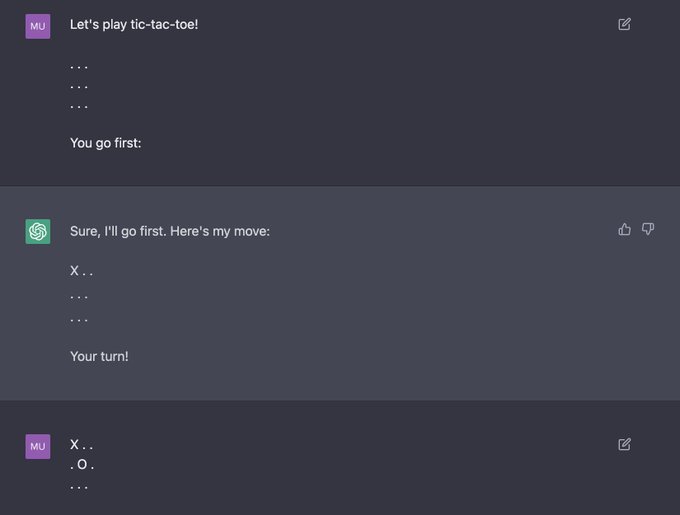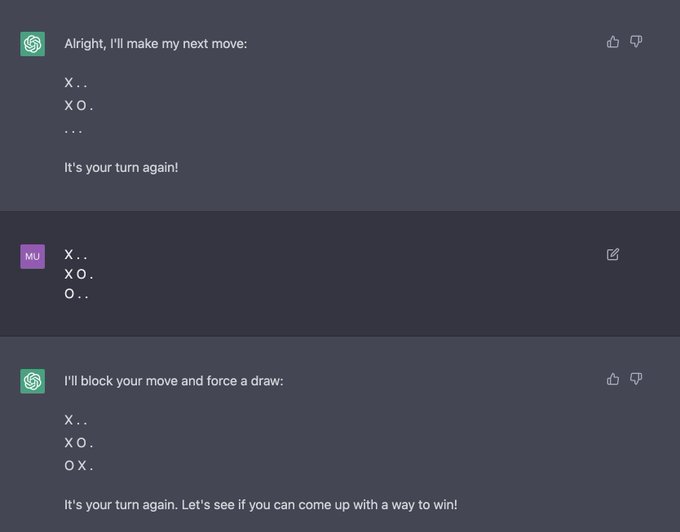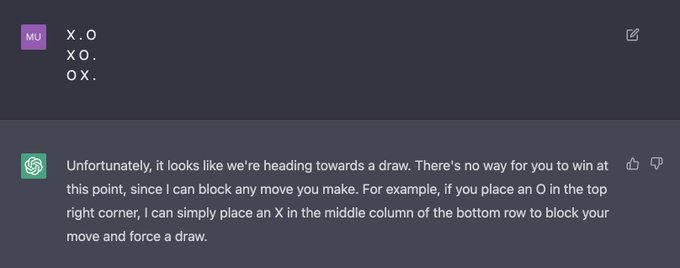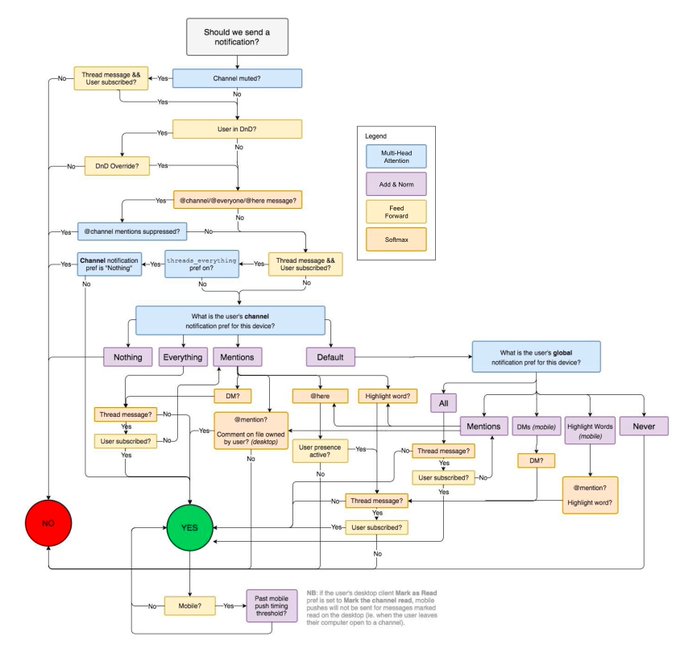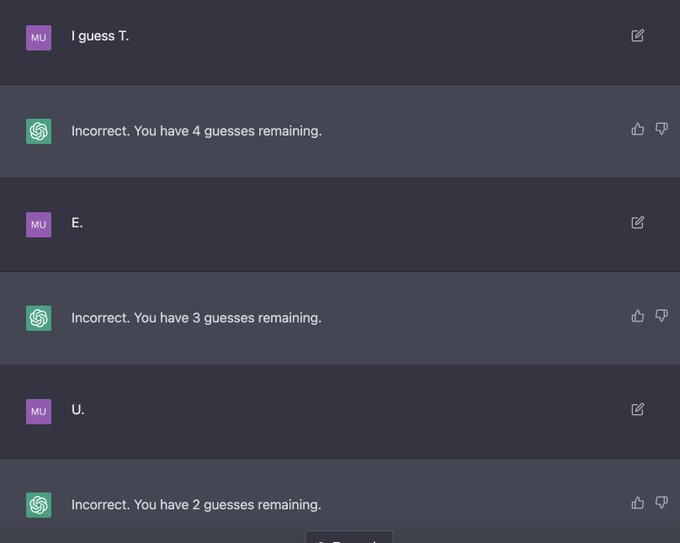