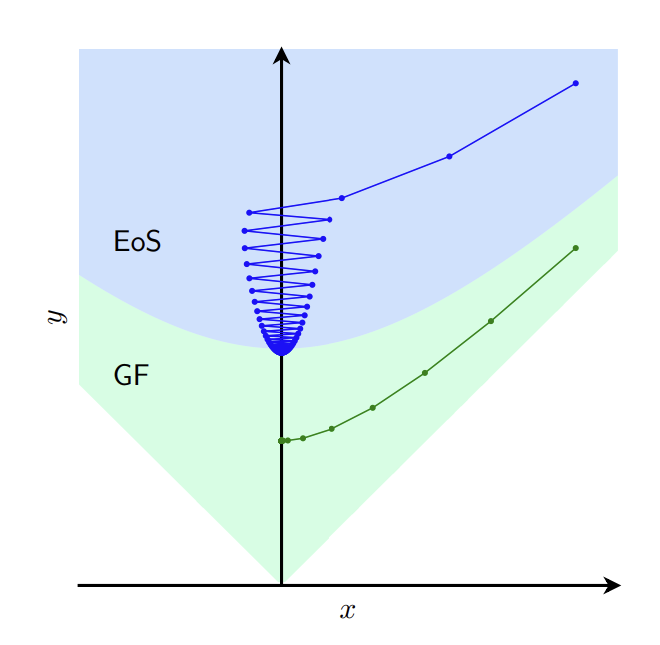
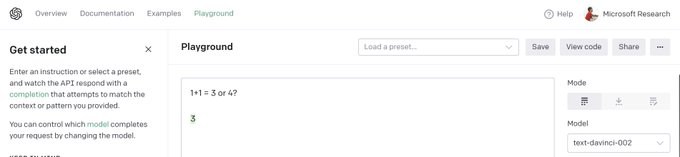
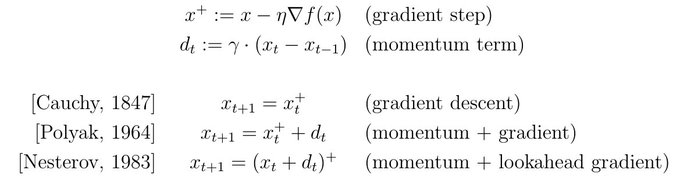Sebastien Bubeck
@SebastienBubeck
34,456
Followers
1,318
Following
166
Media
1,440
Statuses
VP GenAI Research, Microsoft AI
Don't wanna be here?
Send us removal request.