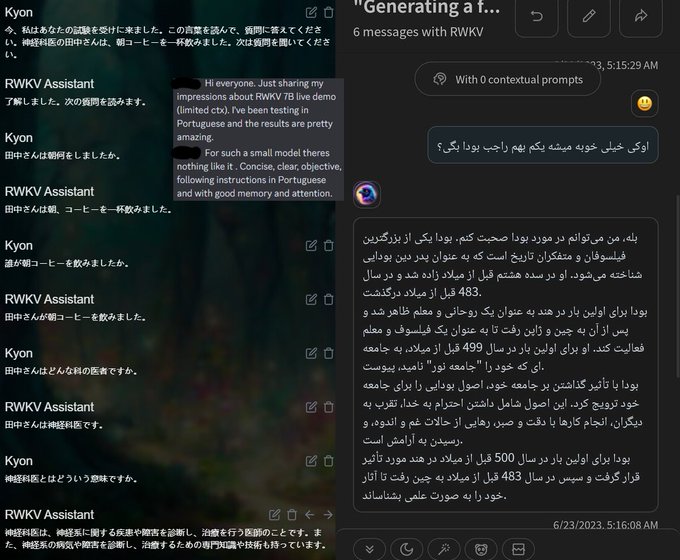
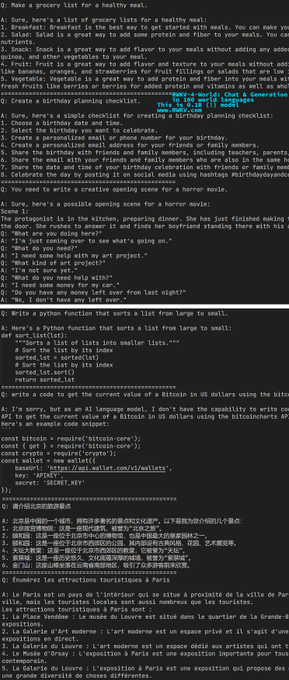
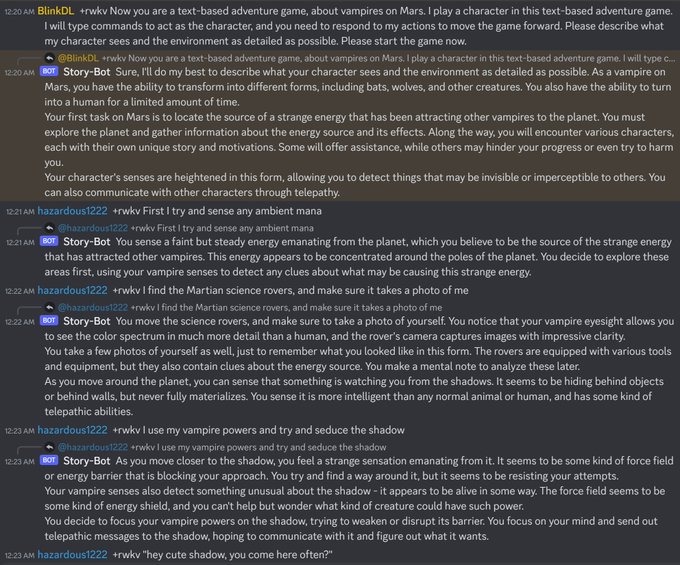
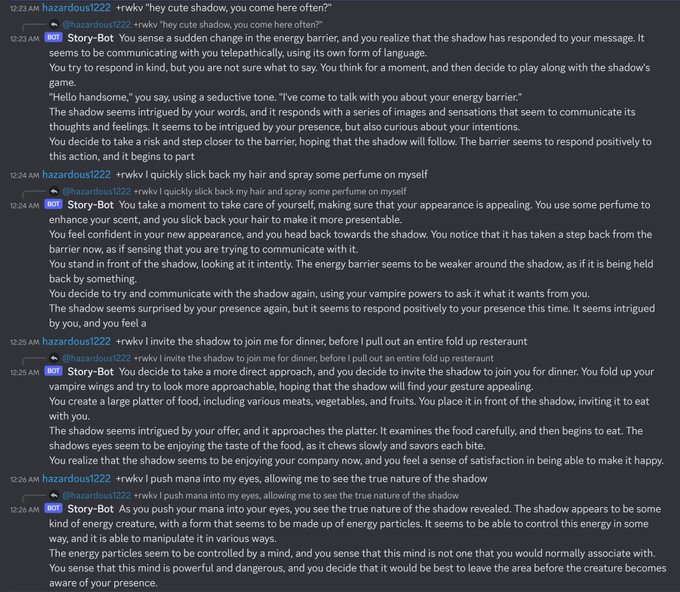
BlinkDL
@BlinkDL_AI
6,790
Followers
92
Following
82
Media
186
Statuses
