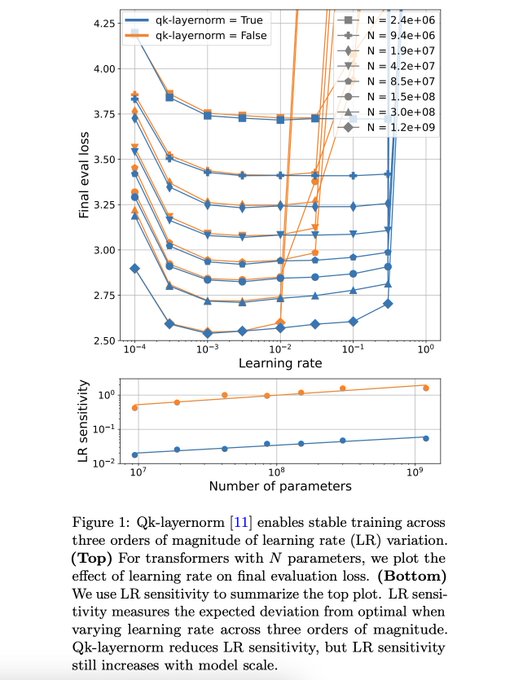
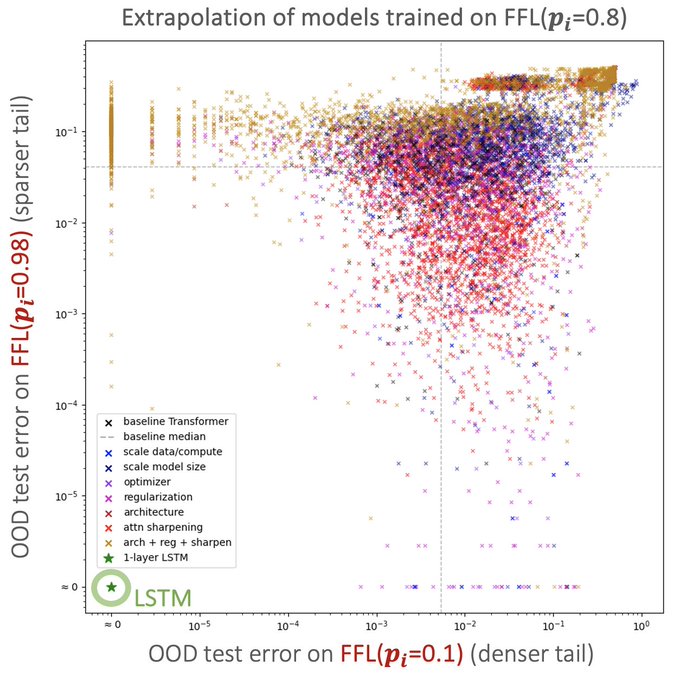
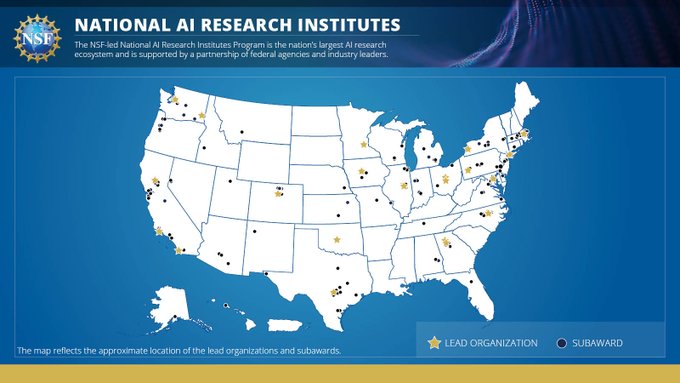
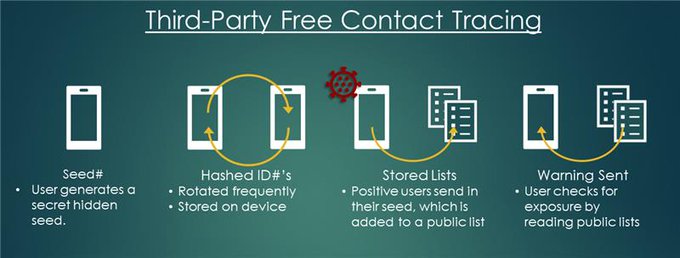
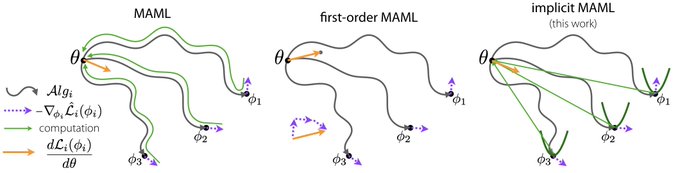
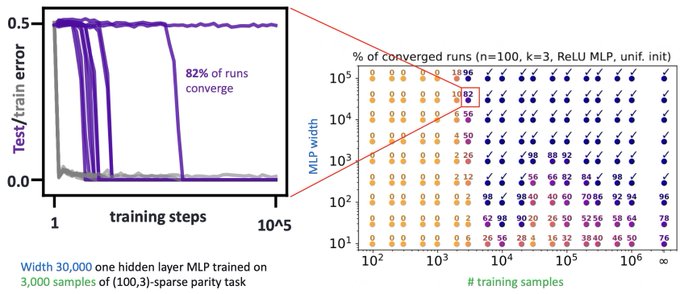
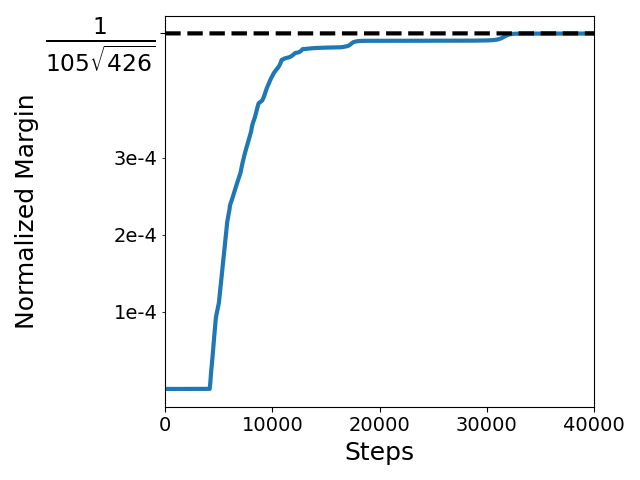
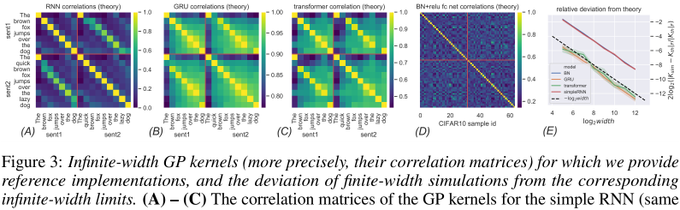
Sham Kakade
@ShamKakade6
11,611
Followers
383
Following
7
Media
311
Statuses
Harvard Professor. Full stack ML and AI. Co-director of the Kempner Institute for the Study of Artificial and Natural Intelligence.
Joined December 2018
Don't wanna be here?
Send us removal request.