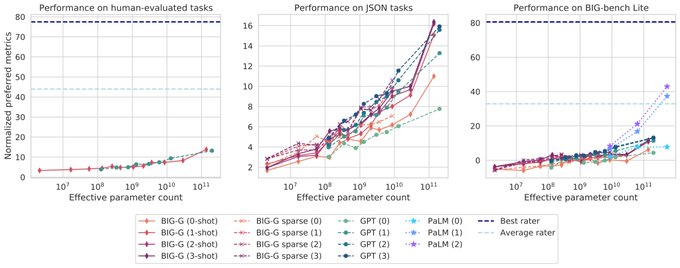
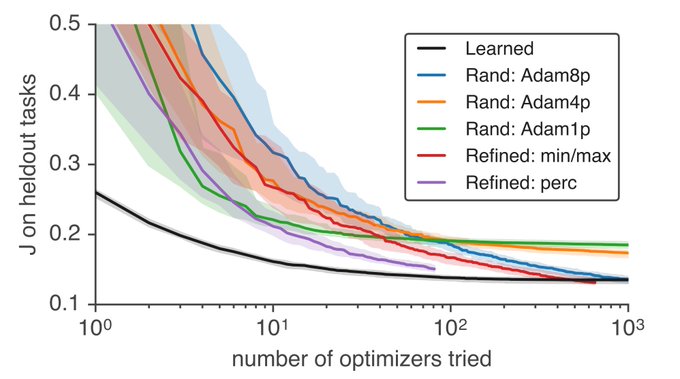
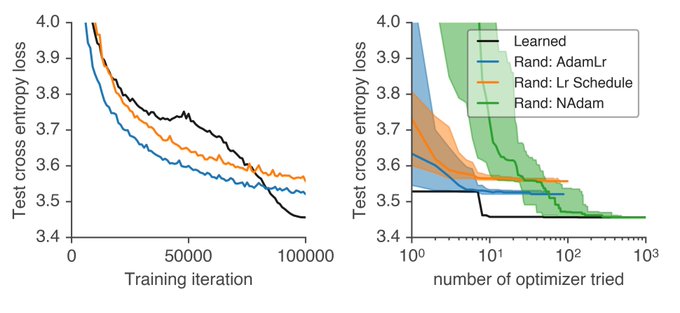
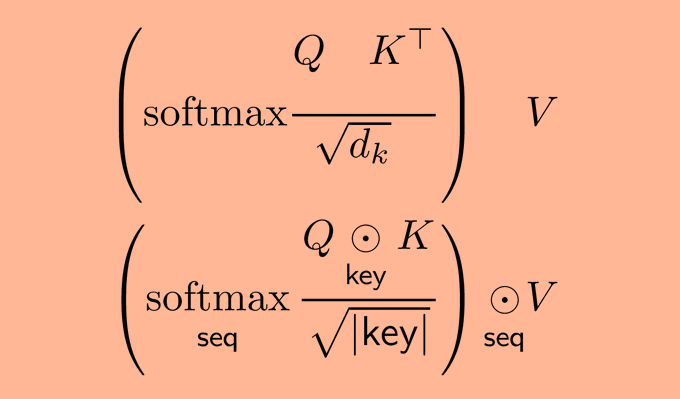Jascha Sohl-Dickstein
@jaschasd
18,849
Followers
632
Following
75
Media
540
Statuses
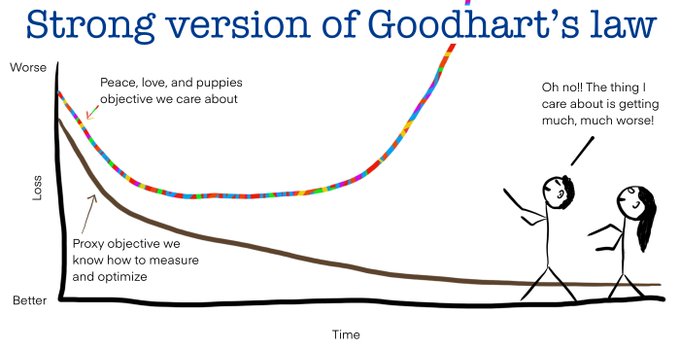
Member of the technical staff @ Anthropic. Most (in)famous for inventing diffusion models. AI + physics + neuroscience + dynamics.
Don't wanna be here?
Send us removal request.