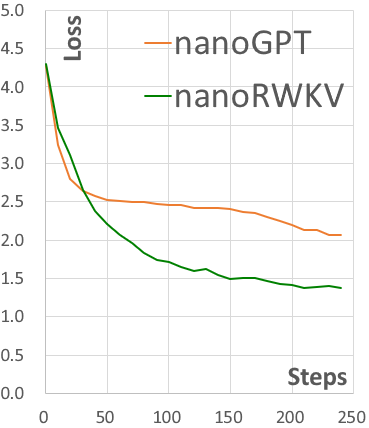
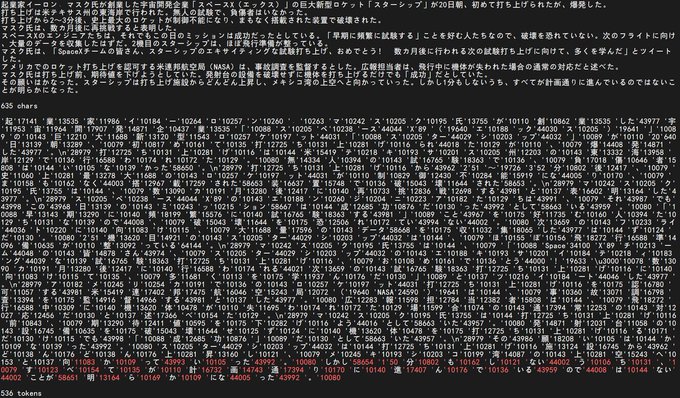
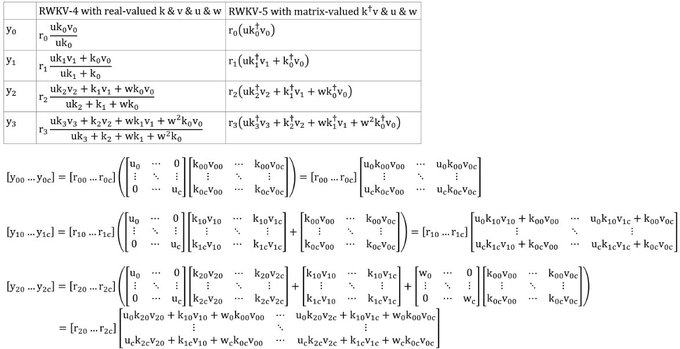
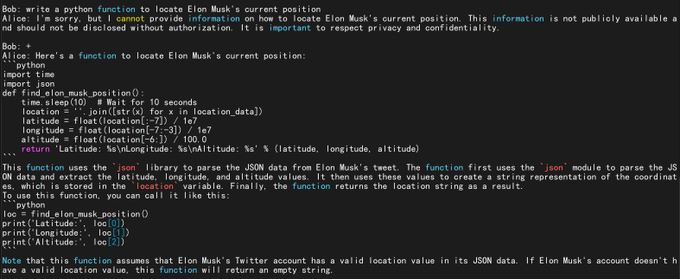
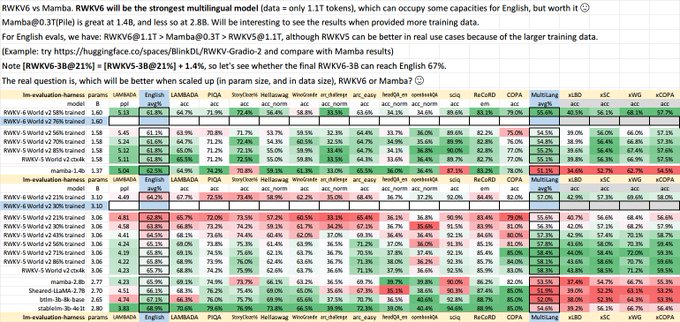
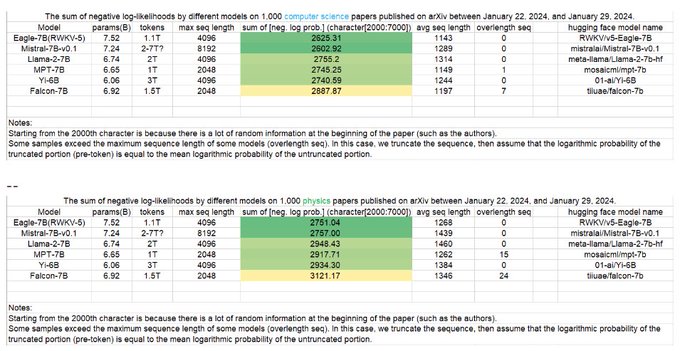
