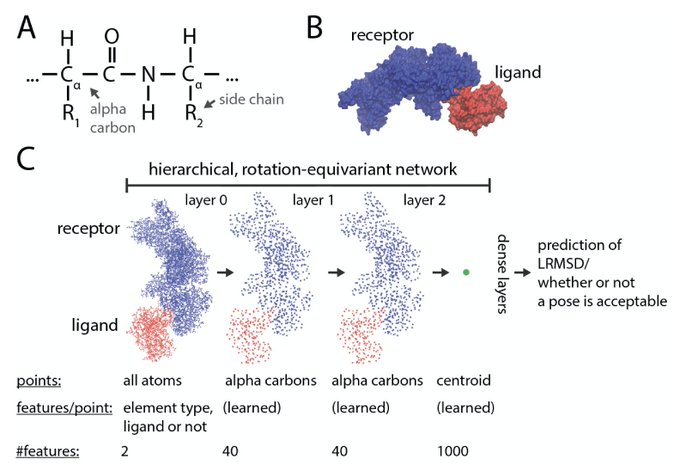
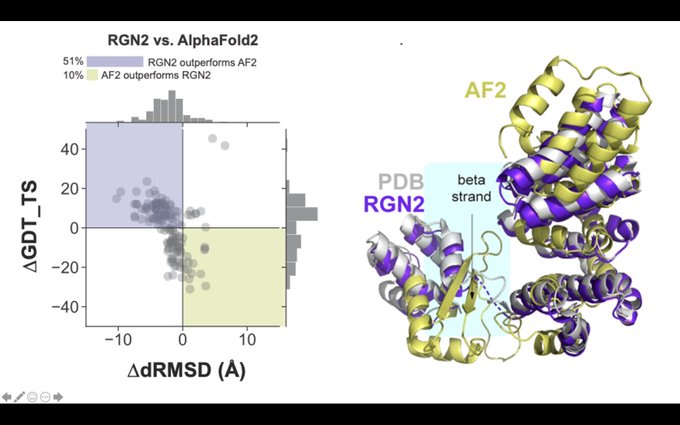
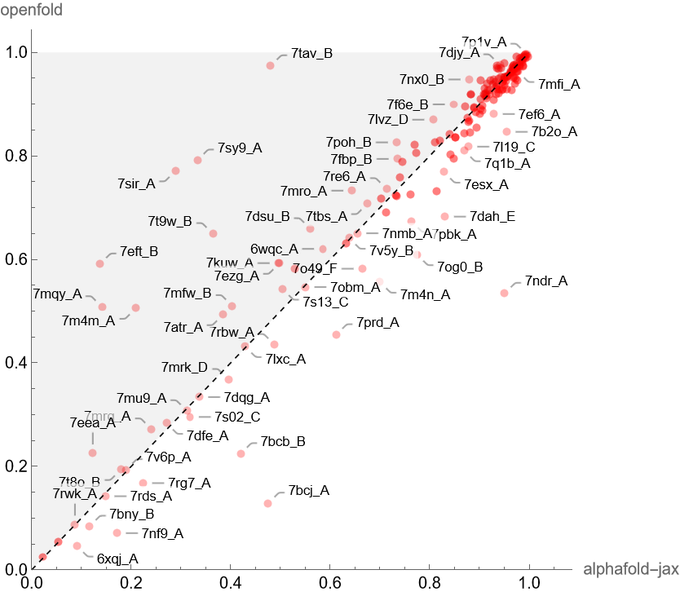
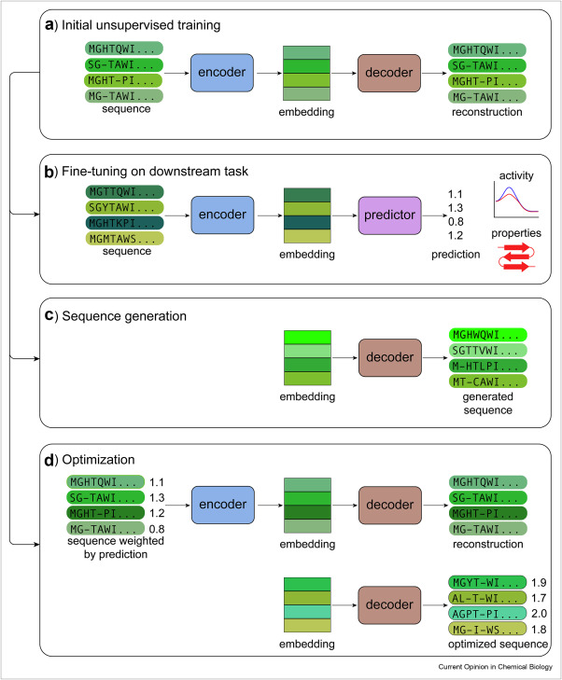
Mohammed AlQuraishi
@MoAlQuraishi
11,022
Followers
359
Following
29
Media
1,711
Statuses
MLing biomolecules en route to structural systems biology. Asst Prof of Systems Biology and CS @Columbia . Prev. @Harvard SysBio; @Stanford Genetics, Stats.
Don't wanna be here?
Send us removal request.