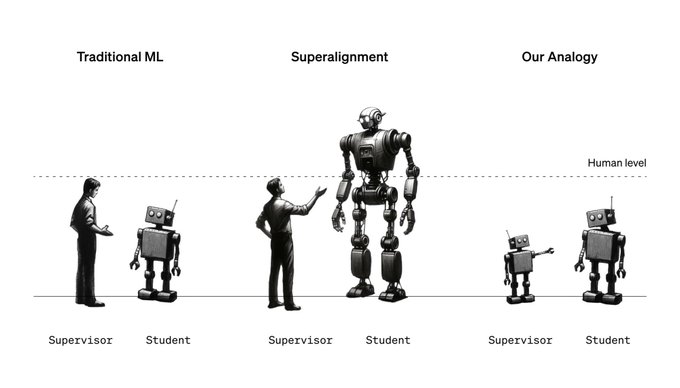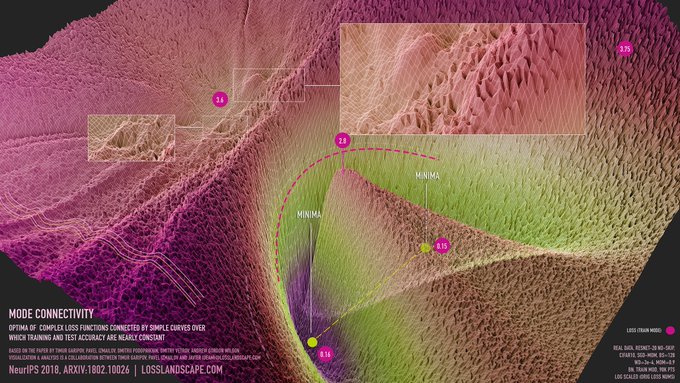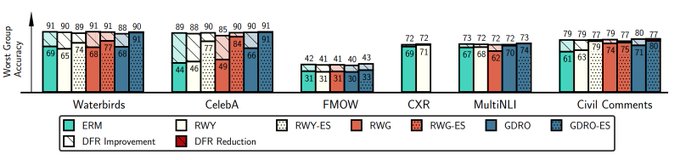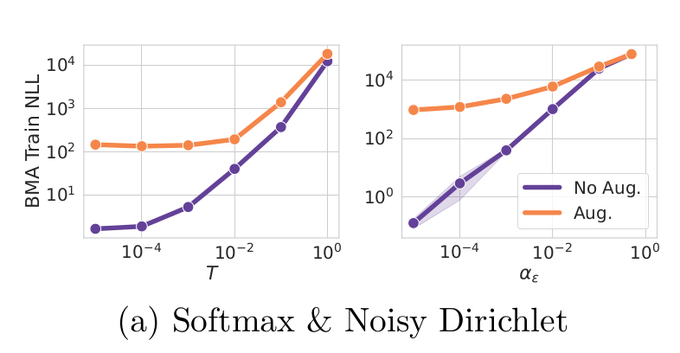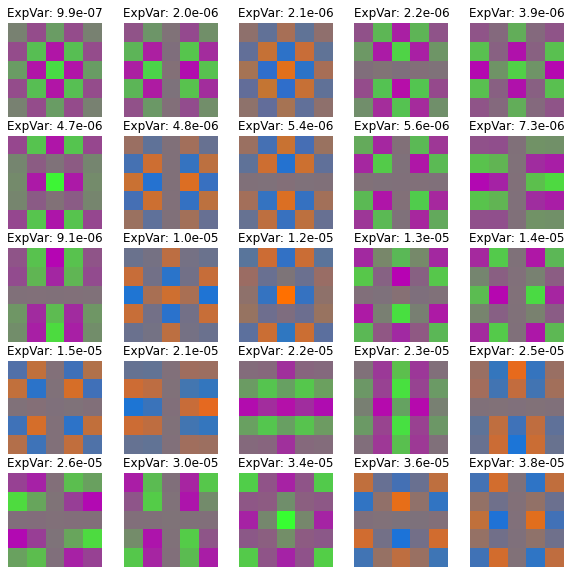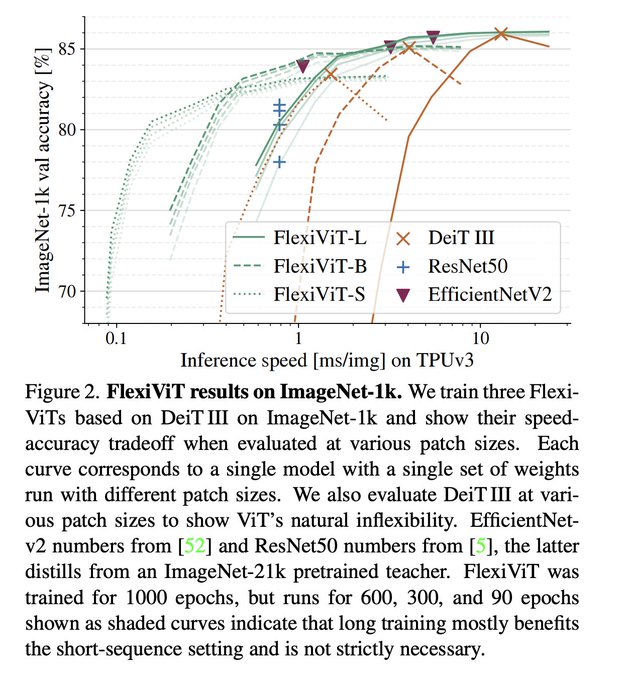

Pavel Izmailov
@Pavel_Izmailov
5,809
Followers
1,385
Following
51
Media
594
Statuses
Researcher Incoming Assistant Professor @nyuniversity 🏙️ Previously @OpenAI #StopWar 🇺🇦
Don't wanna be here?
Send us removal request.