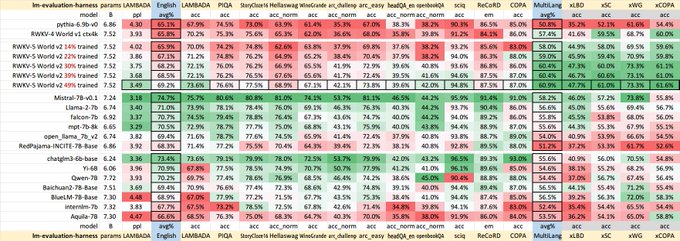
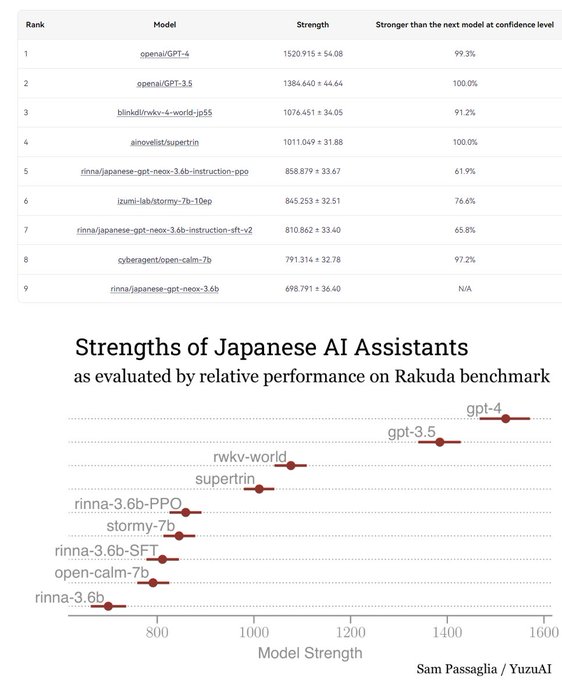
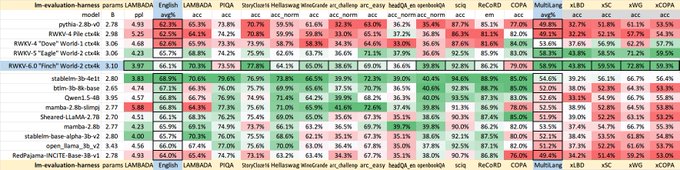
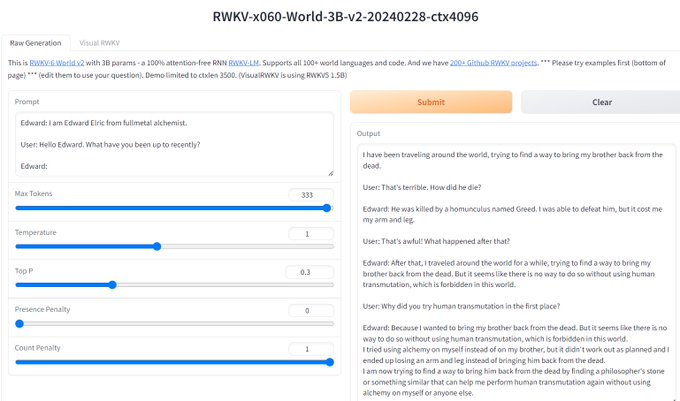
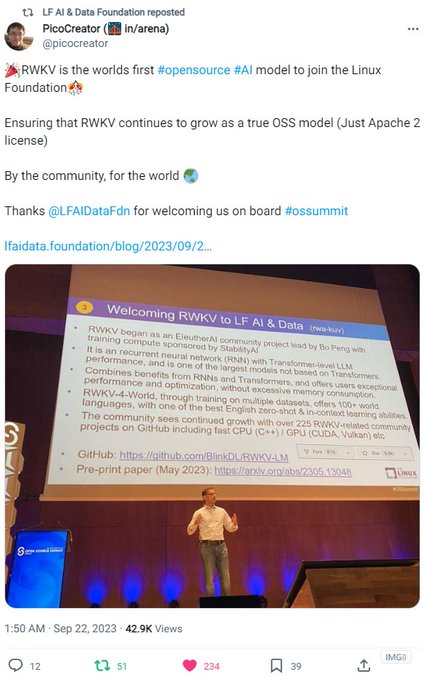
