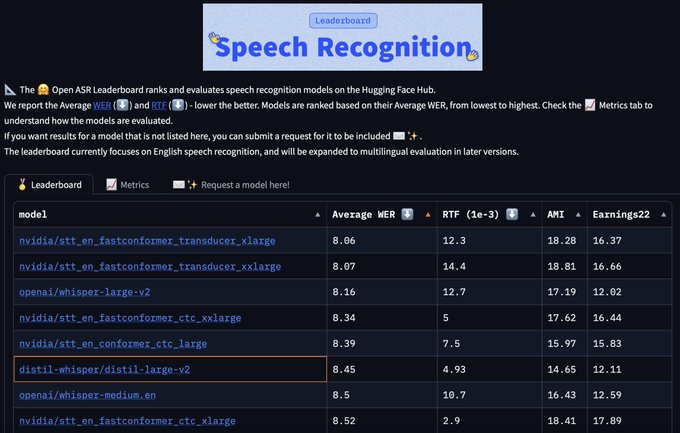
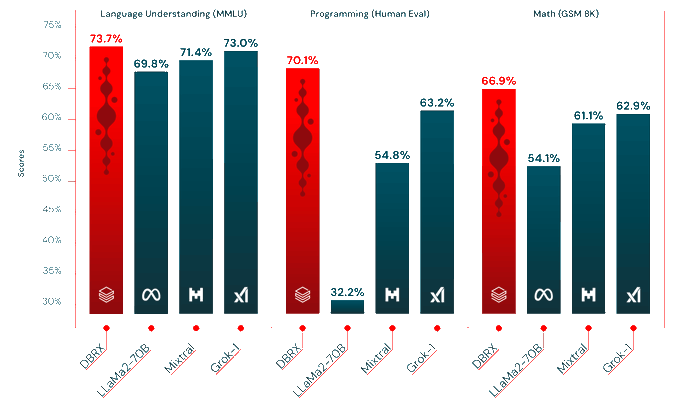
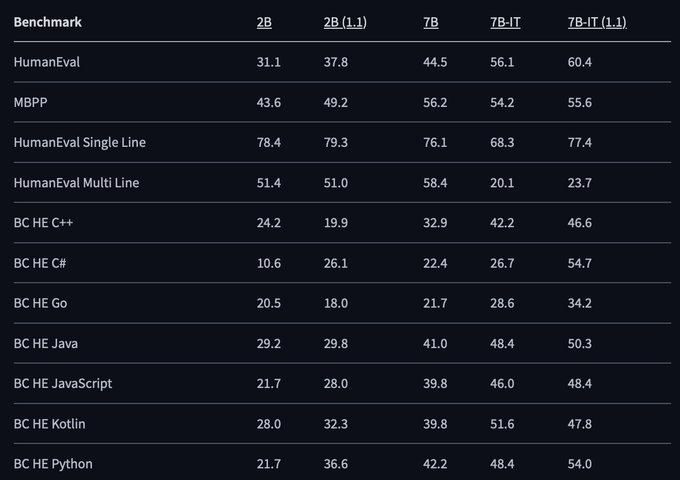
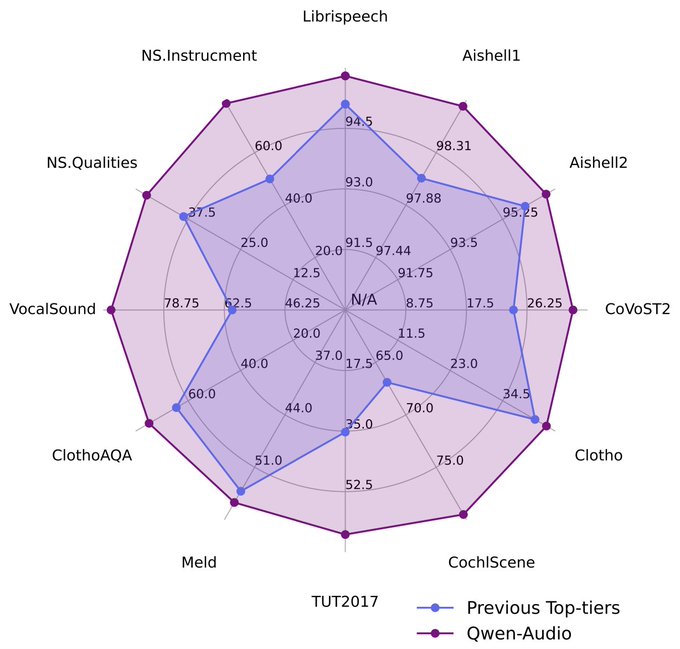
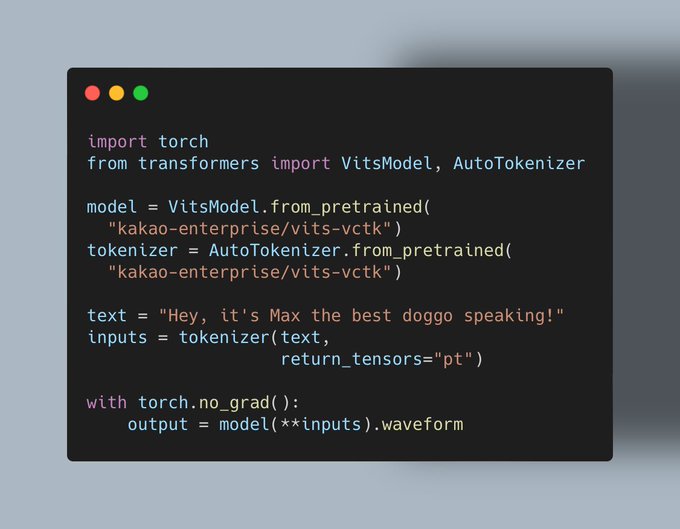
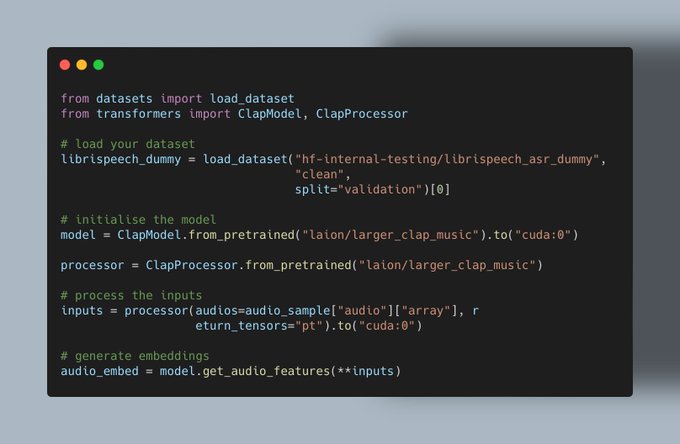
