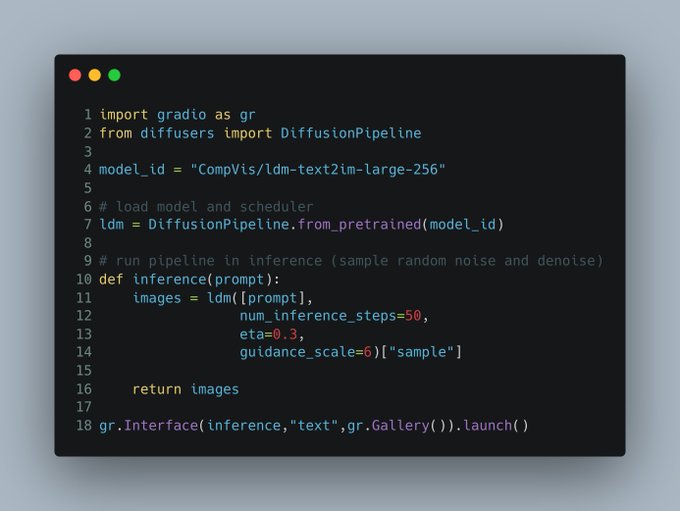
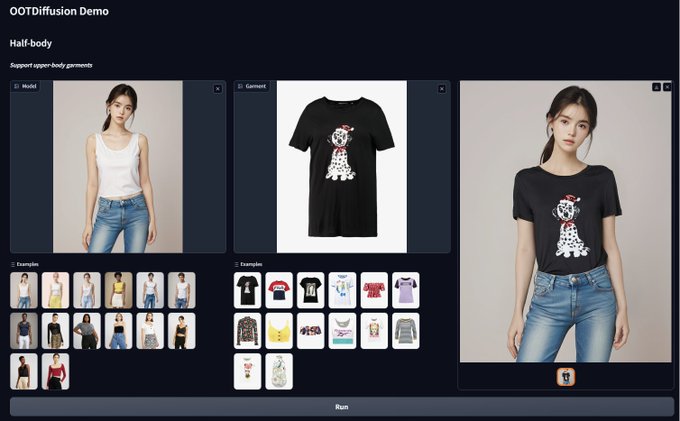
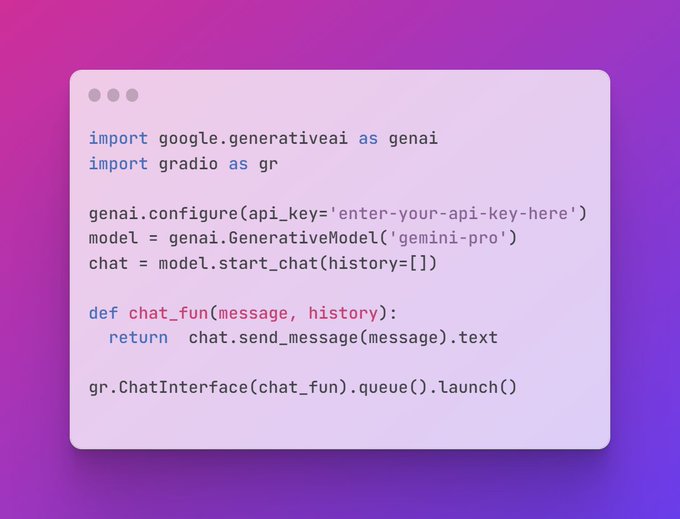
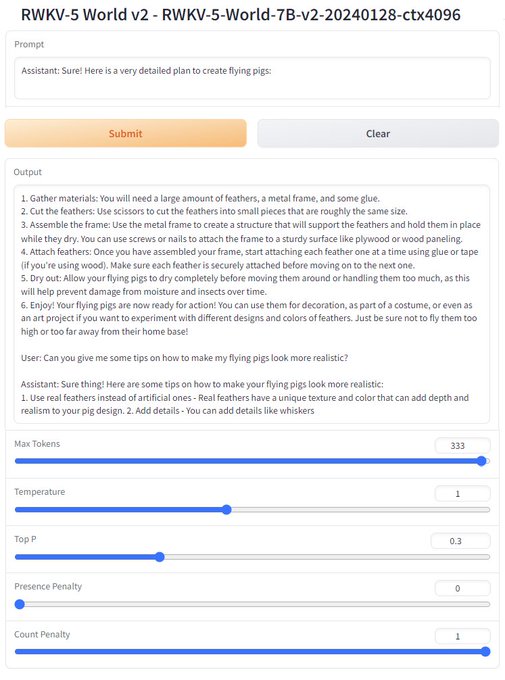
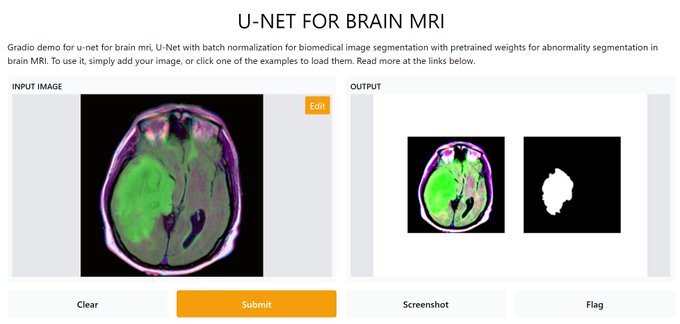
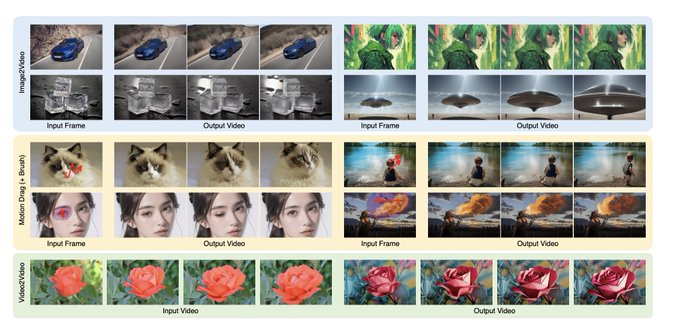
Gradio
@Gradio
34,302
Followers
12
Following
702
Media
2,887
Statuses
Build and share machine learning demos in 3 lines of Python. Part of the @Huggingface family 🤗
Joined April 2019
Don't wanna be here?
Send us removal request.