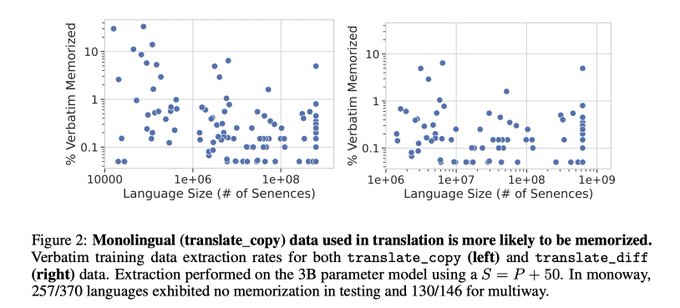
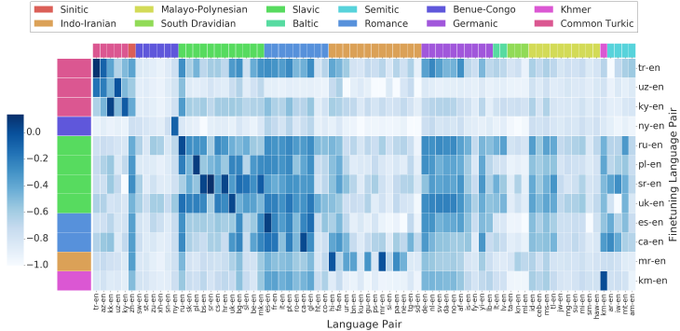
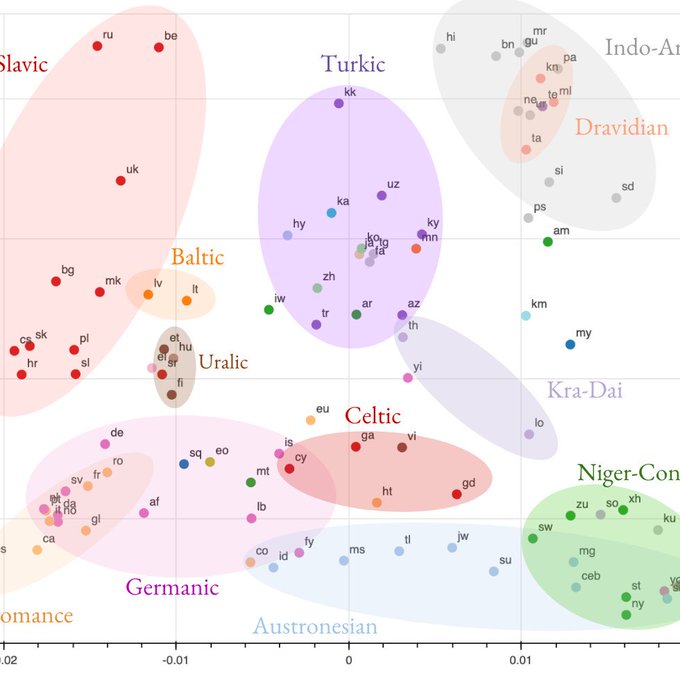
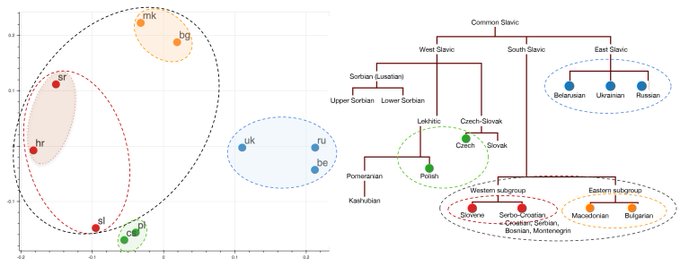
Sneha Kudugunta
@snehaark
2,262
Followers
749
Following
23
Media
497
Statuses
addicted to tpus @GoogleDeepMind @uwcse | varying proportions of AI and mediocre jokes (not mutually exclusive) | she/her/hers
Don't wanna be here?
Send us removal request.