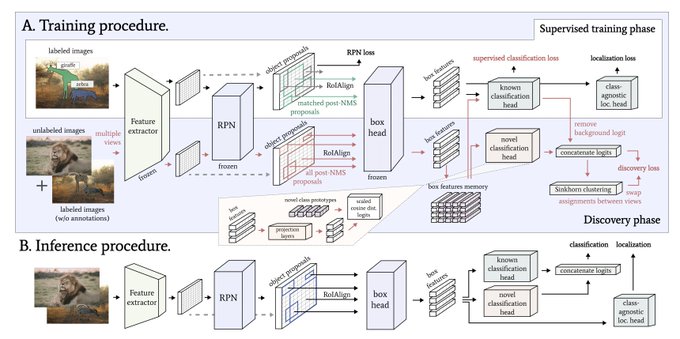
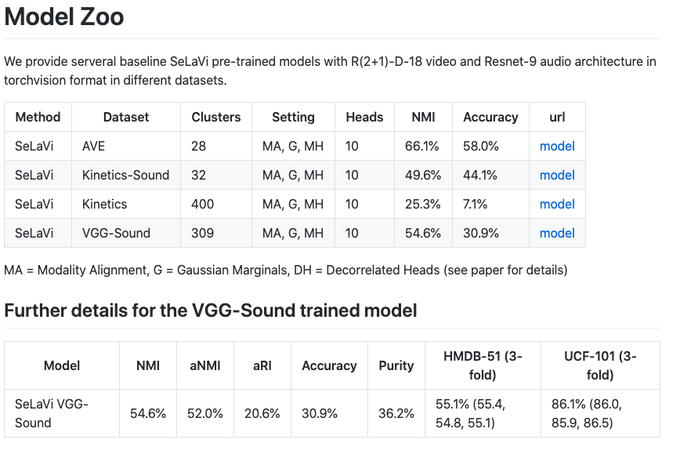
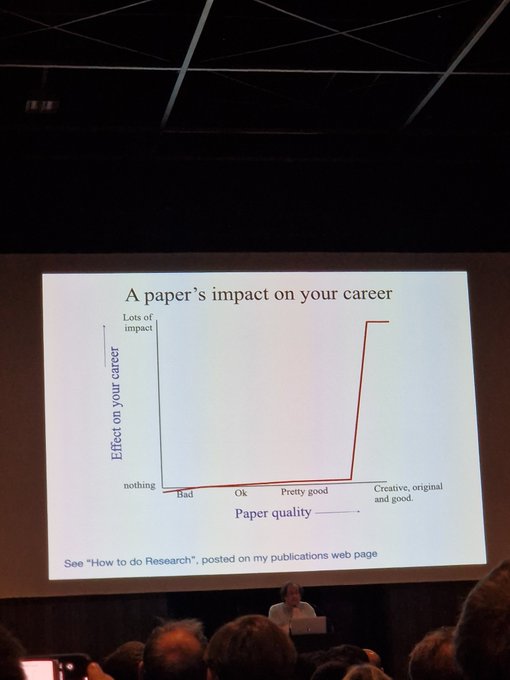
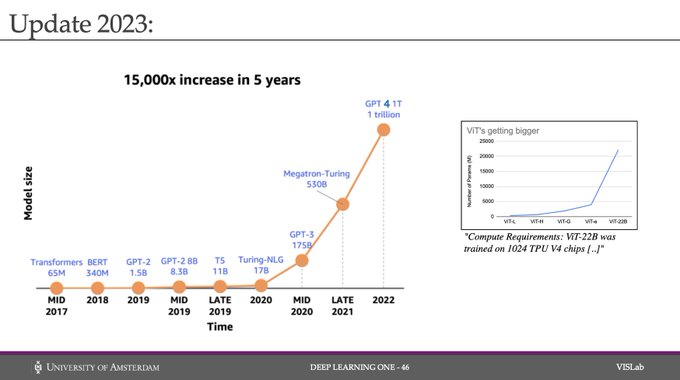
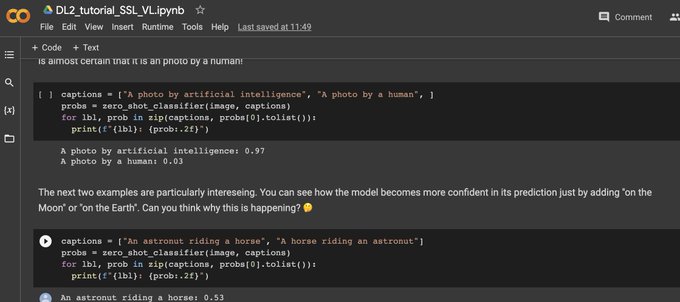
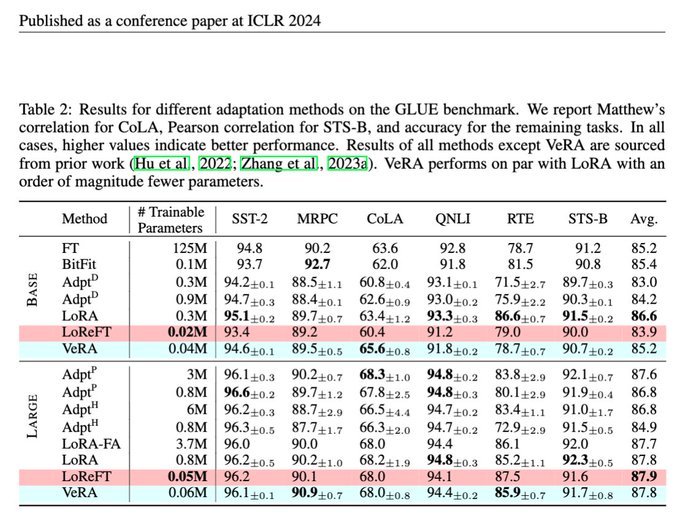
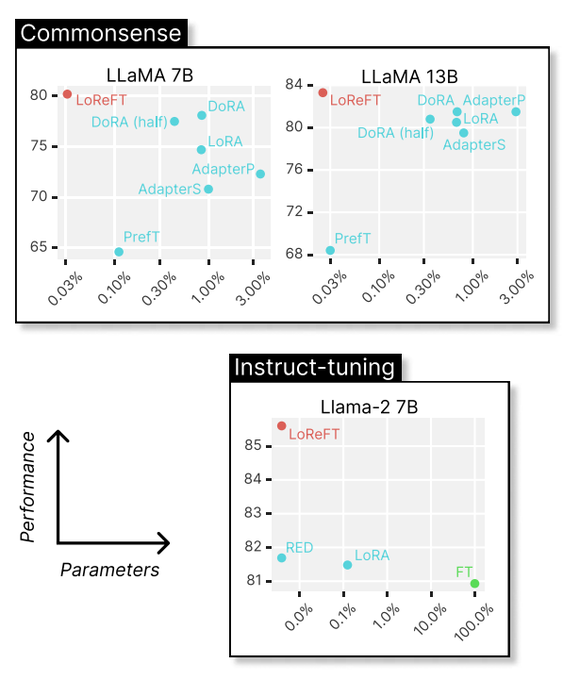
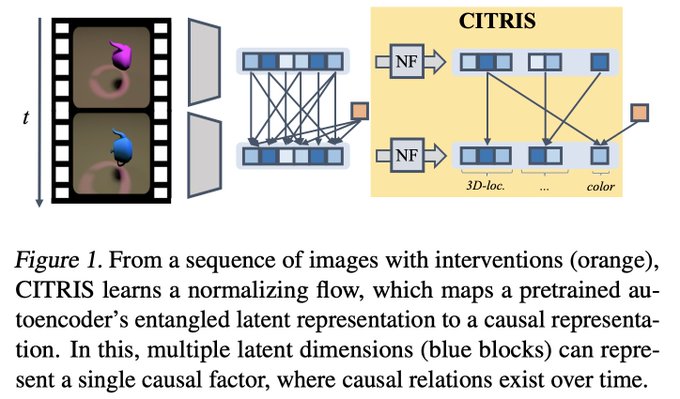
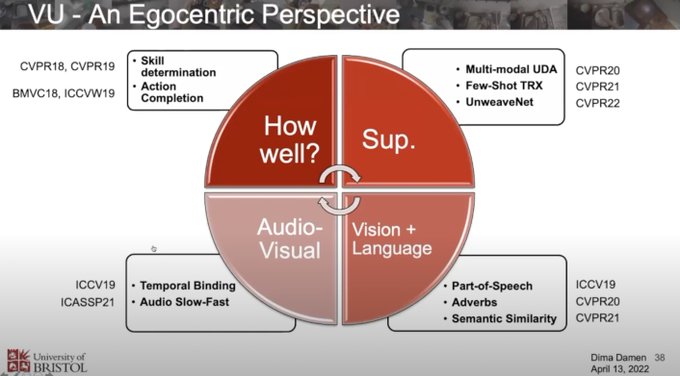
