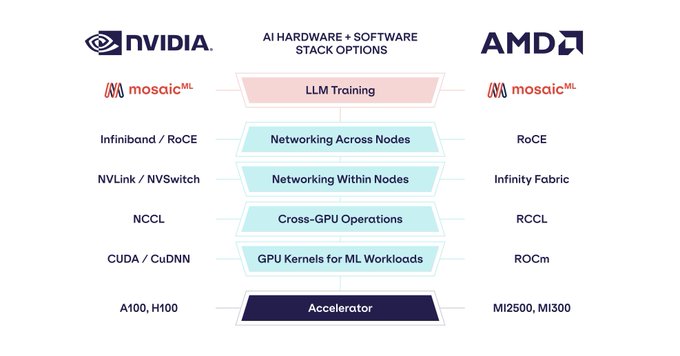
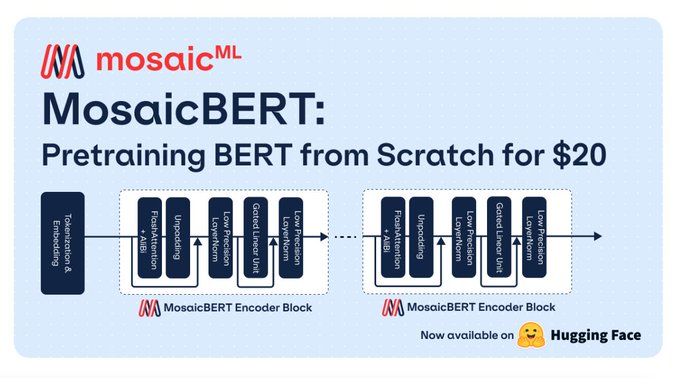
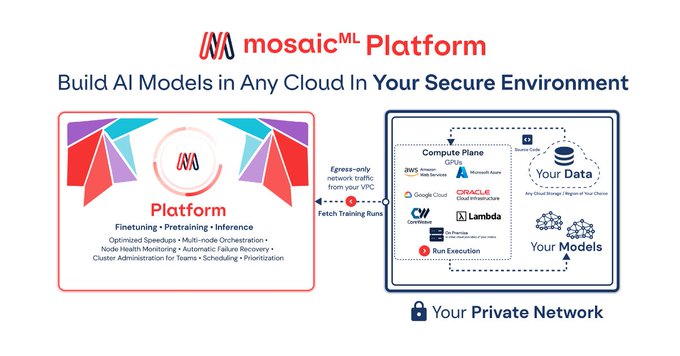
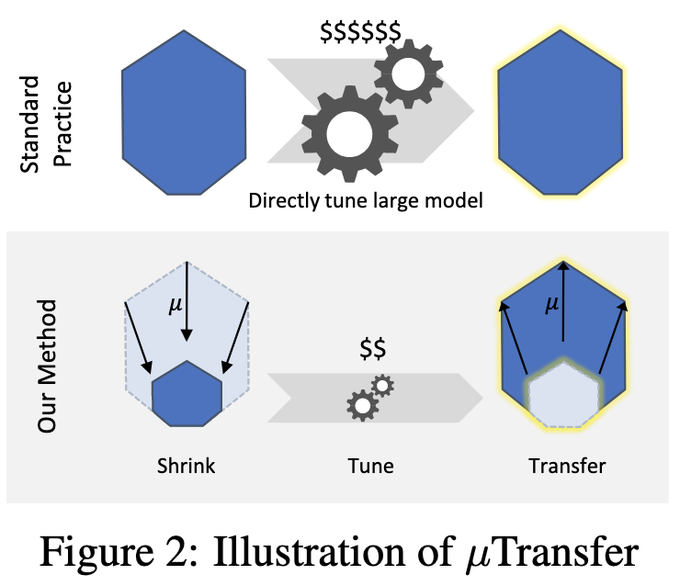
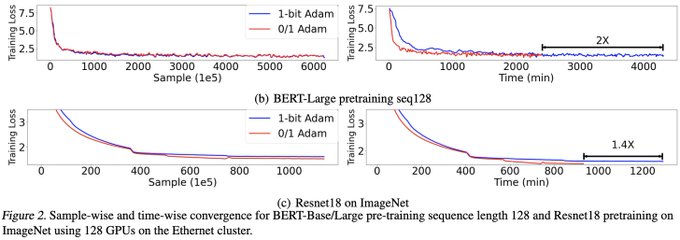
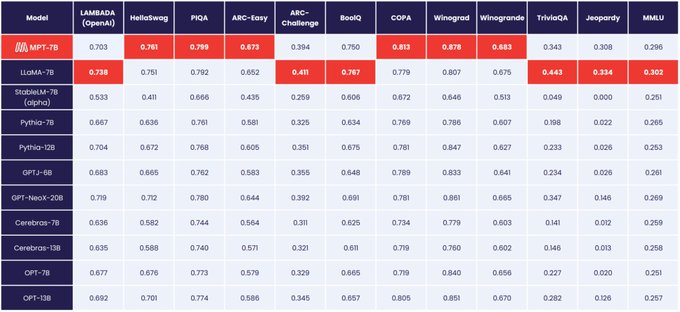
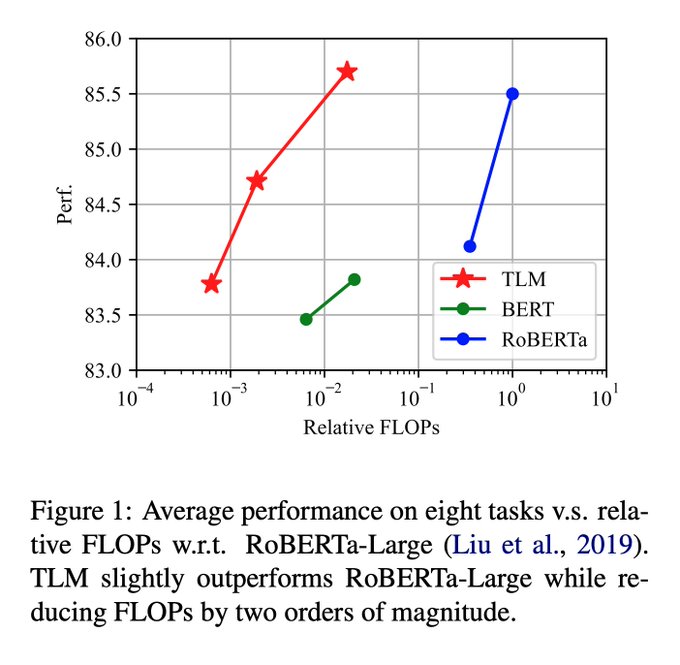
