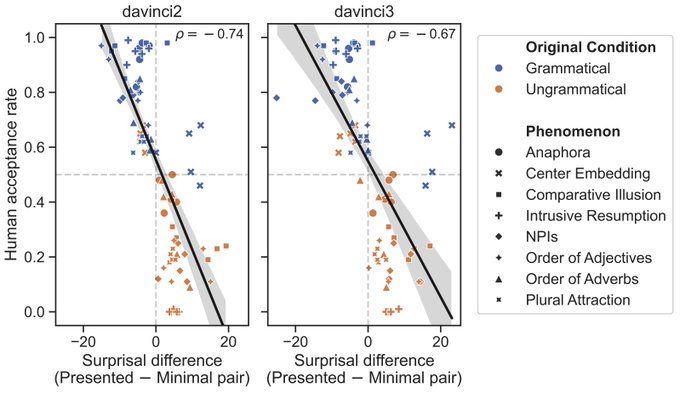
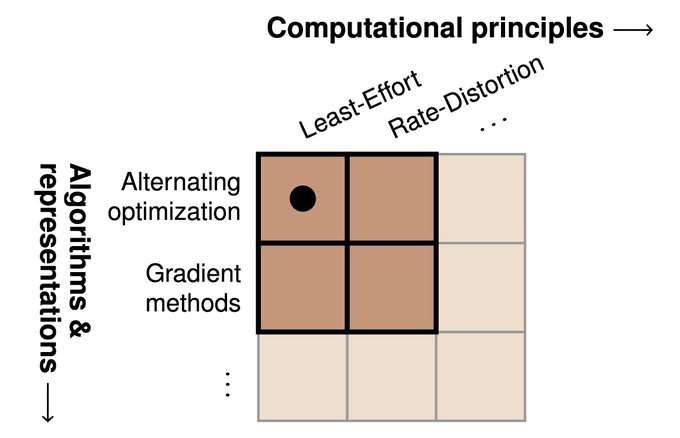
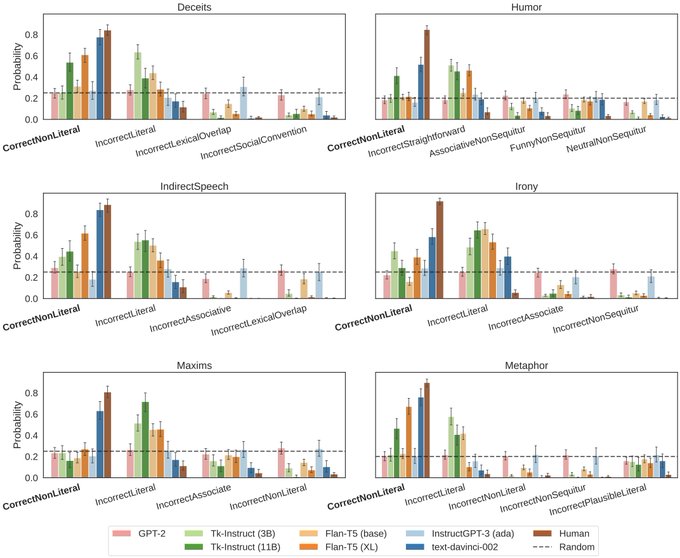
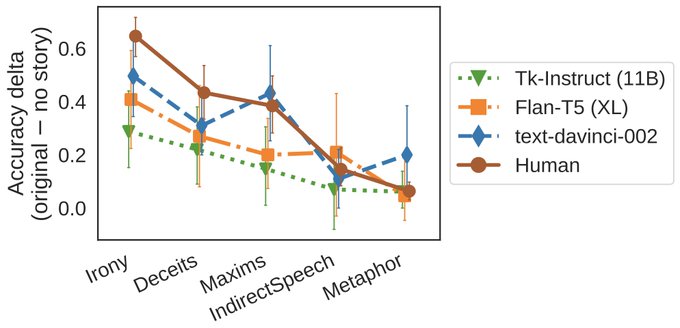
Jennifer Hu
@_jennhu
1,513
Followers
100
Following
12
Media
78
Statuses
Research Fellow at @Harvard and incoming Asst Prof at @JohnsHopkins interested in language, computation, and cognition. @jennhu .bsky.social
Don't wanna be here?
Send us removal request.