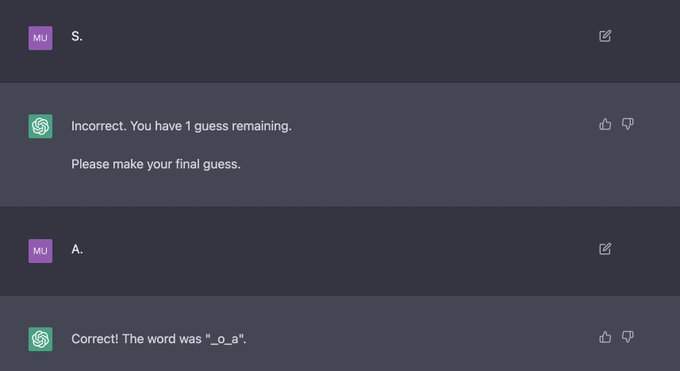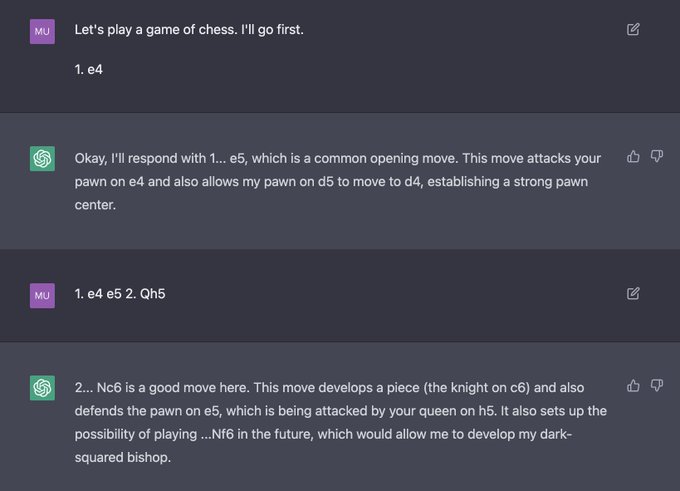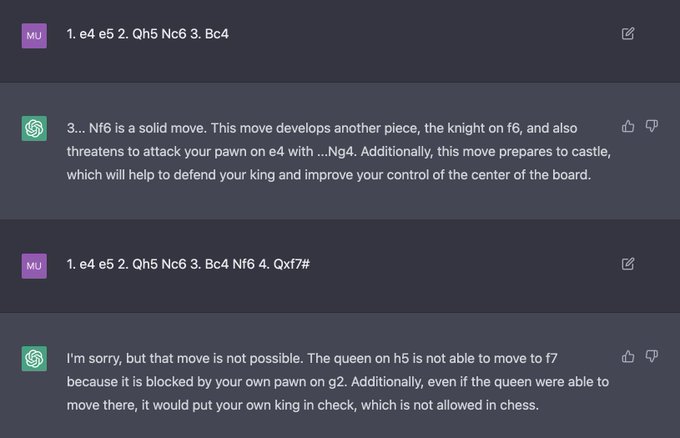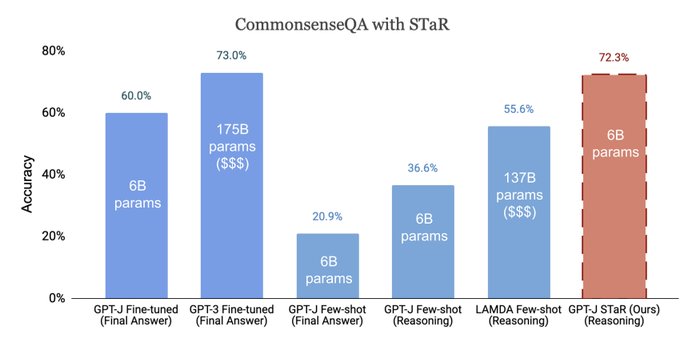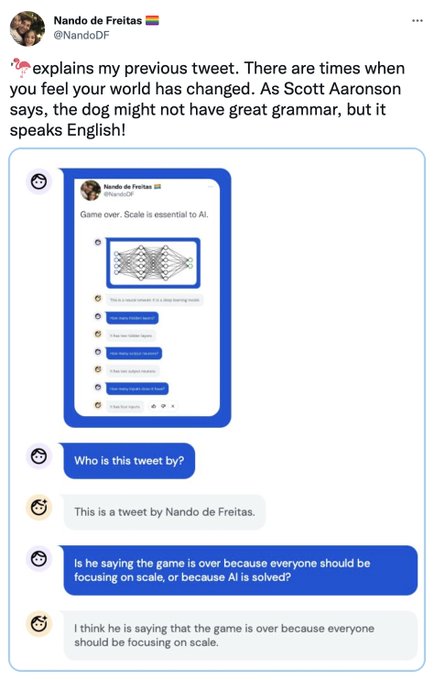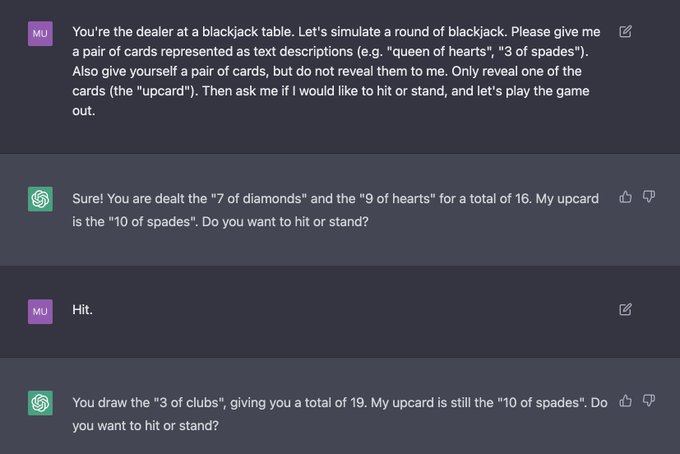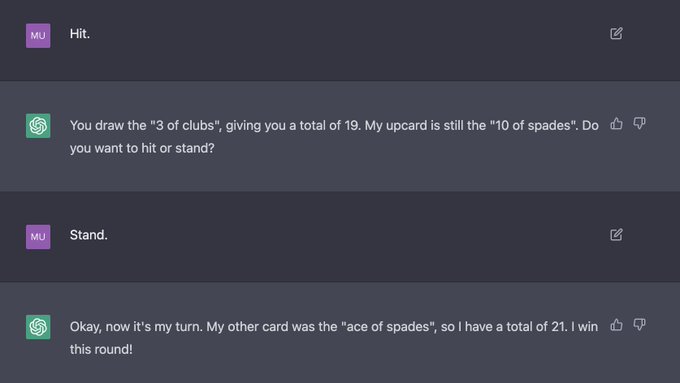

Jesse Mu
@jayelmnop
4,904
Followers
583
Following
120
Media
582
Statuses
Computational linguistics @AnthropicAI
Joined May 2010
Don't wanna be here?
Send us removal request.