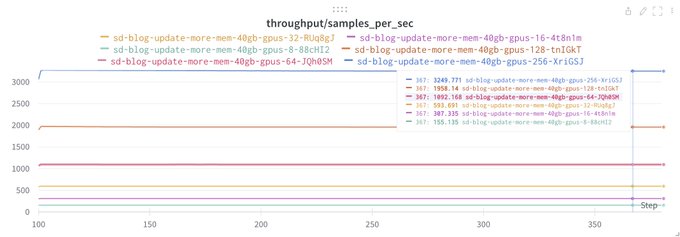
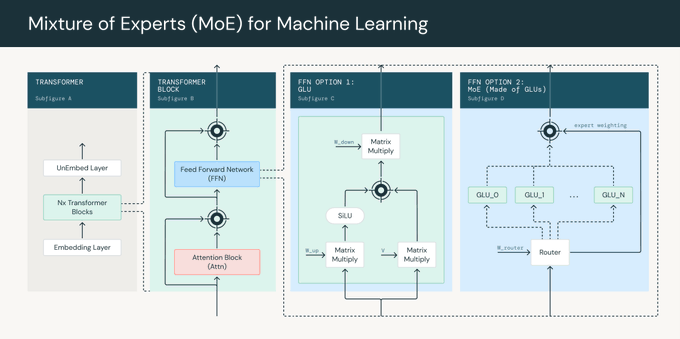
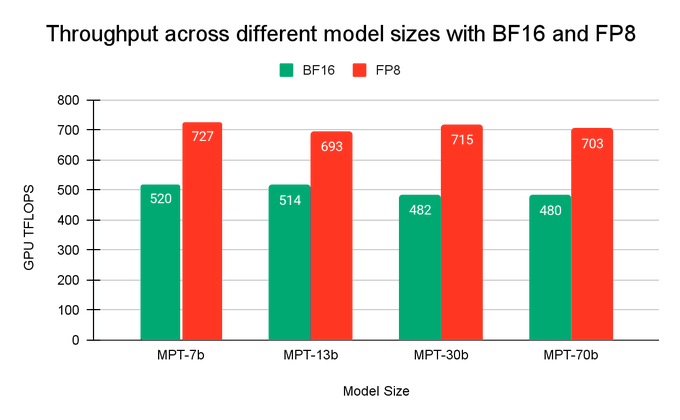
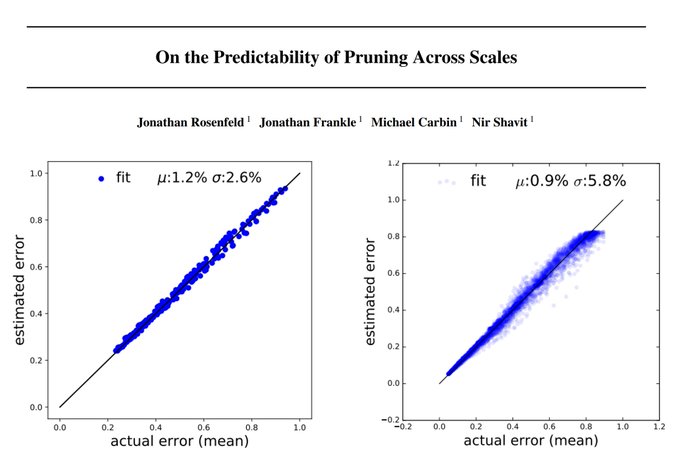
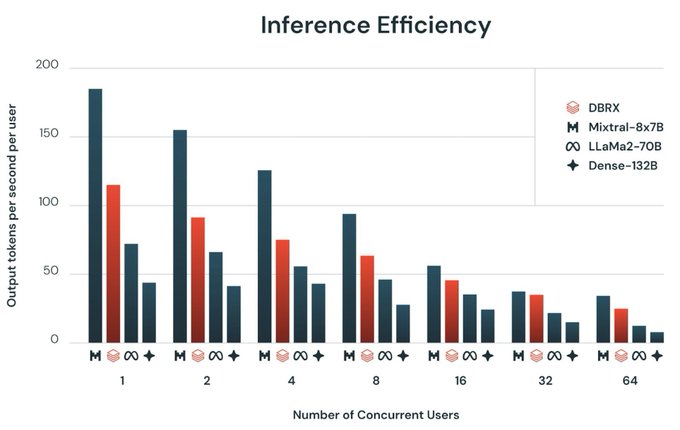
Jonathan Frankle
@jefrankle
16,152
Followers
685
Following
238
Media
3,152
Statuses
Chief AI Scientist @Databricks via MosaicML. Leading @DbrxMosaicAI . PhD @MIT_CSAIL . BS/MS @PrincetonCS . DC area native. Making AI efficient for everyone.
Don't wanna be here?
Send us removal request.