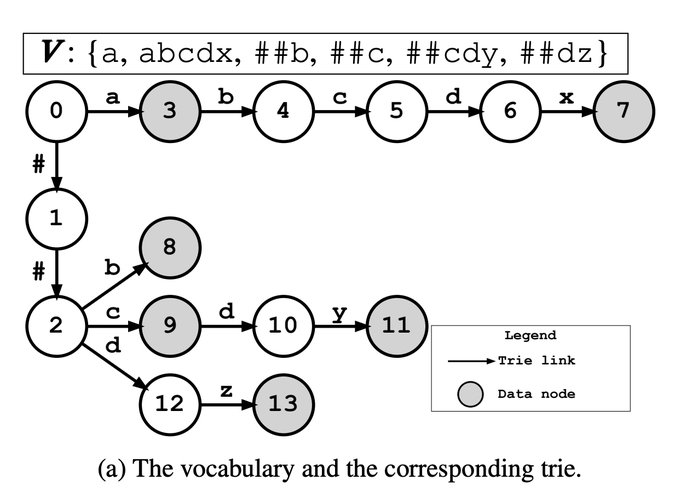
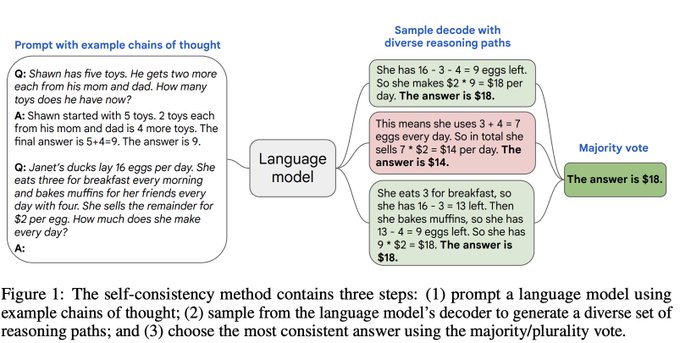
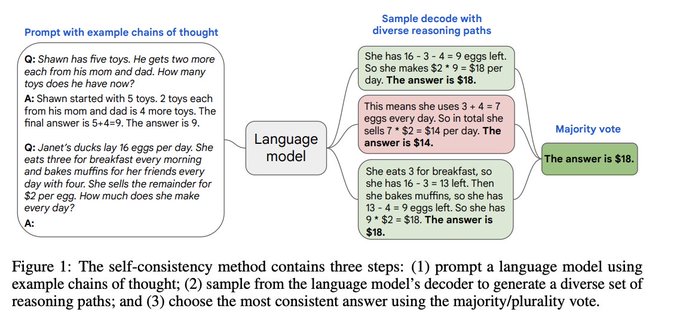
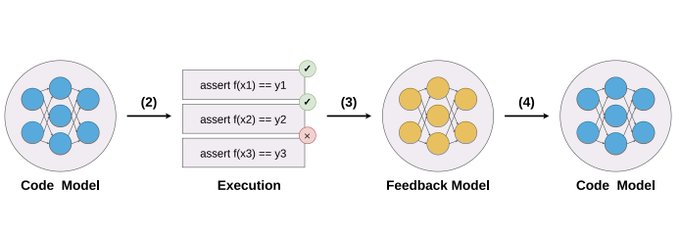
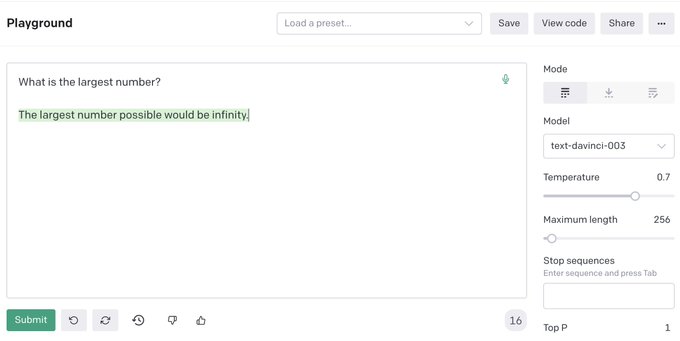
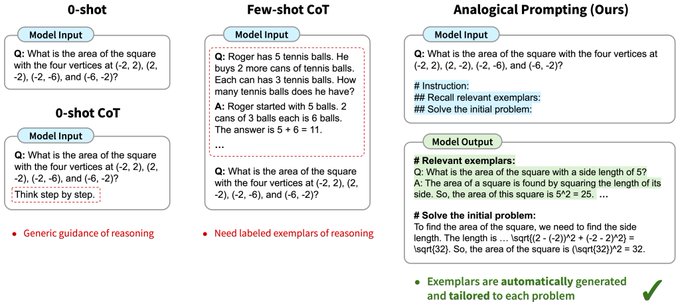
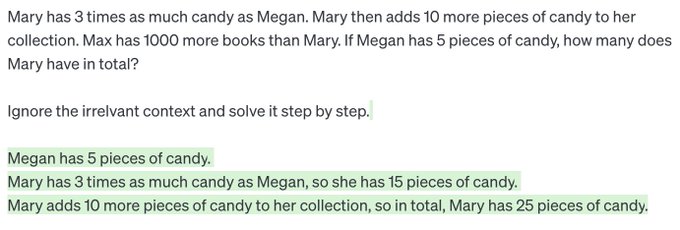Denny Zhou
@denny_zhou
9,084
Followers
432
Following
59
Media
589
Statuses
@GoogleDeepMind founder & lead of Reasoning Team. Build LLMs to reason. Opinions my own.
Joined August 2013
Don't wanna be here?
Send us removal request.