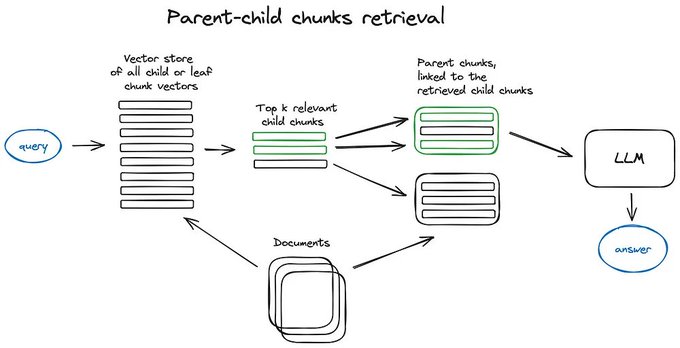
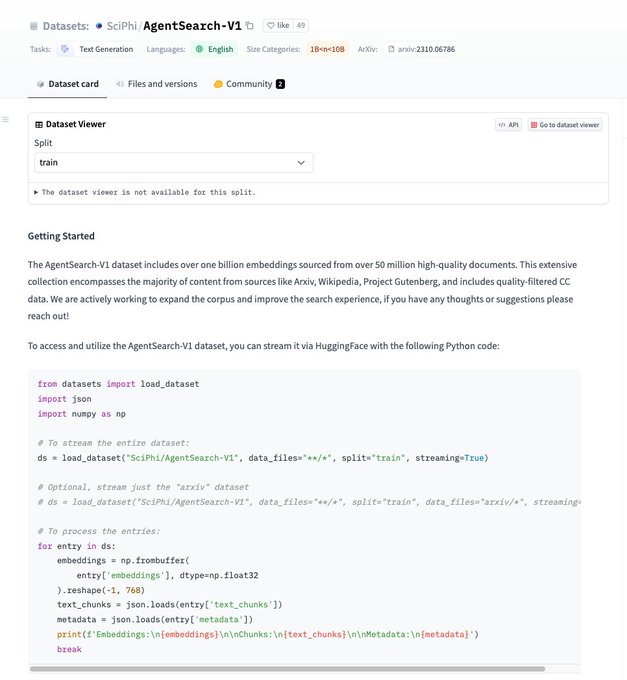
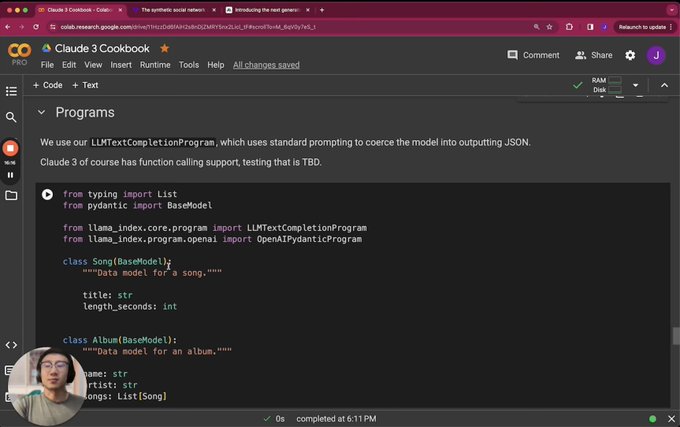
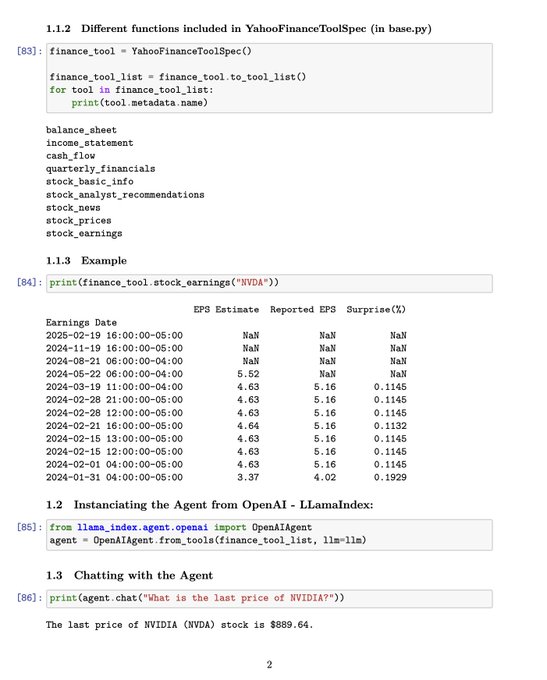
LlamaIndex 🦙
@llama_index
63,838
Followers
25
Following
938
Media
2,315
Statuses
The way to connect LLMs to your data. Github: Docs: Discord:
Joined December 2022
Don't wanna be here?
Send us removal request.