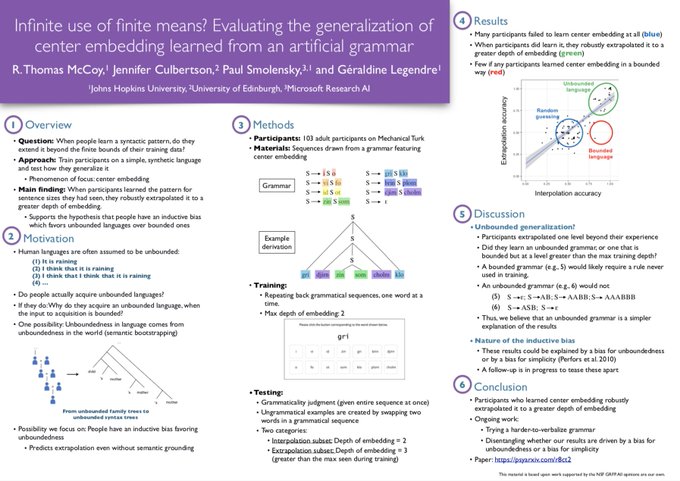
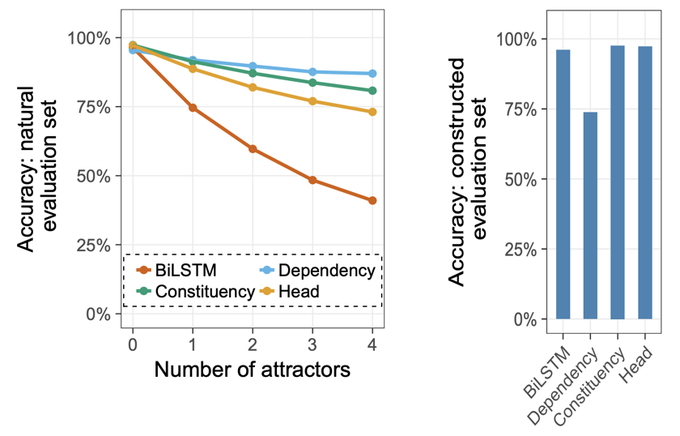
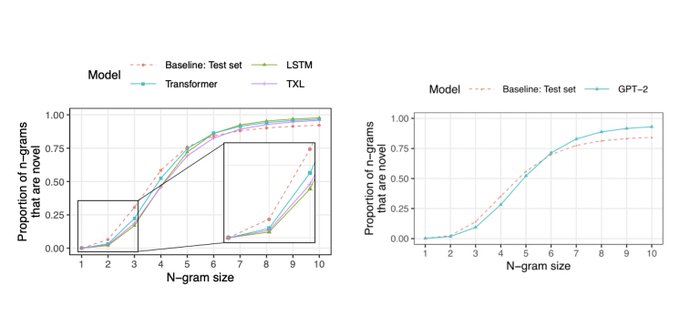
Tom McCoy
@RTomMcCoy
3,101
Followers
491
Following
147
Media
1,447
Statuses
Assistant professor @YaleLinguistics . Studying computational linguistics, cognitive science, and AI. He/him.
Don't wanna be here?
Send us removal request.