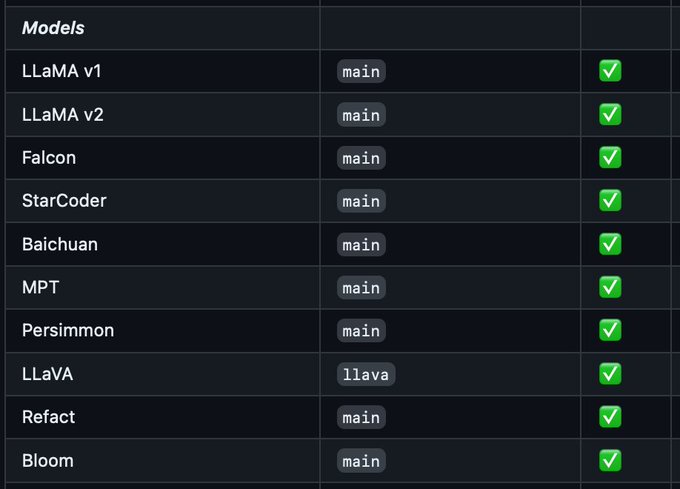
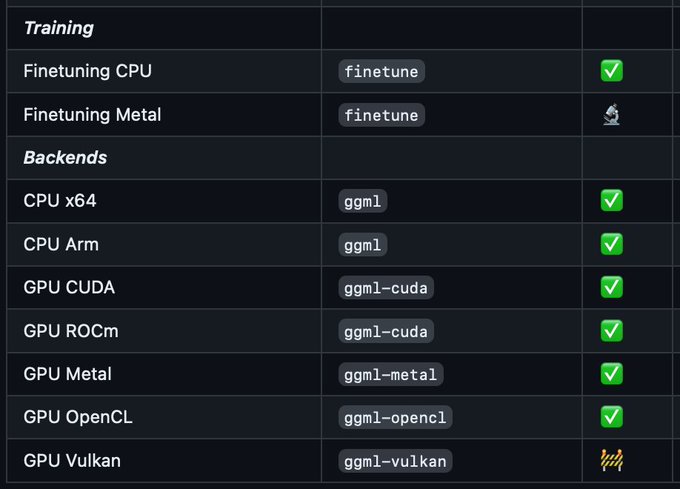
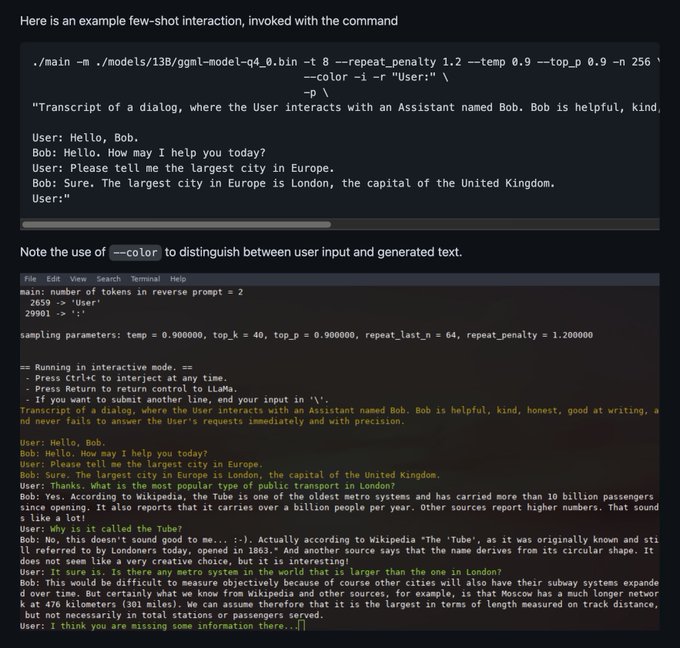
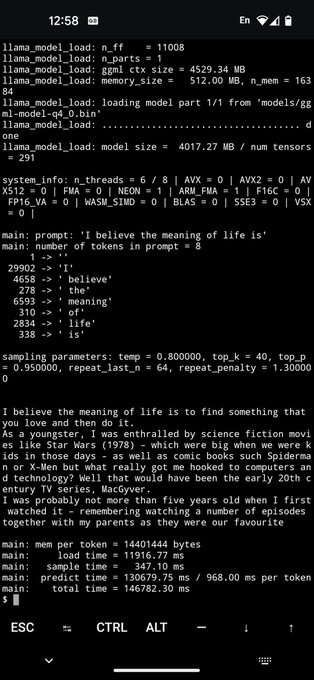