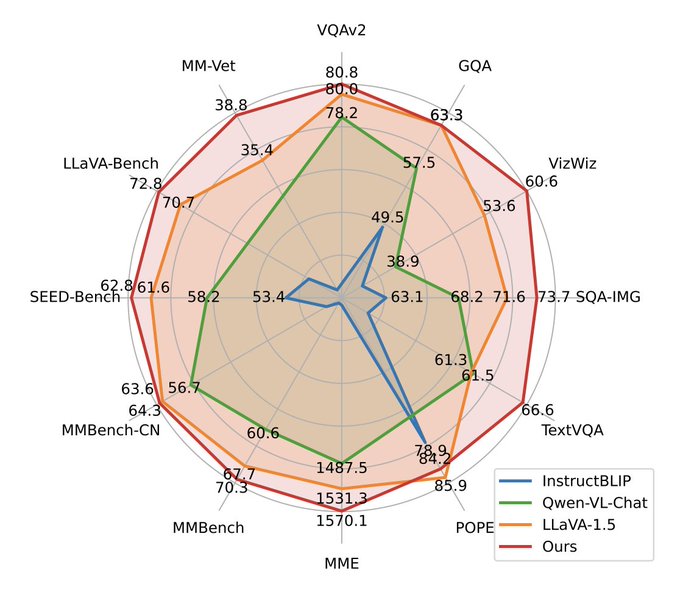
Vaibhav (VB) Srivastav
@reach_vb
11,294
Followers
172
Following
719
Media
3,862
Statuses
GPU poor @Huggingface | F1 fan | Here for @at_sofdog ’s wisdom | *opinions my own
Don't wanna be here?
Send us removal request.