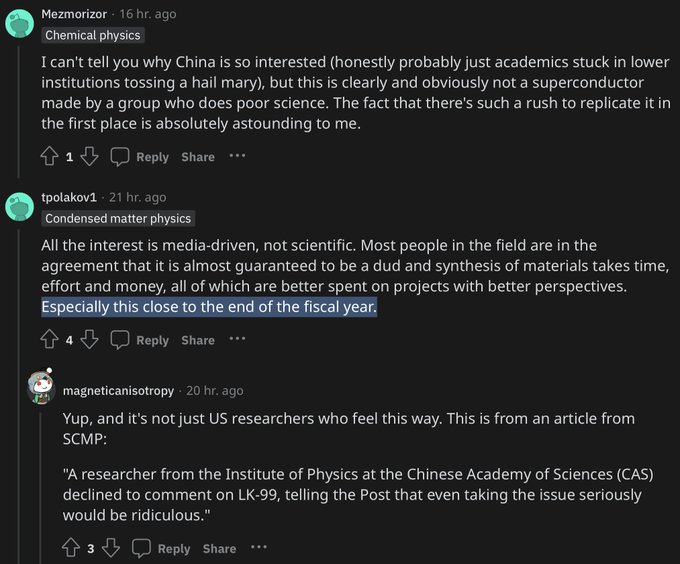
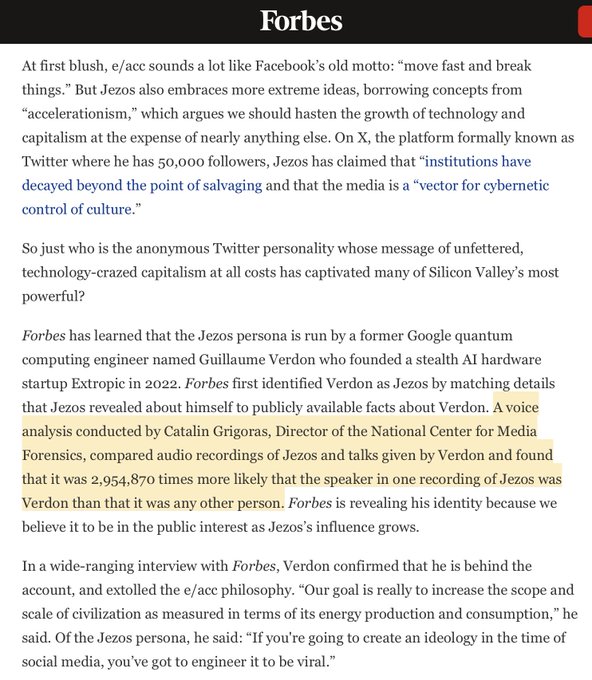
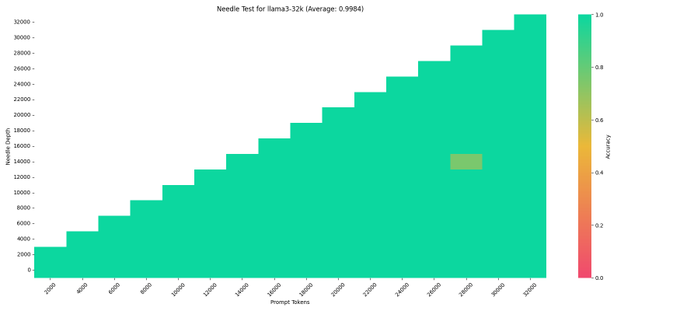
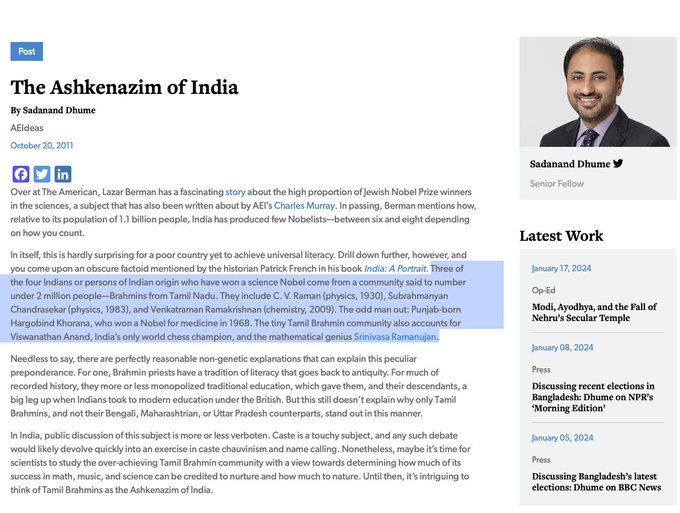
Teortaxes▶️
@teortaxesTex
8,073
Followers
1,357
Following
3,812
Media
27,531
Statuses
Ours is the age of unaligned utilitarians. Other problems are relatively unimportant, but sometimes I tweet about them anyway. (кто/кого)
Joined September 2010
Don't wanna be here?
Send us removal request.