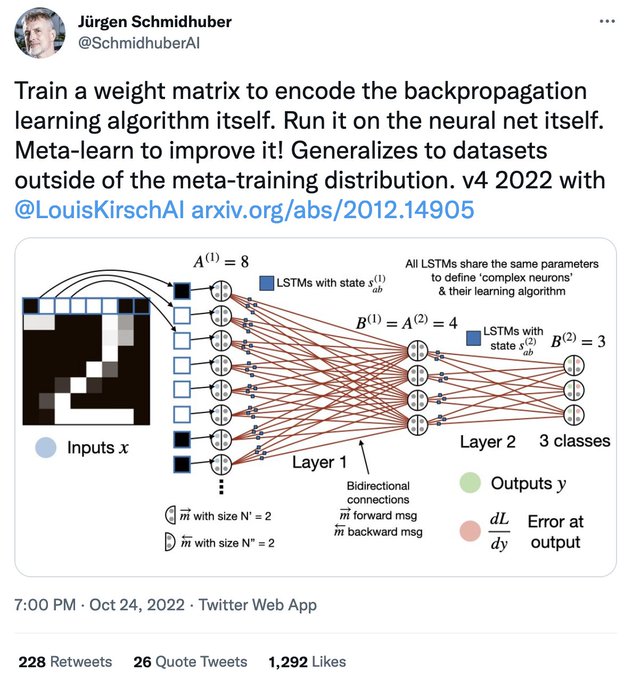
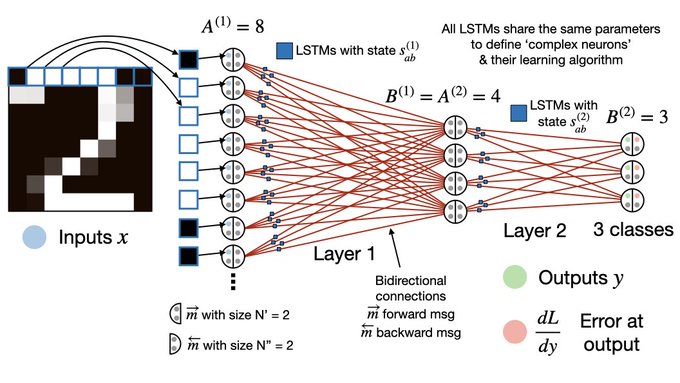
Jürgen Schmidhuber
@SchmidhuberAI
106,529
Followers
0
Following
35
Media
64
Statuses
Invented principles of meta-learning (1987), GANs (1990), Transformers (1991), very deep learning (1991), etc. Our AI is used many billions of times every day.
Don't wanna be here?
Send us removal request.