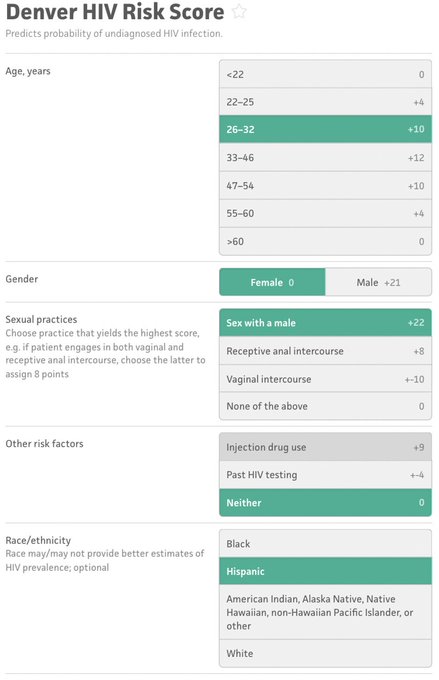
Berk Ustun
@berkustun
2,912
Followers
974
Following
32
Media
759
Statuses
Assistant Prof @HDSIUCSD . I work on fairness and interpretability in ML. Previously @GoogleAI @Harvard @MIT @UCBerkeley 🇨🇭🇹🇷
Don't wanna be here?
Send us removal request.