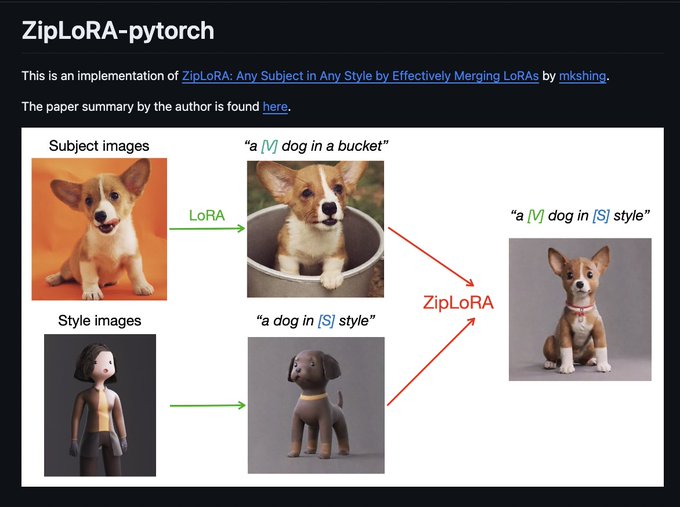
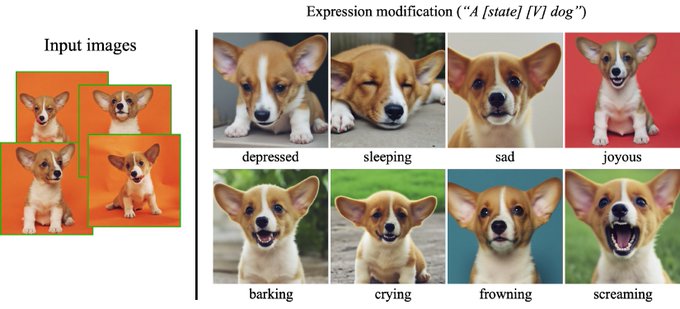
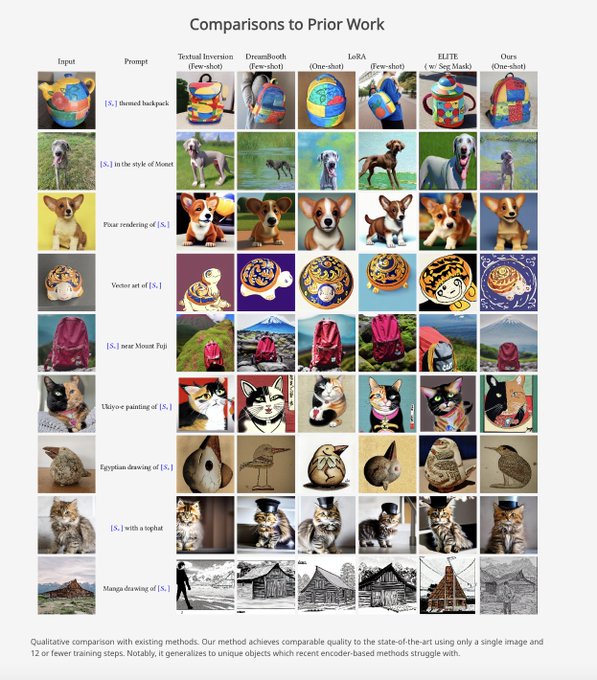
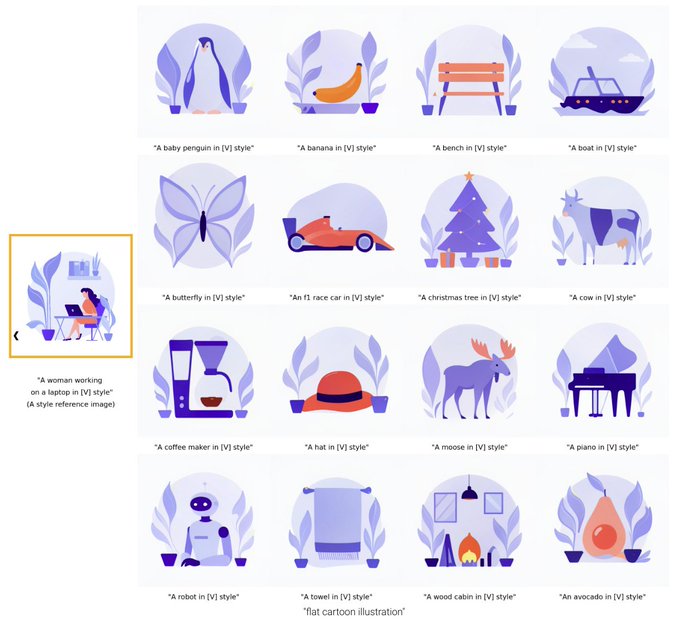
Nataniel Ruiz
@natanielruizg
5,563
Followers
1,546
Following
257
Media
6,378
Statuses
