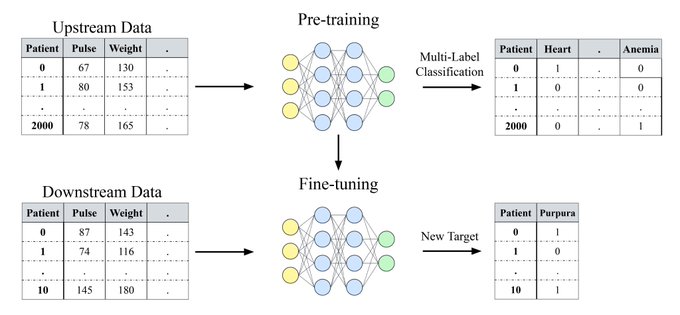
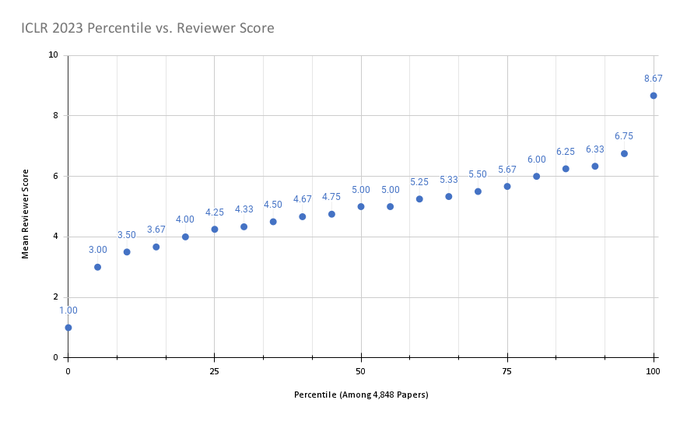
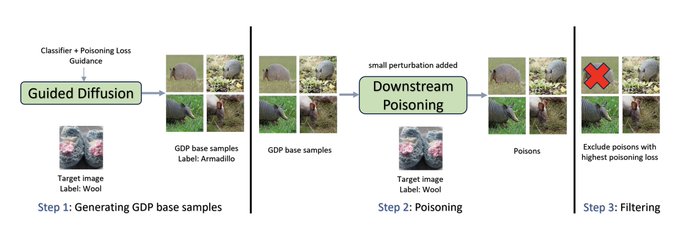
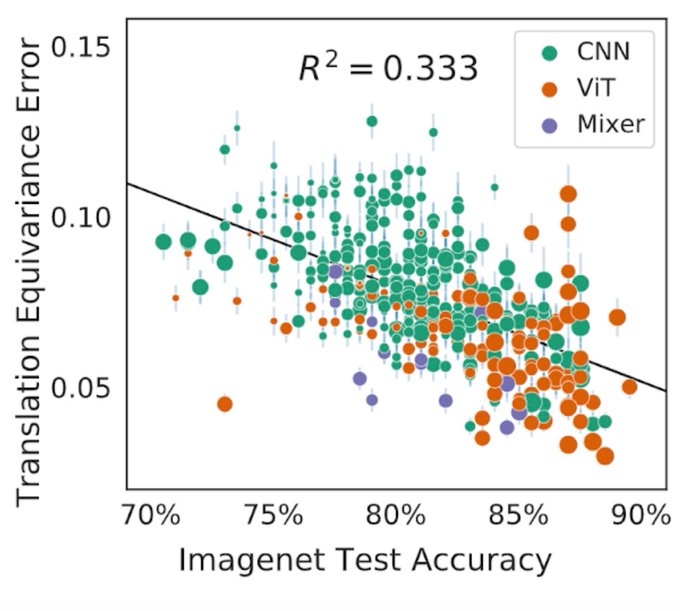
Micah Goldblum
@micahgoldblum
5,637
Followers
818
Following
41
Media
814
Statuses
🤖Postdoc at NYU with @ylecun / @andrewgwils . All things machine learning🤖 🚨Incoming prof at Columbia University🚨
Joined December 2014
Don't wanna be here?
Send us removal request.