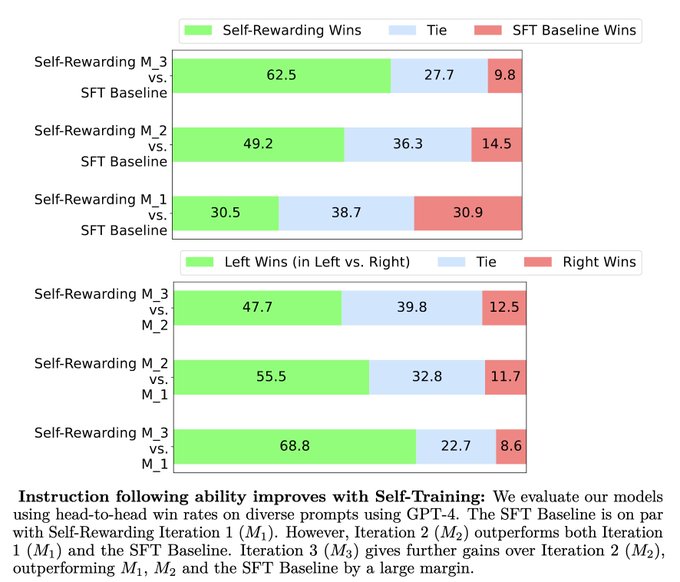
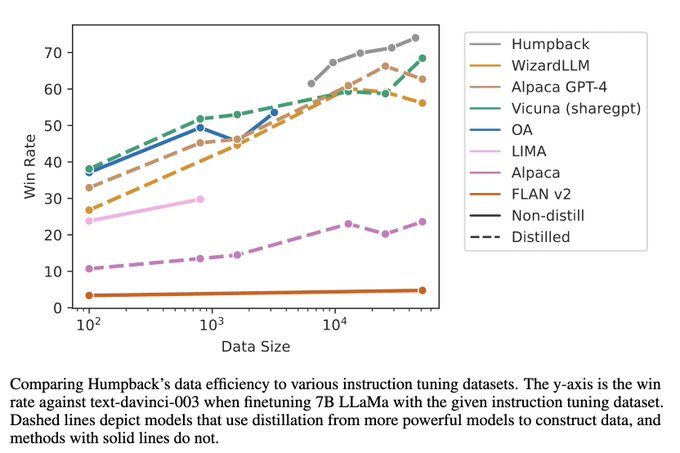
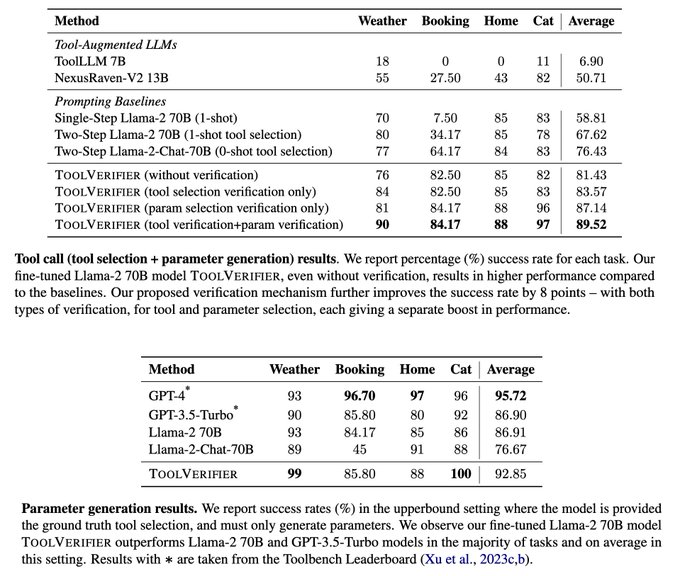
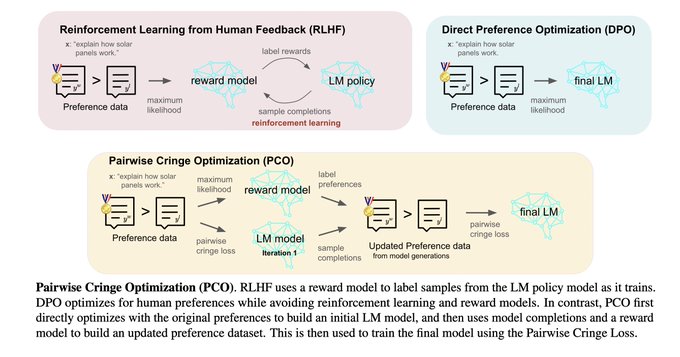
Research @MetaAI +NYU. Pretrain+FT: NLP from Scratch (2011). Multilayer attention+position embed+LLM: MemNets (2015). Recent (2023+):Sys 2 Attn, Self-Rewarding..
Don't wanna be here?
Send us removal request.