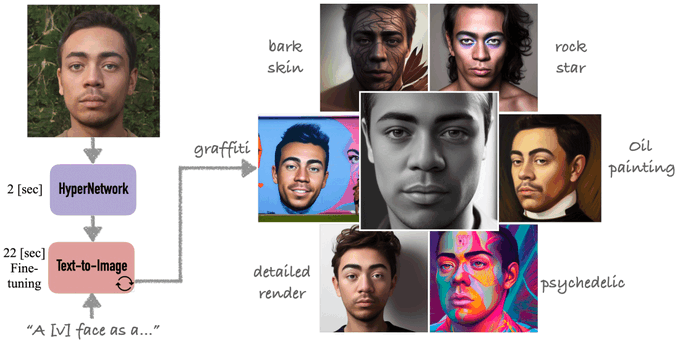
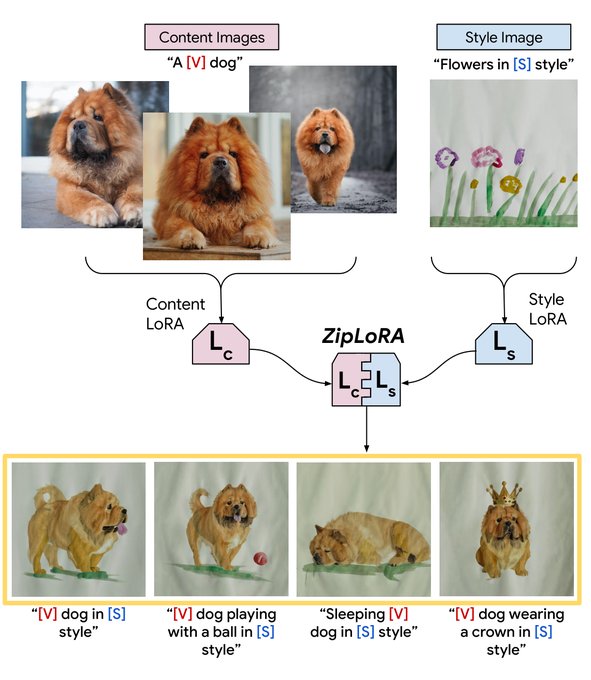
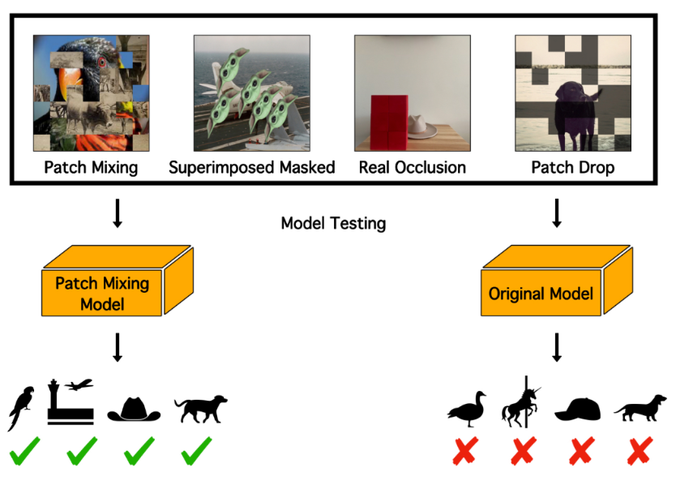
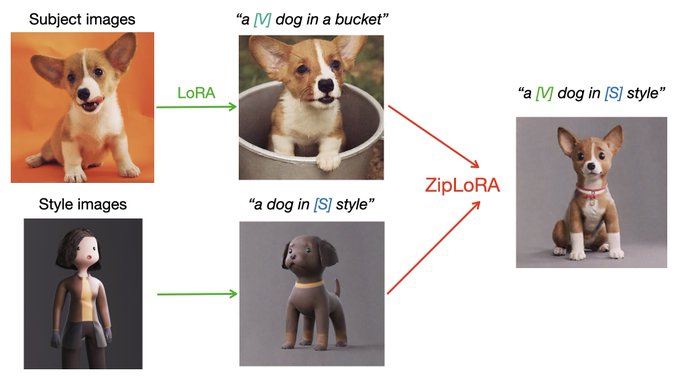
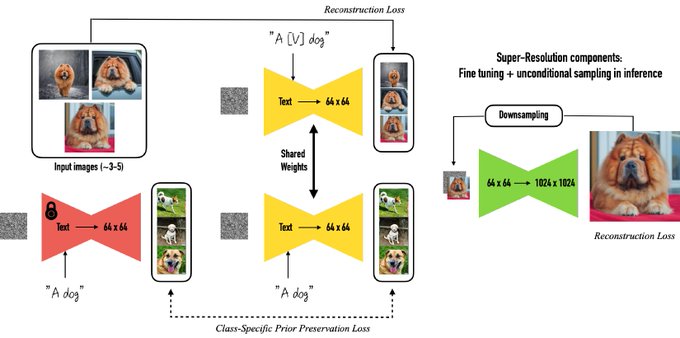
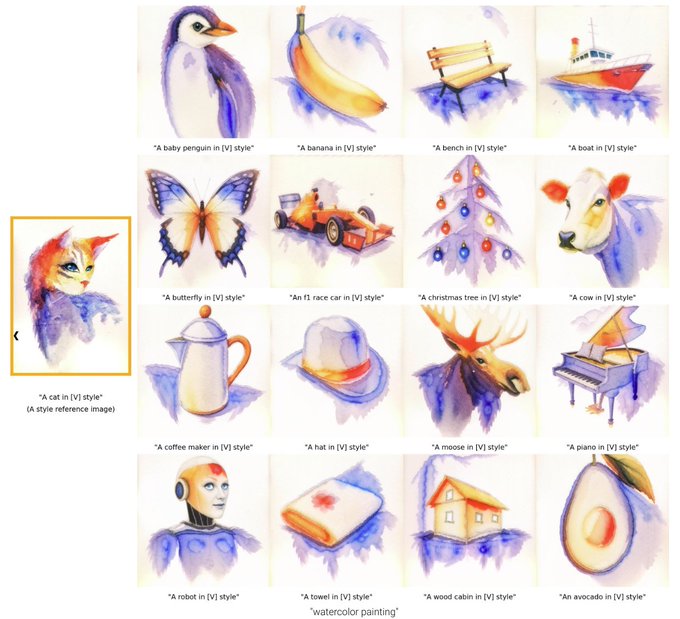
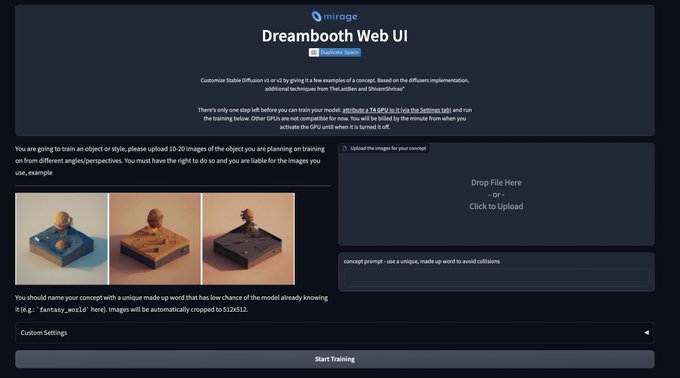
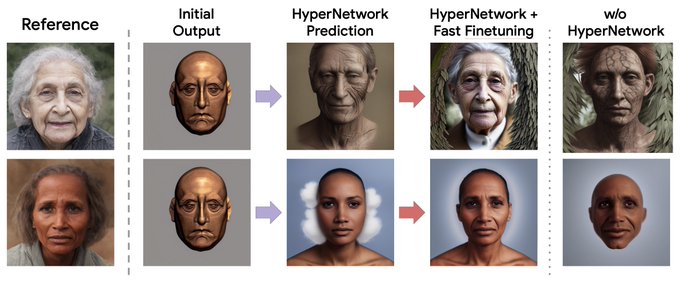
Research Scientist @Google | author of DreamBooth | Personalization of Generative Models (HyperDreamBooth, StyleDrop, RealFill, ZipLora, Platypus, DreamBooth3D)
Don't wanna be here?
Send us removal request.