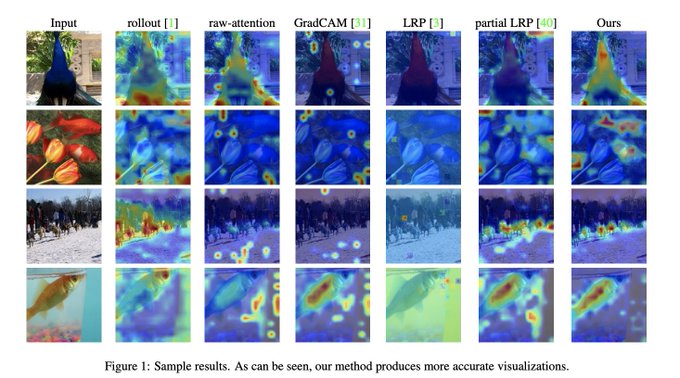
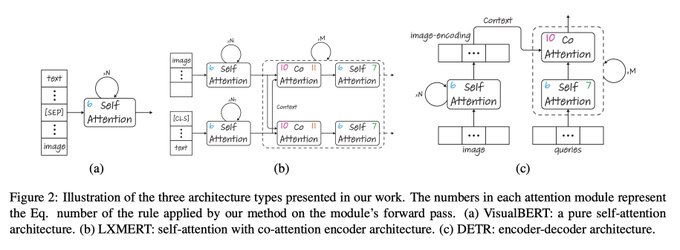
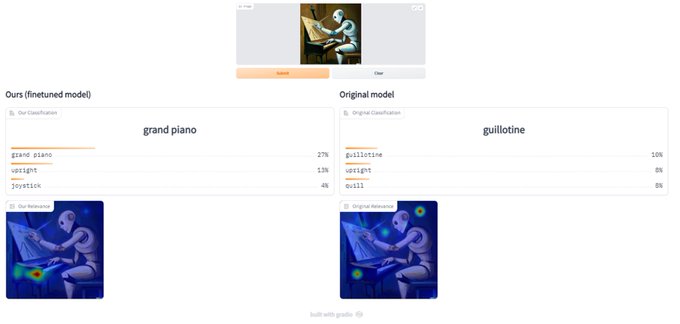
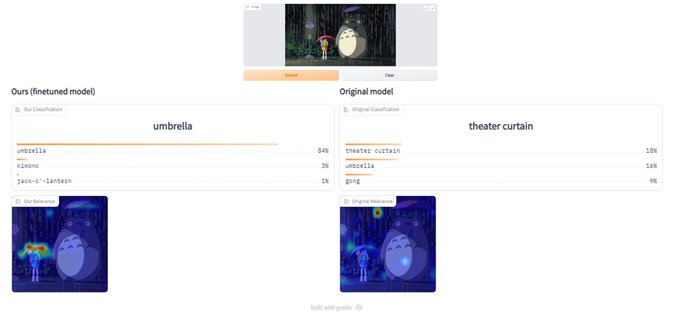
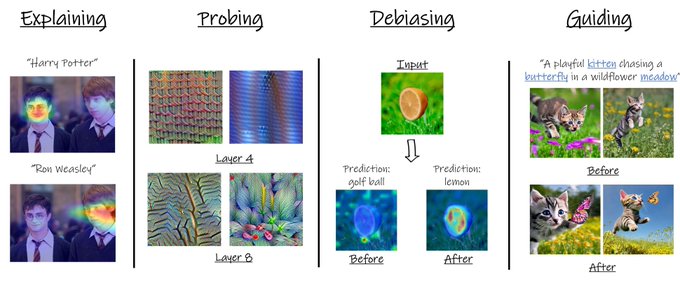
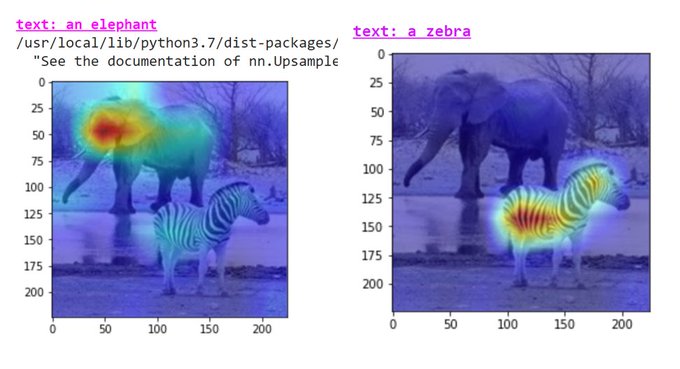
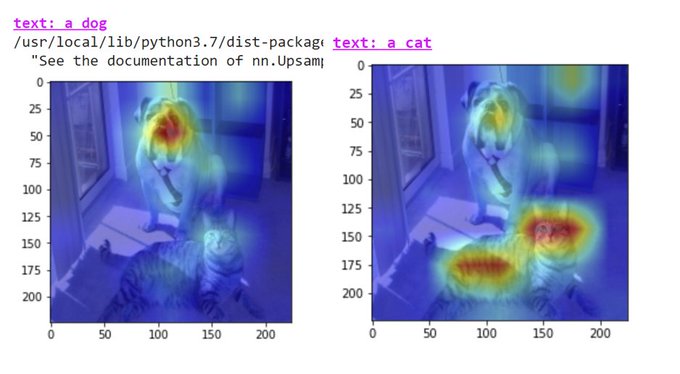
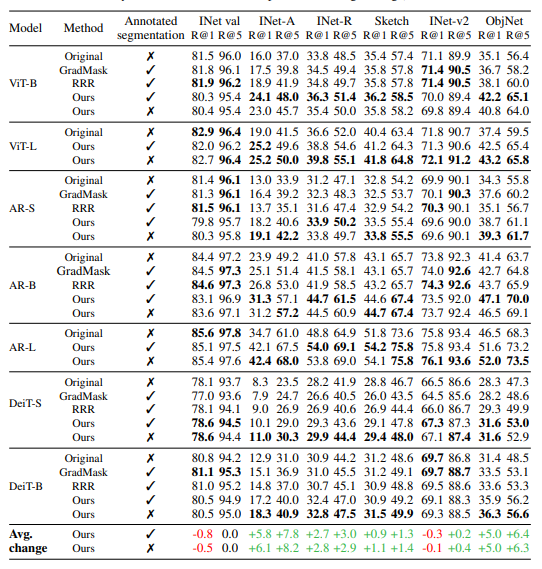
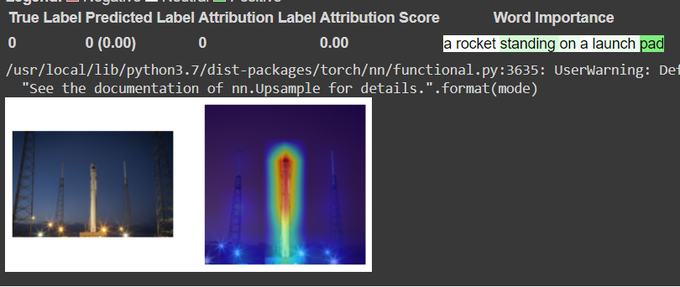
