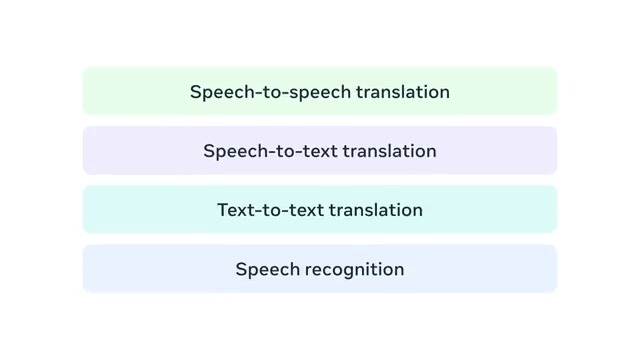
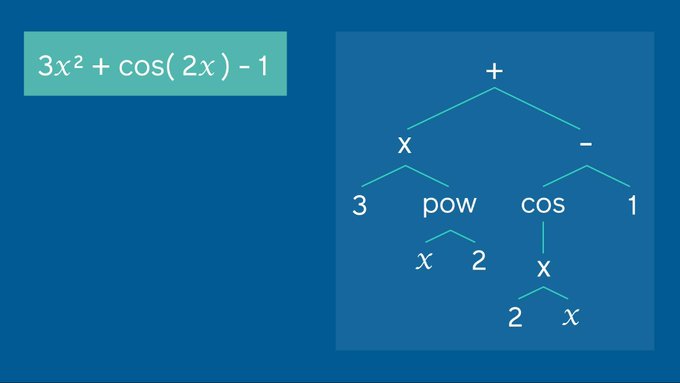
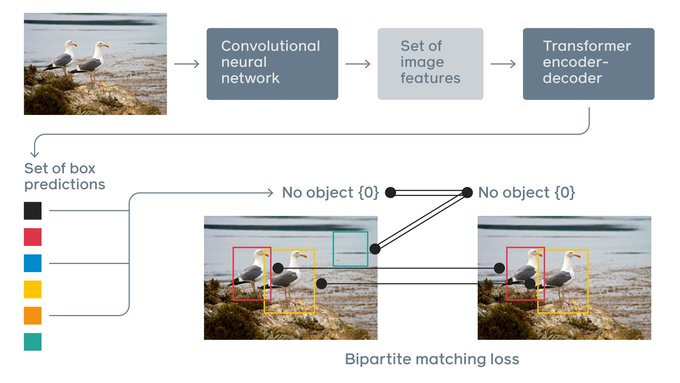
AI at Meta
@AIatMeta
536,818
Followers
257
Following
830
Media
1,969
Statuses
Together with the AI community, we are pushing the boundaries of what’s possible through open science to create a more connected world.
Joined August 2018
Don't wanna be here?
Send us removal request.