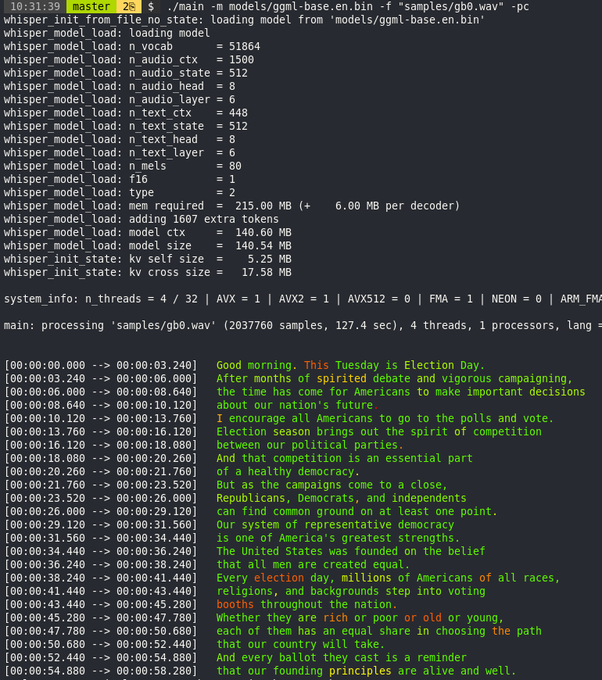
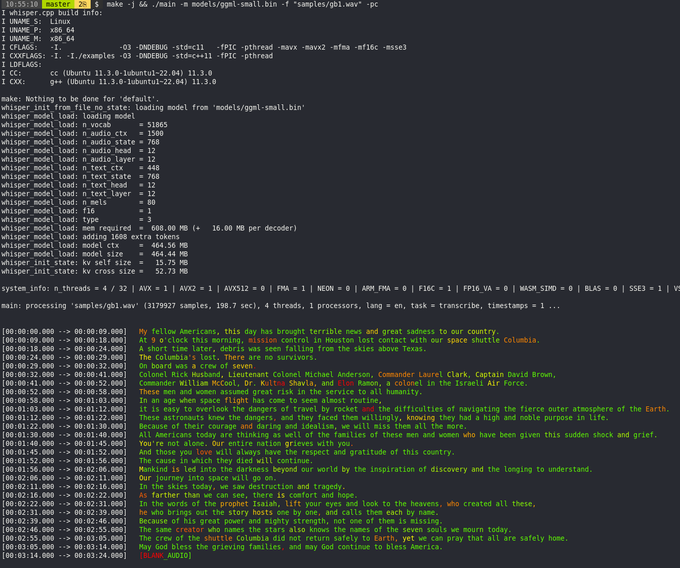
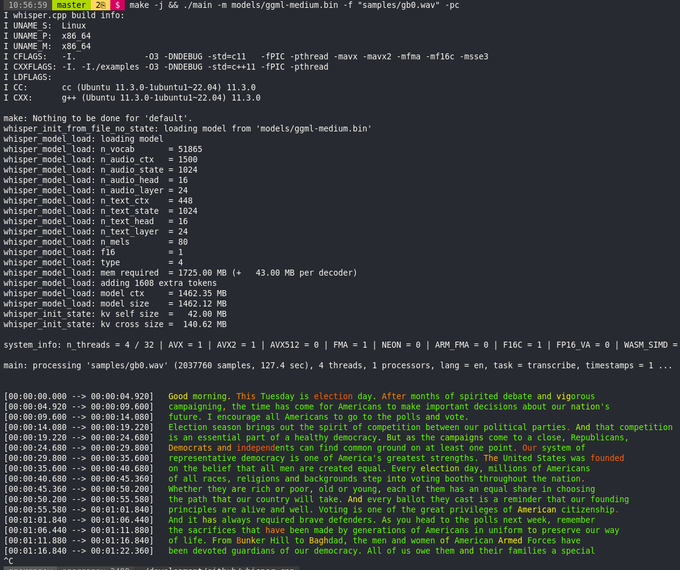
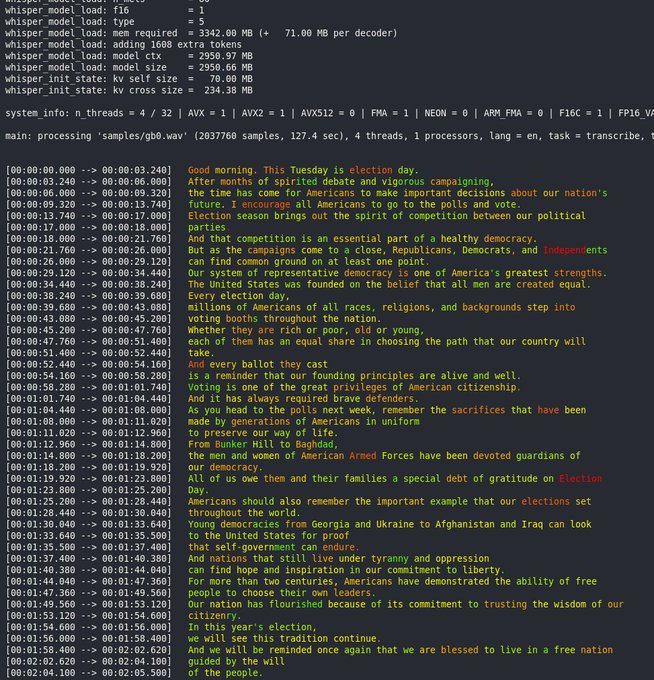
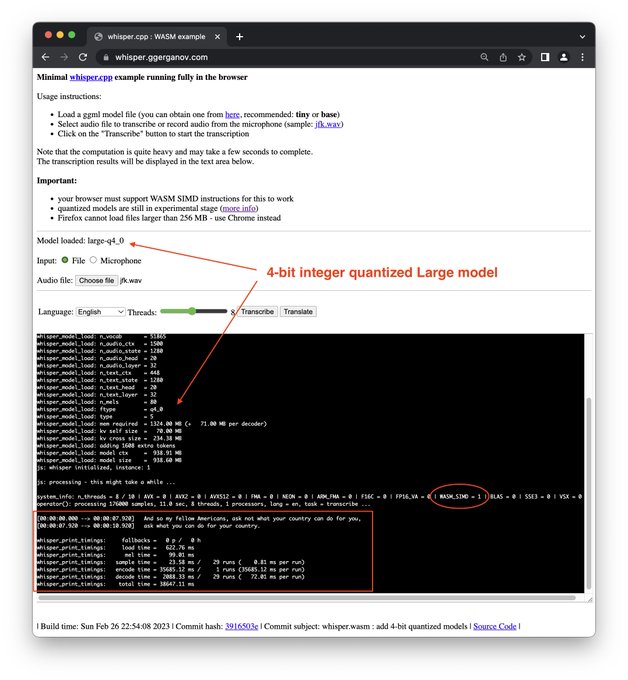