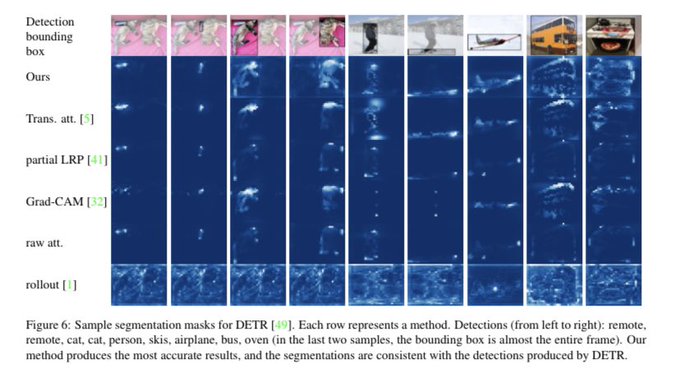
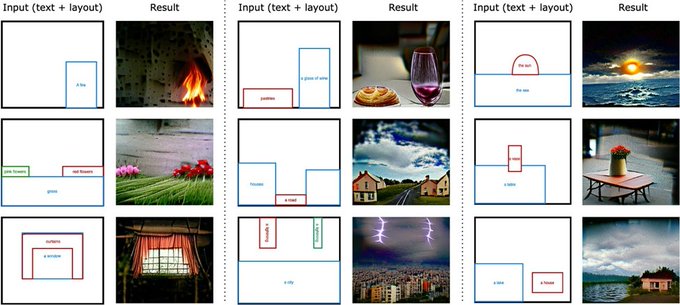
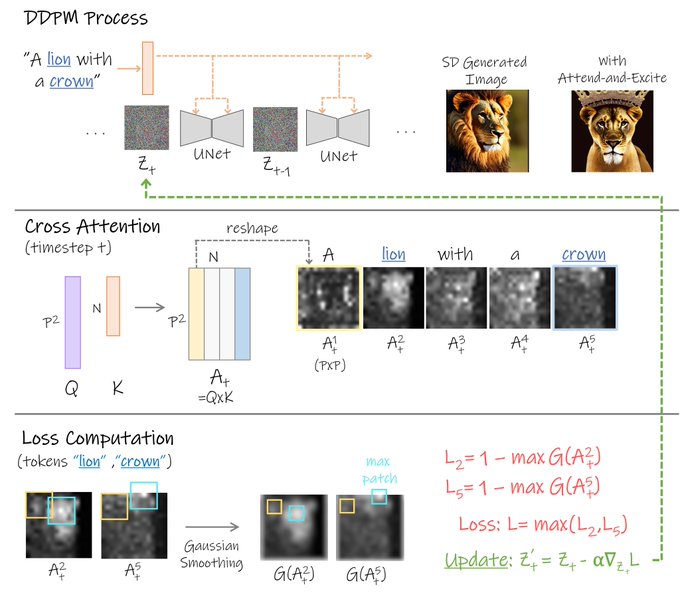
Hila Chefer@ ICLR’24
@hila_chefer
2,021
Followers
204
Following
56
Media
359
Statuses
PhD candidate @TelAvivUni , student researcher @GoogleAI , interested in Deep Learning, Computer Vision, explainable AI
Joined December 2020
Don't wanna be here?
Send us removal request.