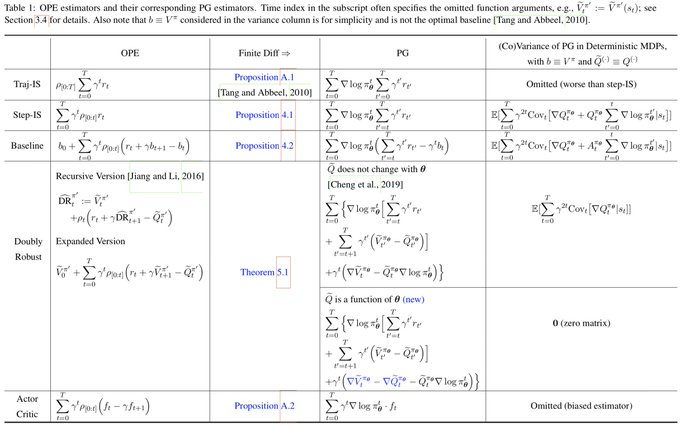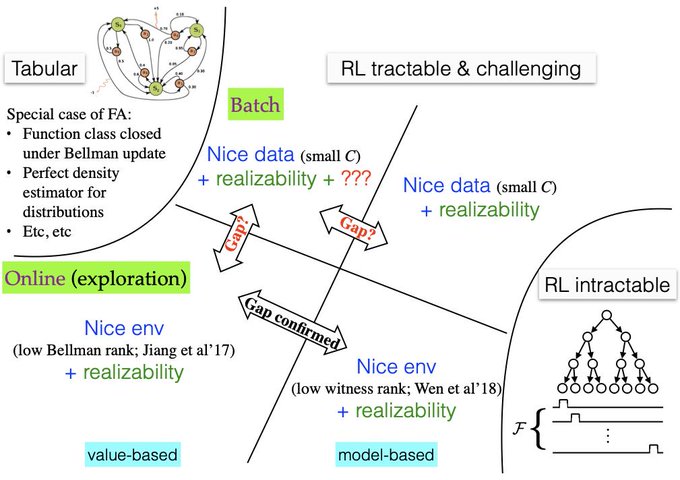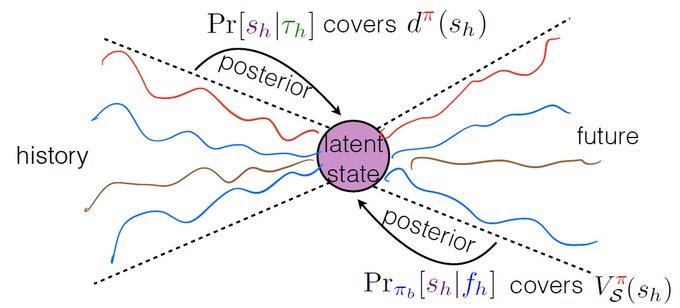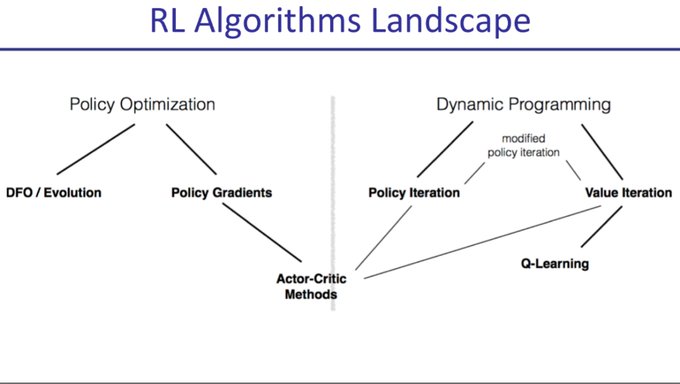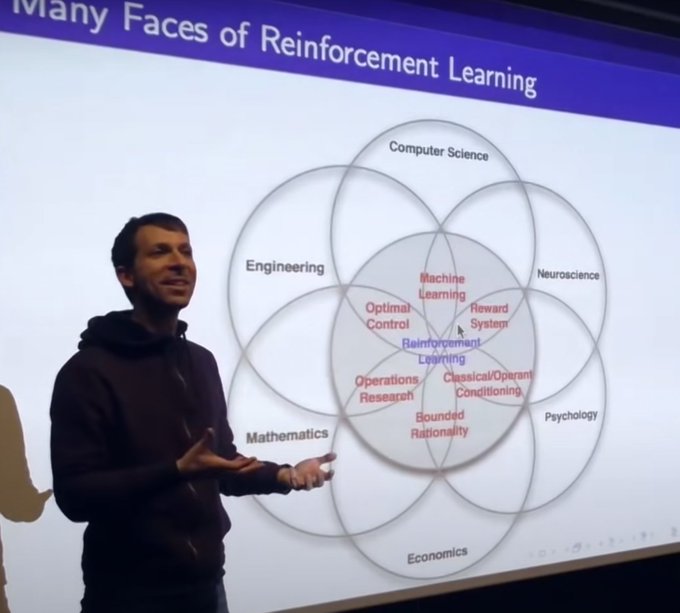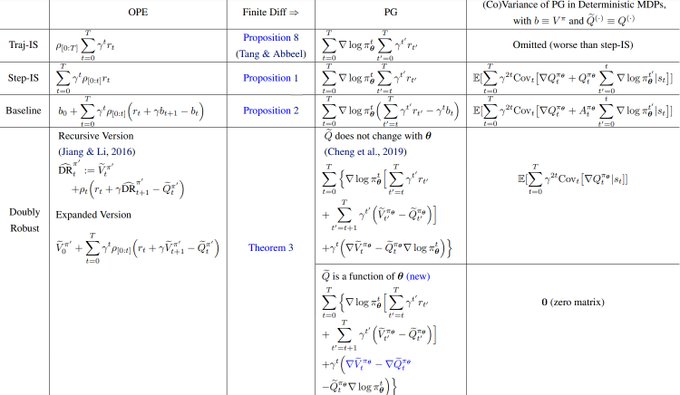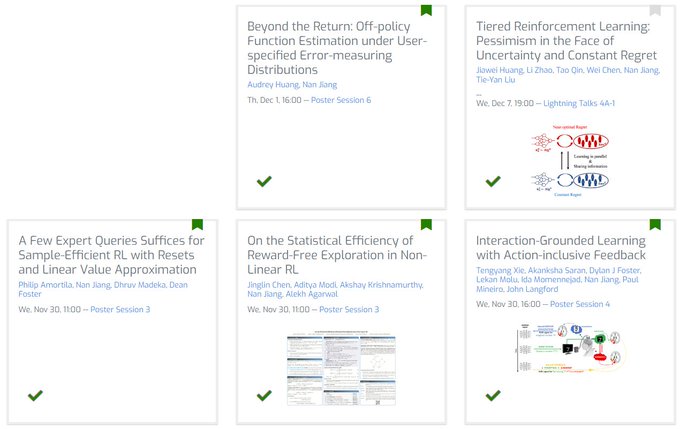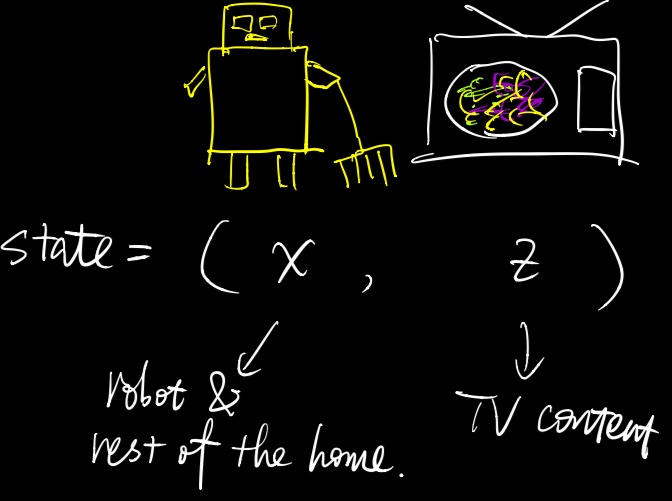