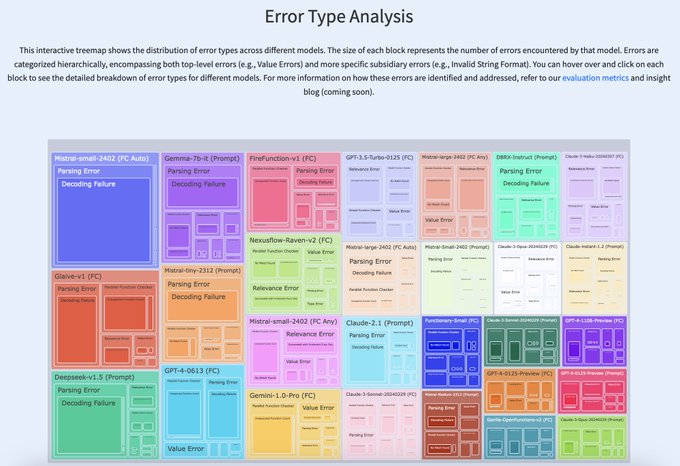
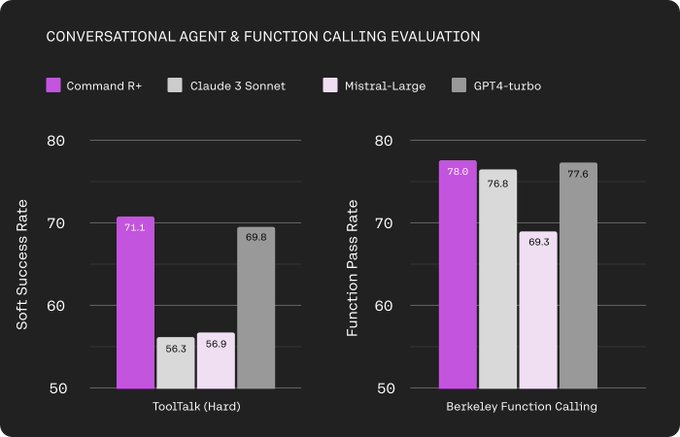
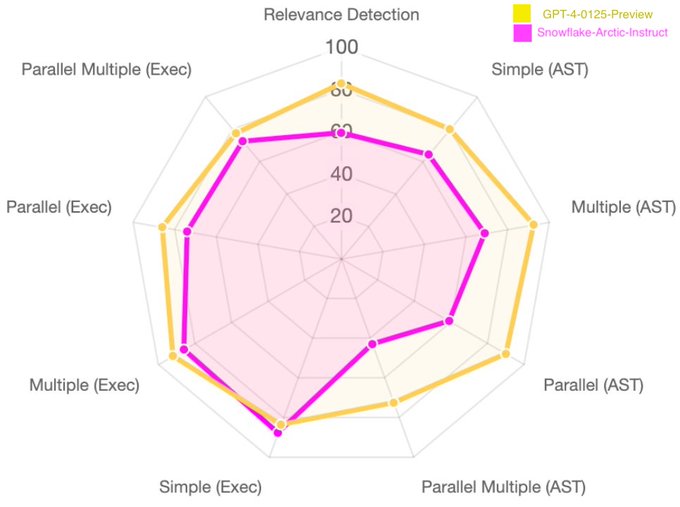
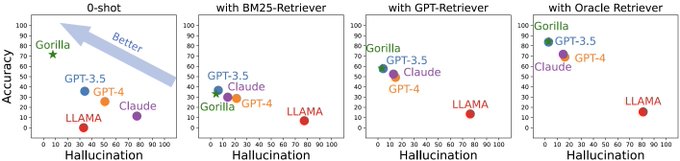
Shishir Patil
@shishirpatil_
2,859
Followers
854
Following
27
Media
193
Statuses
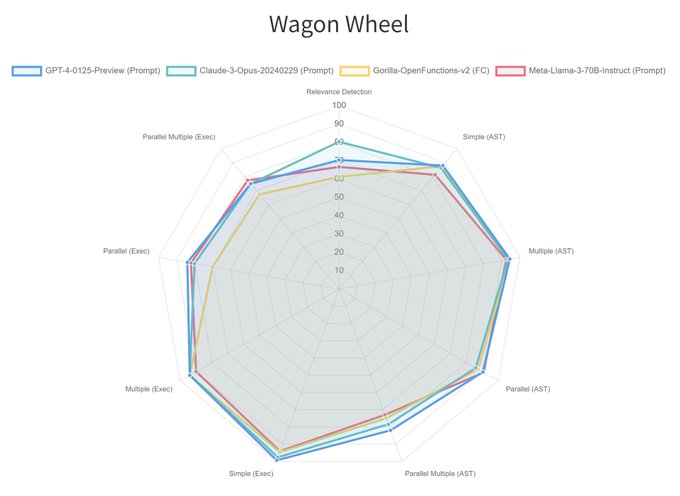
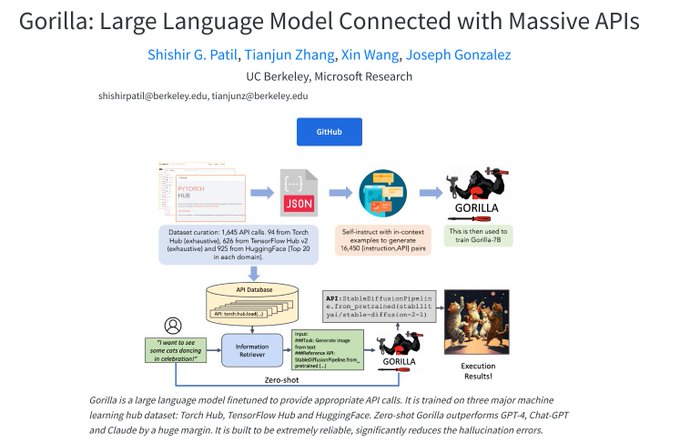
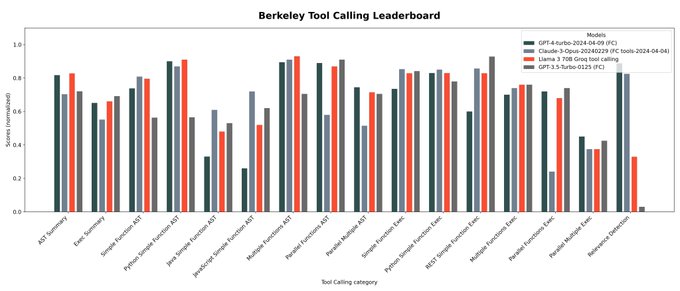
CS PhD @ UC Berkeley. Creator of Gorilla, GoEx, RAFT, OpenFunctions and Berkeley Function Calling Leaderboard. Previously researcher @GoogleAI @MSFTResearch
Don't wanna be here?
Send us removal request.