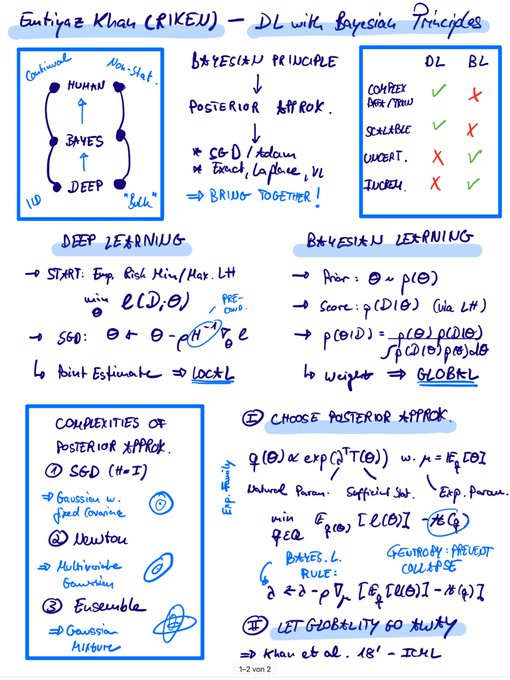
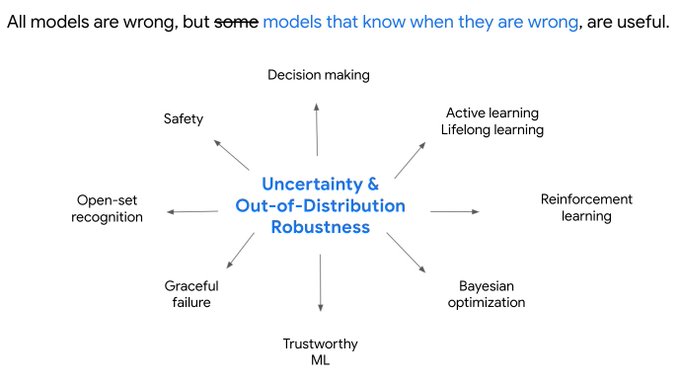
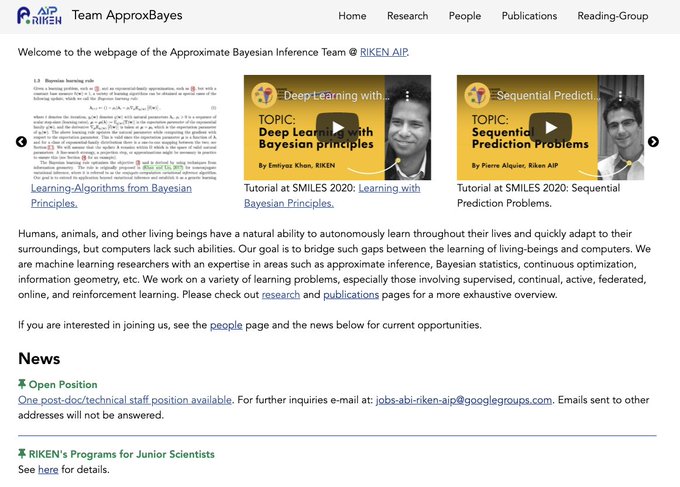
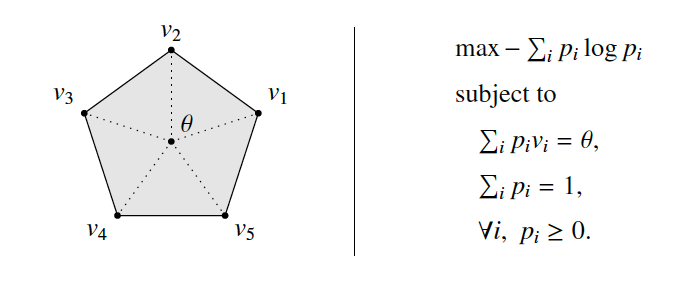
Emtiyaz Khan
@EmtiyazKhan
10,738
Followers
234
Following
382
Media
5,577
Statuses
Team leader at @RIKEN_AIP_EN . Opinions my own. Follow me at
Don't wanna be here?
Send us removal request.