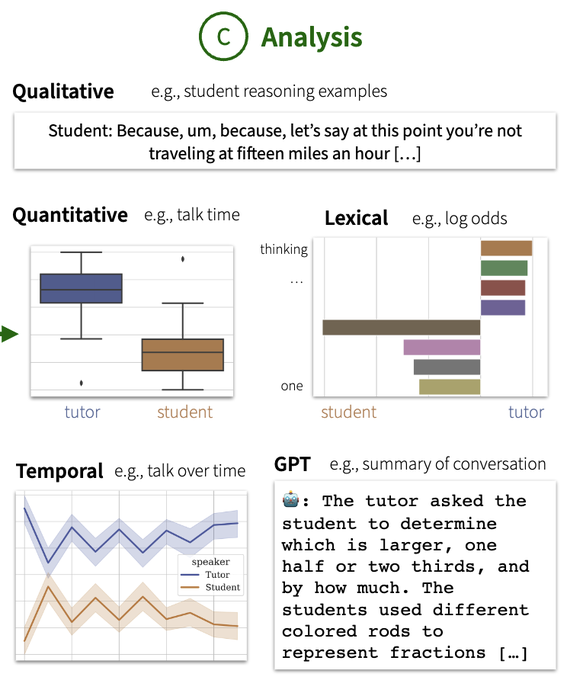
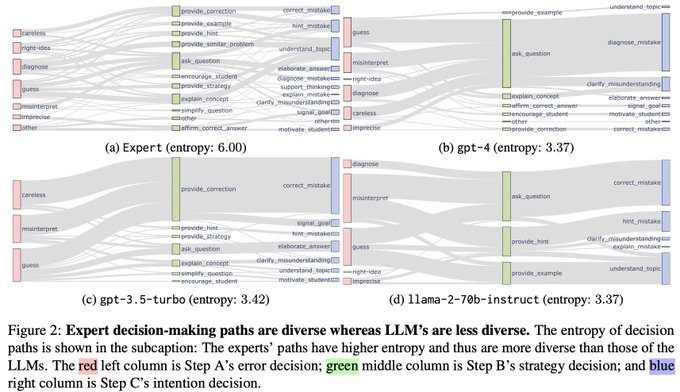
Rose
@rose_e_wang
1,564
Followers
242
Following
66
Media
268
Statuses
NLP & Education @stanfordnlp 🌲 Prev: 2020 MIT 🦫, Google Brain 🧠, Google Brain Robotics 🤖
Joined January 2012
Don't wanna be here?
Send us removal request.