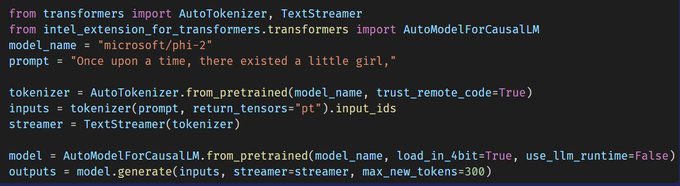
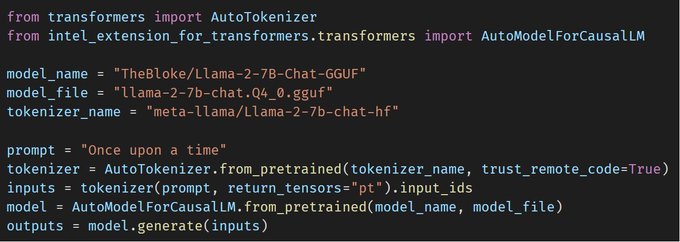
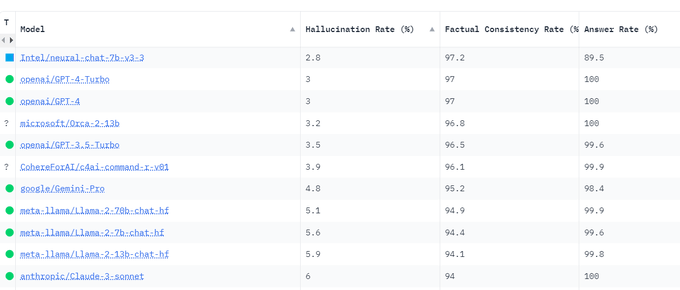
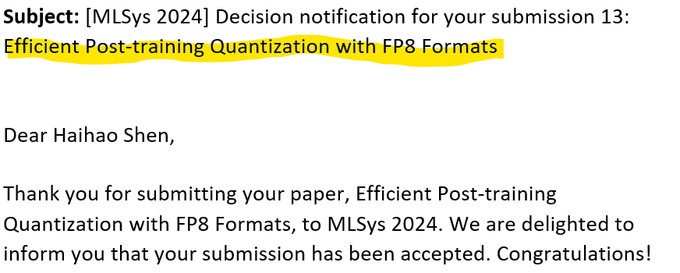
Haihao Shen
@HaihaoShen
2,757
Followers
2,595
Following
36
Media
401
Statuses
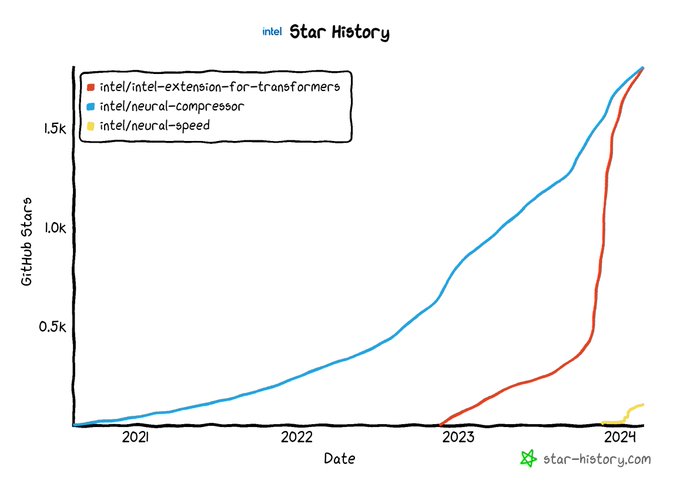
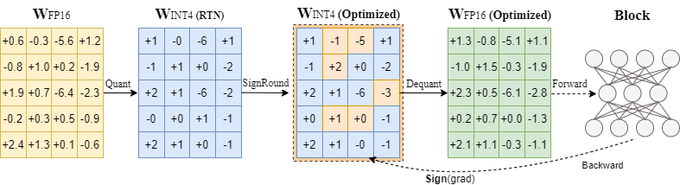
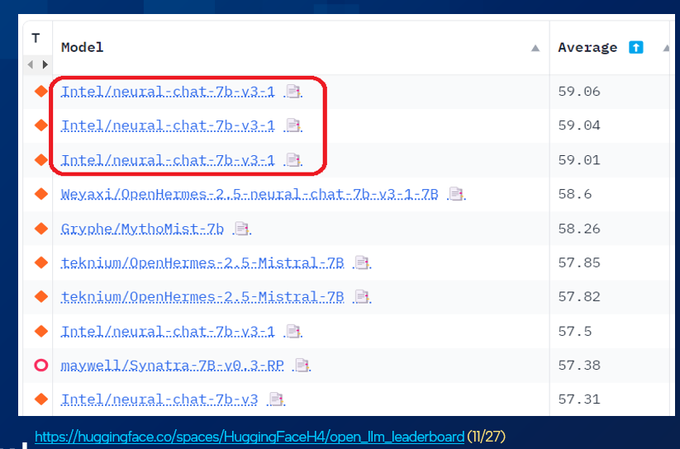
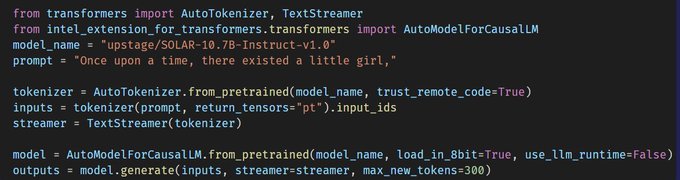
Creator of Intel Neural Compressor/Speed/Coder, Intel Ext. for Transformers, AutoRound; HF Optimum-Intel Maintainer; Founding member of OPEA; Opinions my own
Don't wanna be here?
Send us removal request.