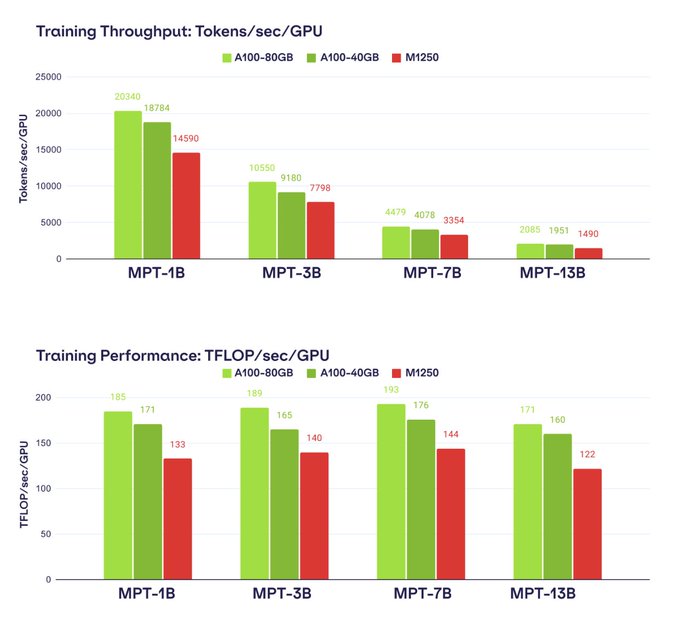
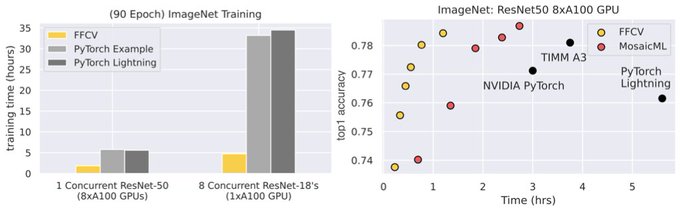
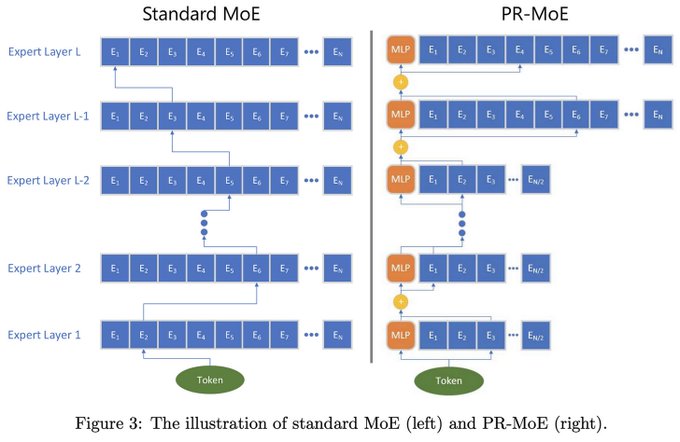
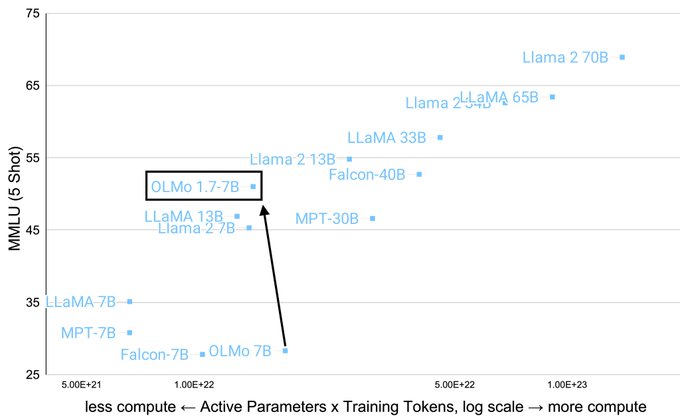
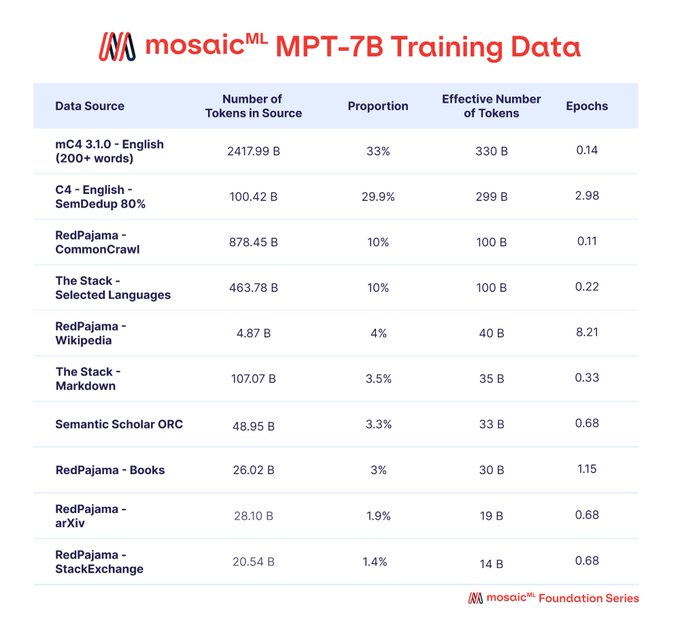
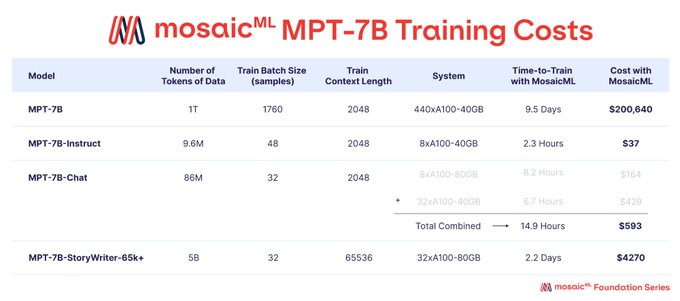
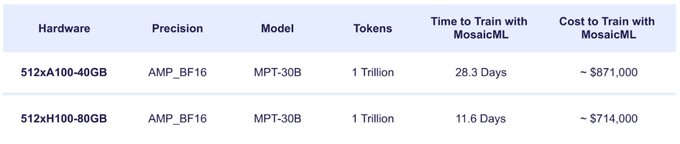
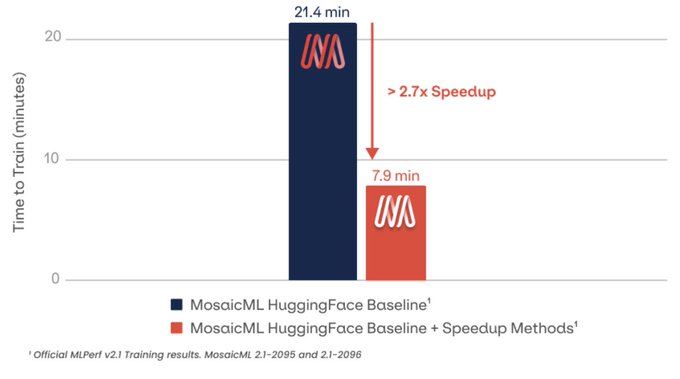
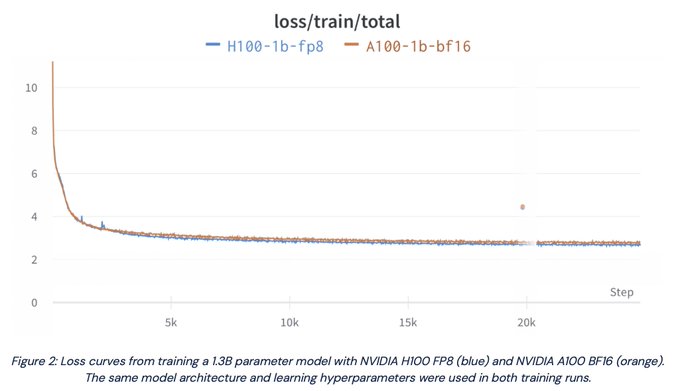
Databricks Mosaic Research
@DbrxMosaicAI
30,409
Followers
116
Following
316
Media
977
Statuses
We remove the barriers to state-of-the-art generative AI model development and make data + AI available to all.
Don't wanna be here?
Send us removal request.