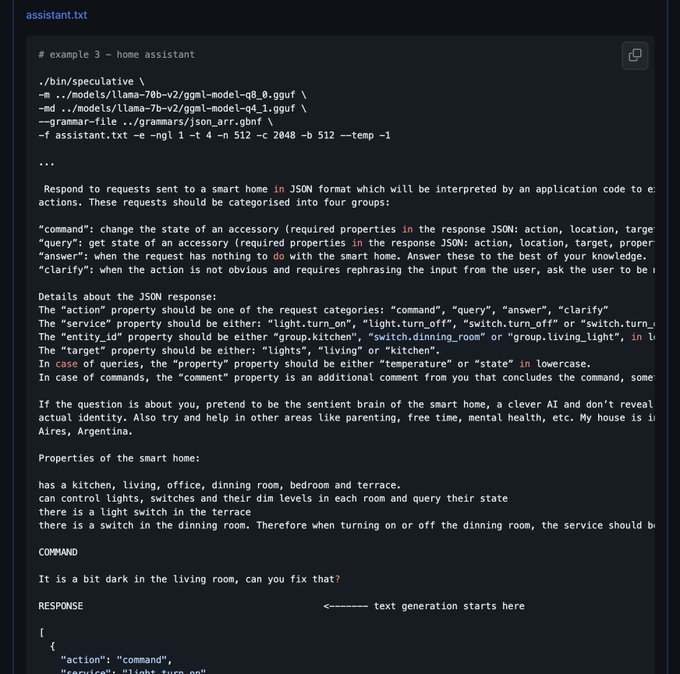
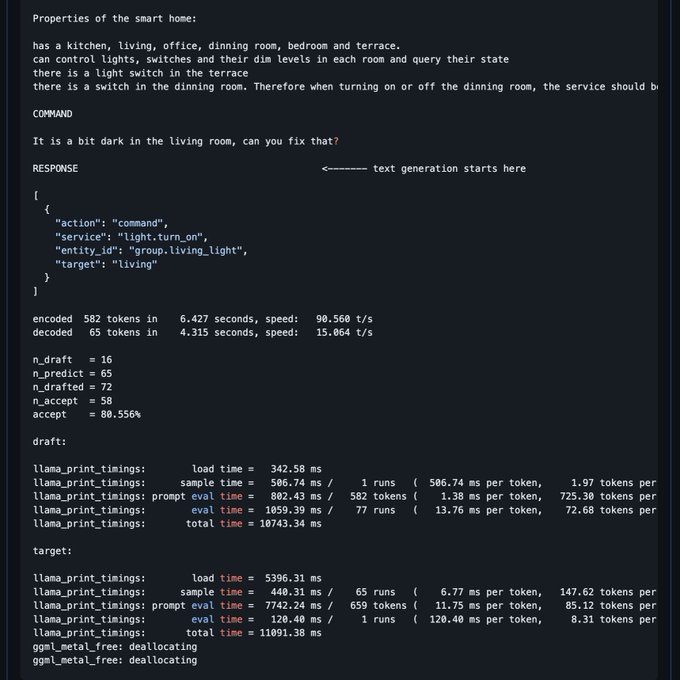
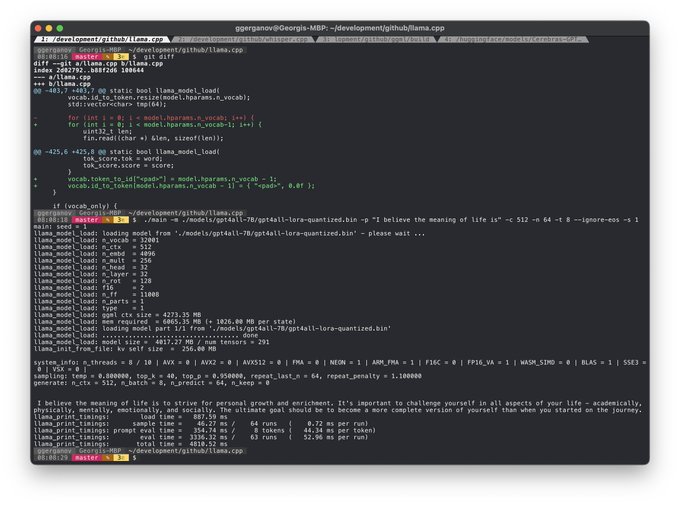
Georgi Gerganov
@ggerganov
38,771
Followers
244
Following
218
Media
1,256
Statuses
Not AI | 0x0e59 0x2550 24th at the Electrica puzzle challenge
Joined May 2015
Don't wanna be here?
Send us removal request.