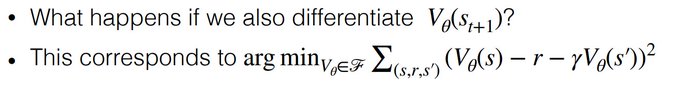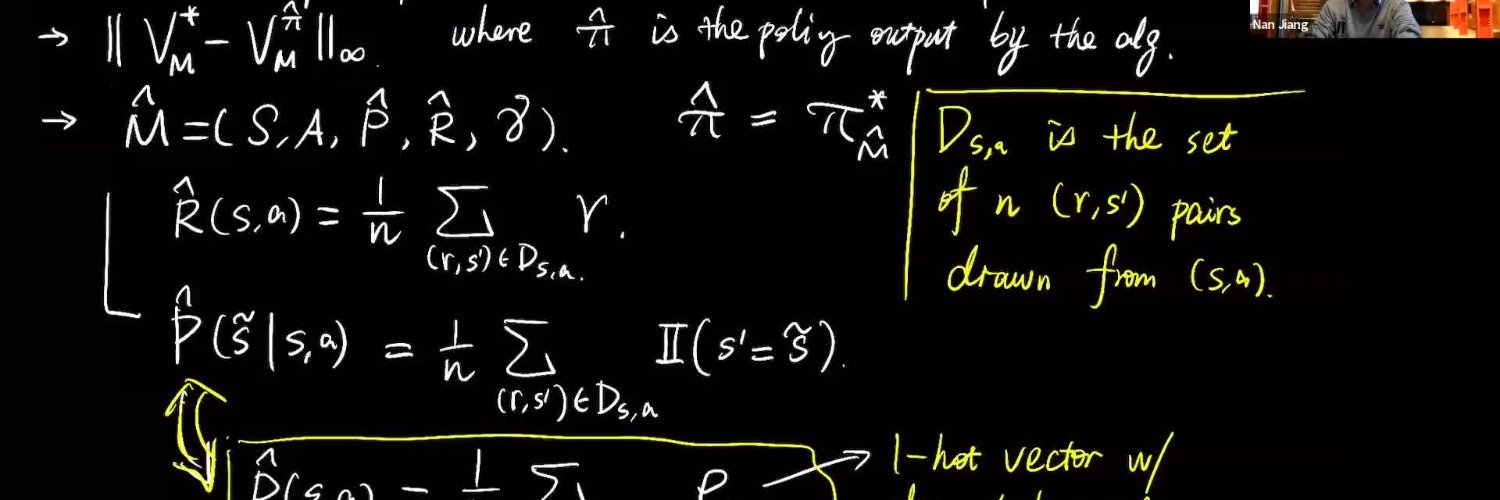

Nan Jiang
@nanjiang_cs
6,926
Followers
73
Following
110
Media
1,888
Statuses
machine learning researcher, with focus on reinforcement learning. asst prof @ uiuc cs. Course on RL theory (w/ videos):
Joined November 2017
Don't wanna be here?
Send us removal request.