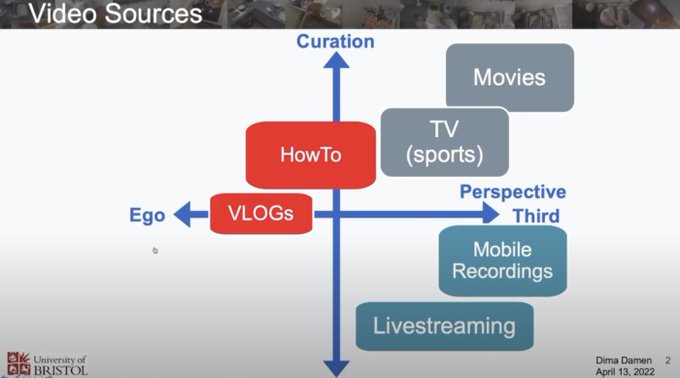
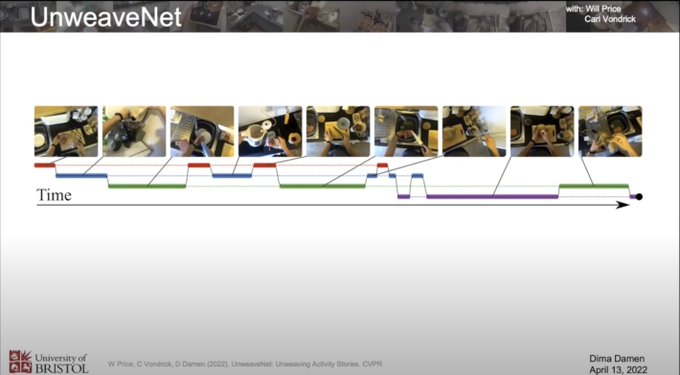
Yuki @ ICLR'24
@y_m_asano
3,422
Followers
688
Following
130
Media
497
Statuses
Assistant Professor for Computer Vision and Machine Learning at the QUVA Lab, @UvA_Amsterdam . Previously @Oxford_VGG , @OxfordAI , interned @facebookai
Joined July 2014
Don't wanna be here?
Send us removal request.