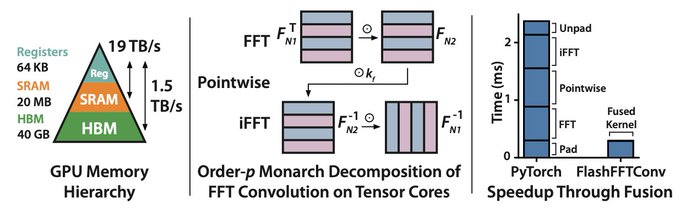
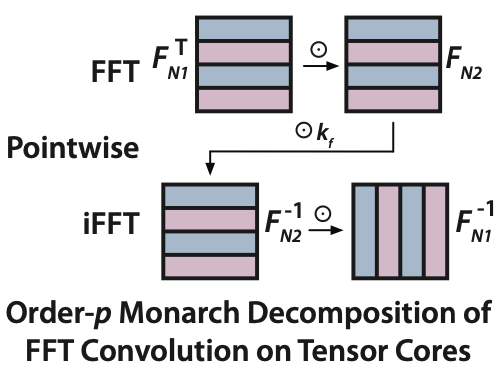
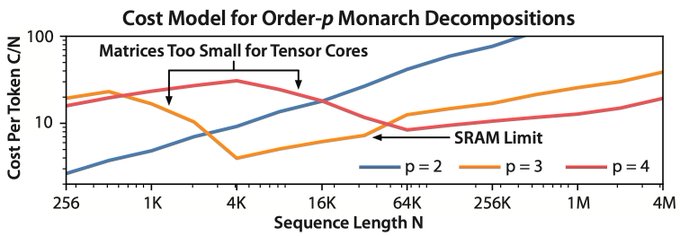
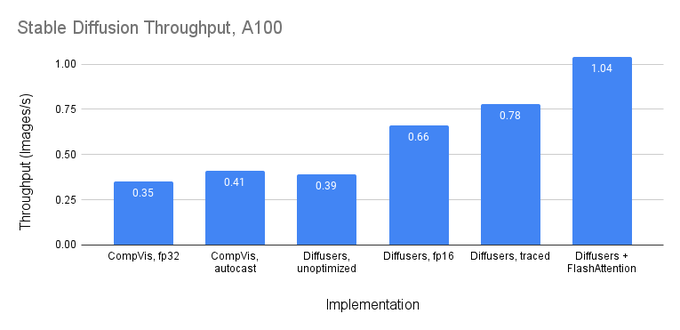
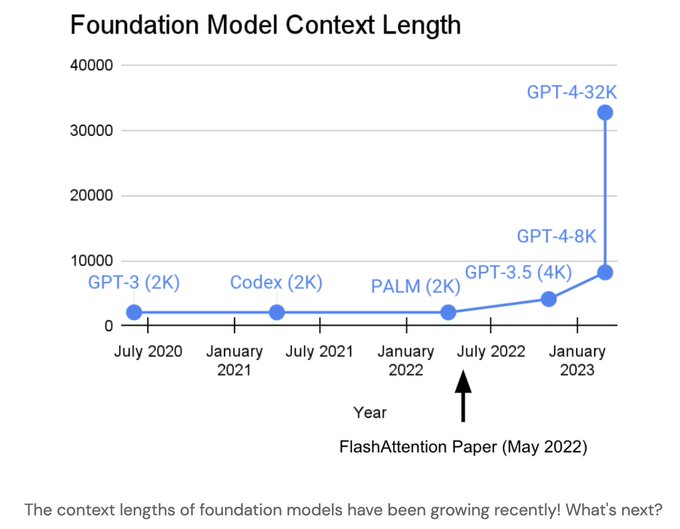
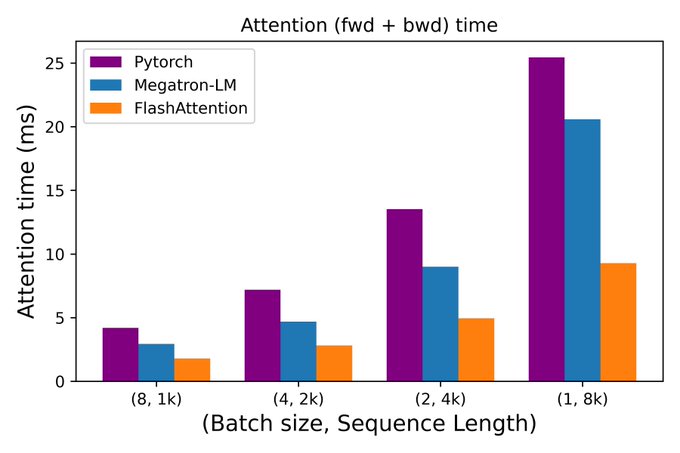
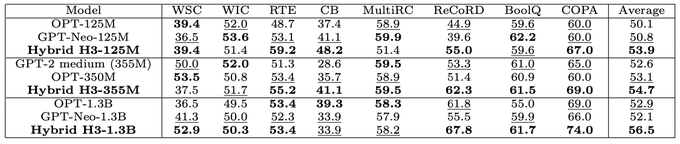
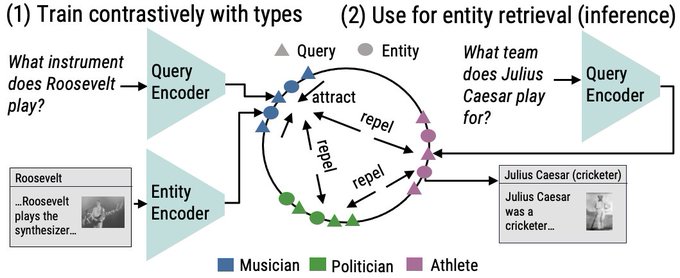
Dan Fu
@realDanFu
4,537
Followers
177
Following
154
Media
587
Statuses
CS PhD Candidate at Stanford, systems for machine learning. Sometimes YouTuber/podcaster. Academic Partner, @togethercompute .
Joined September 2019
Don't wanna be here?
Send us removal request.