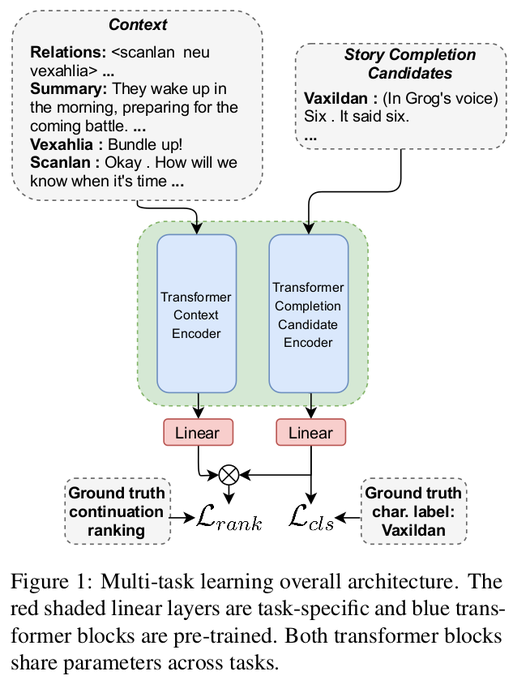
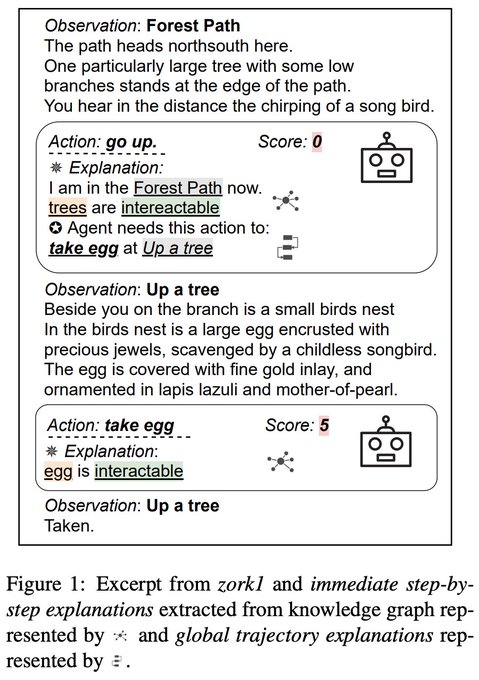
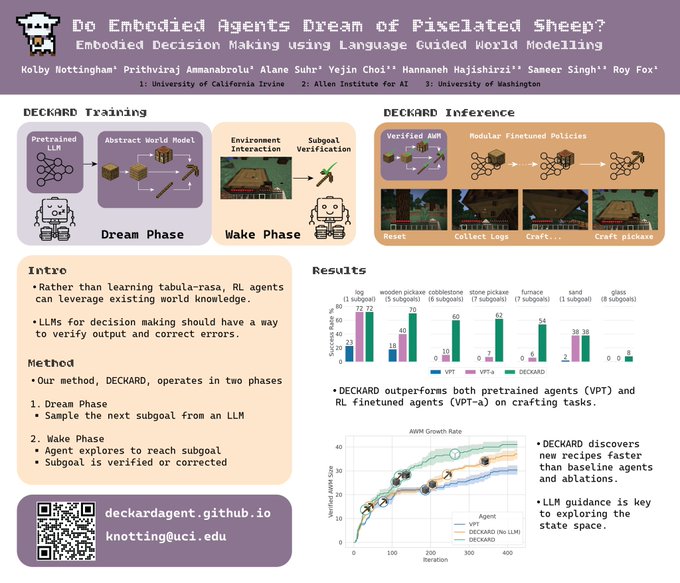
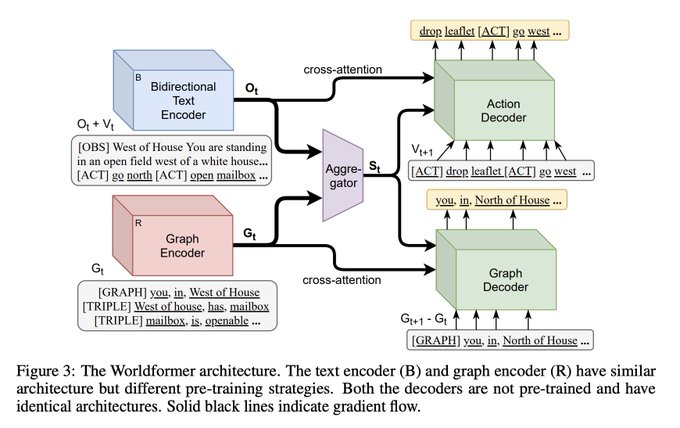
Prithviraj (Raj) Ammanabrolu
@rajammanabrolu
4,704
Followers
520
Following
324
Media
2,404
Statuses
Interactive & grounded AI, RL, NLP. Assistant Prof @UCSanDiego . Research Scientist @DbrxMosaicAI . Prev: @allen_ai , @GeorgiaTech
Don't wanna be here?
Send us removal request.