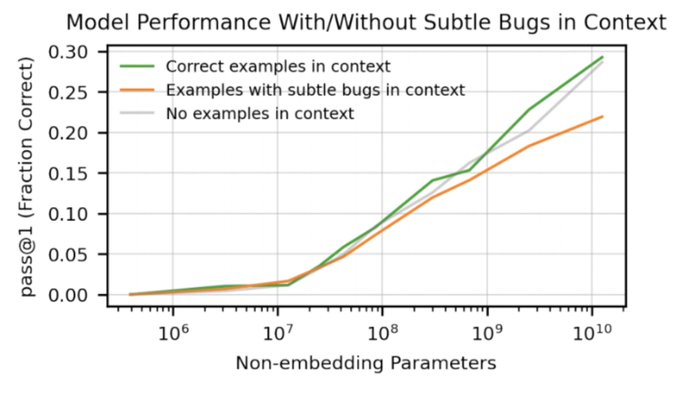
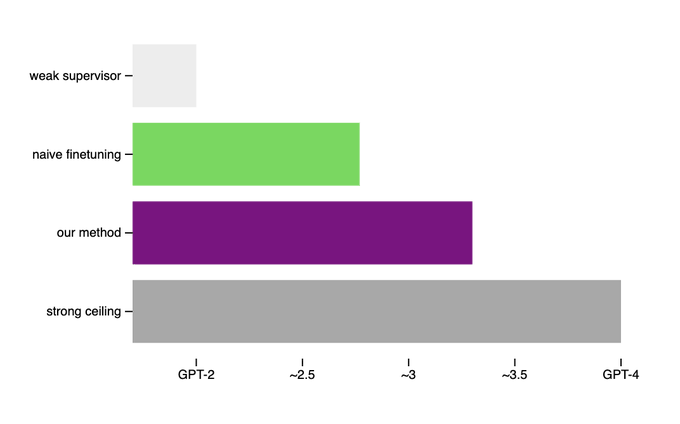Jan Leike
@janleike
43,920
Followers
322
Following
19
Media
532
Statuses
ML Researcher, co-leading Superalignment @OpenAI . Optimizing for a post-AGI future where humanity flourishes.
Don't wanna be here?
Send us removal request.