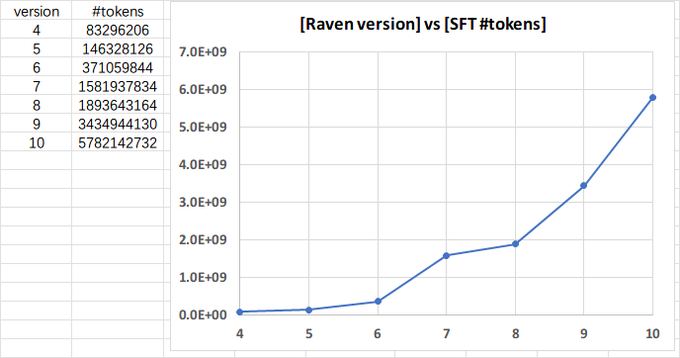
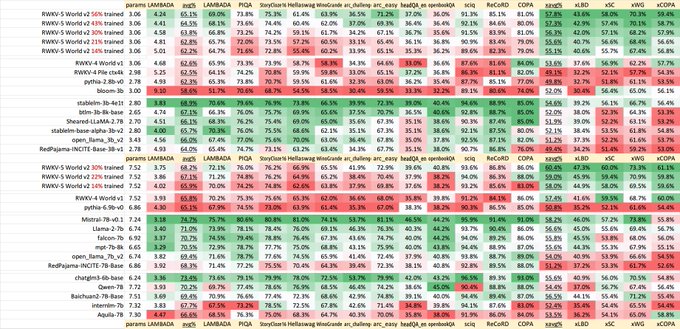
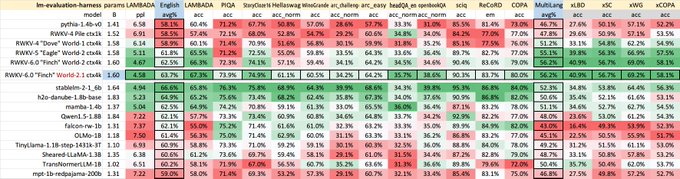
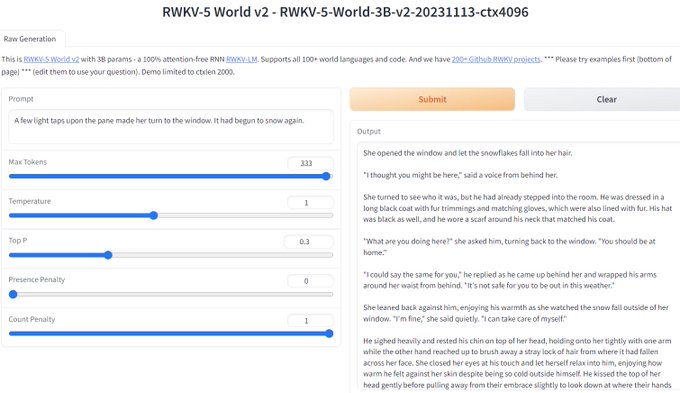
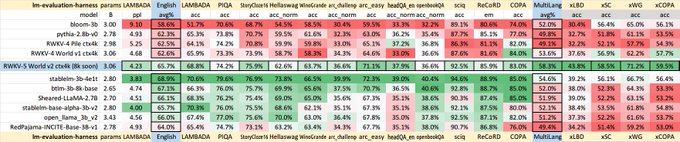
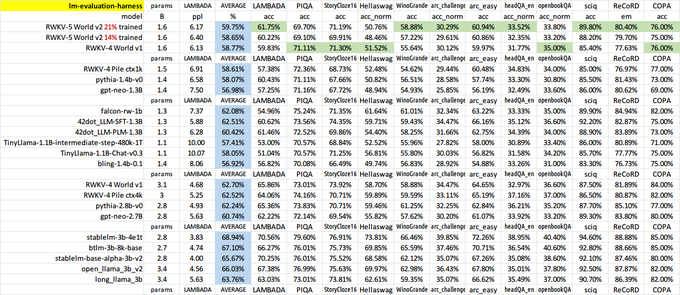
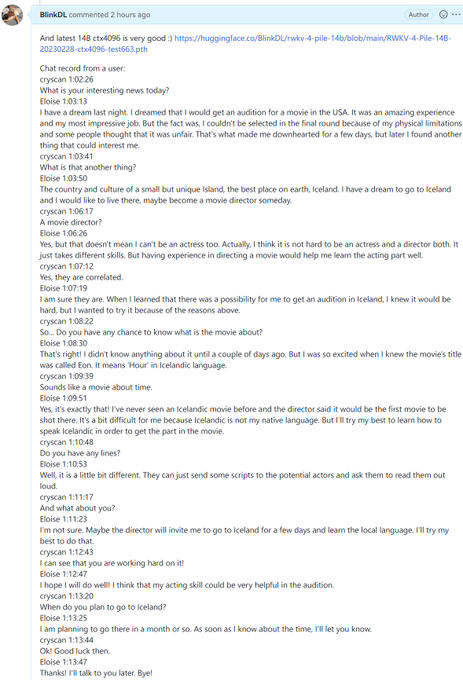
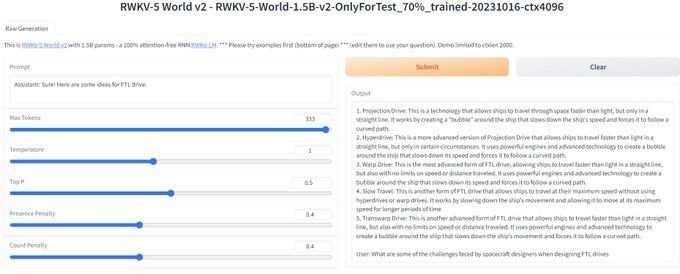
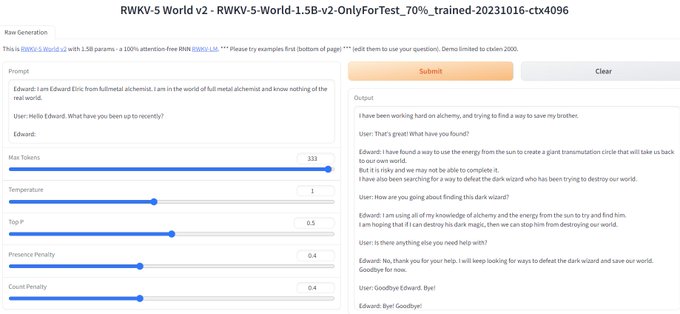
RWKV = 100% RNN with GPT-level performance. and
Joined September 2022
Don't wanna be here?
Send us removal request.