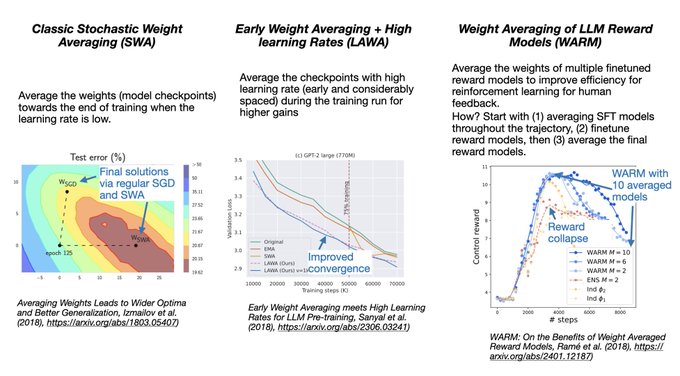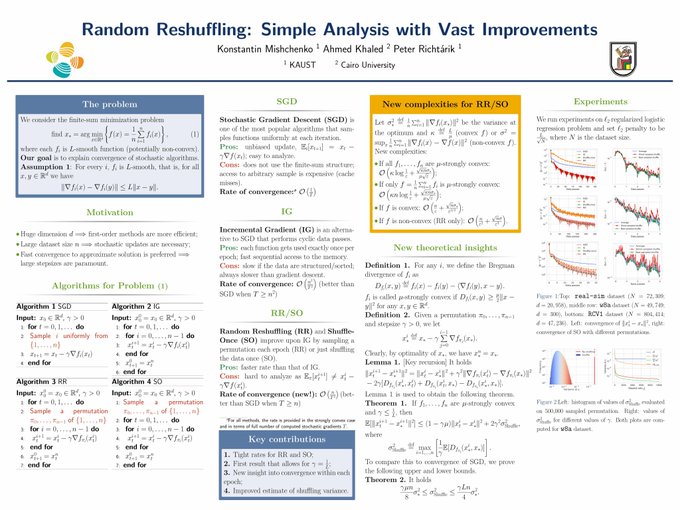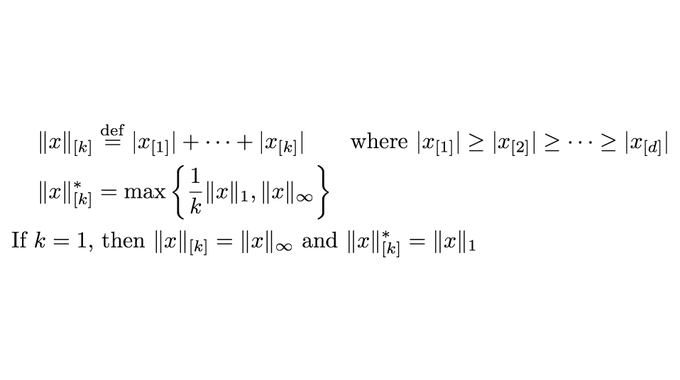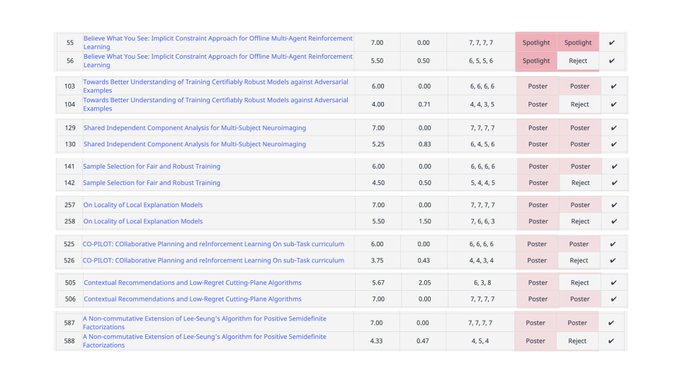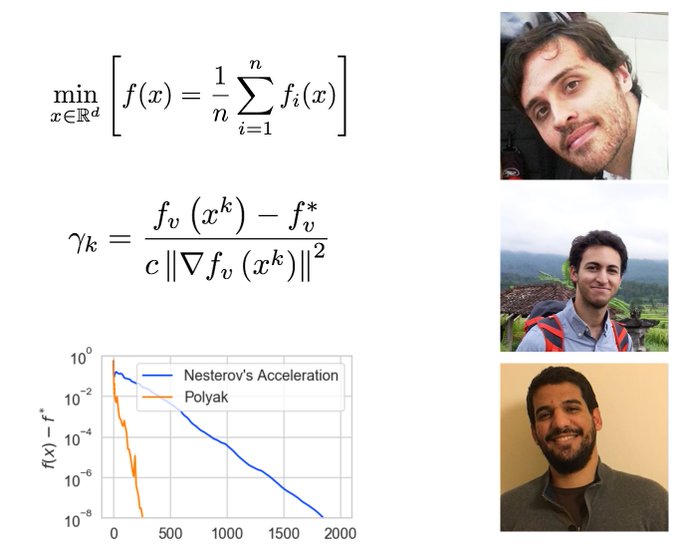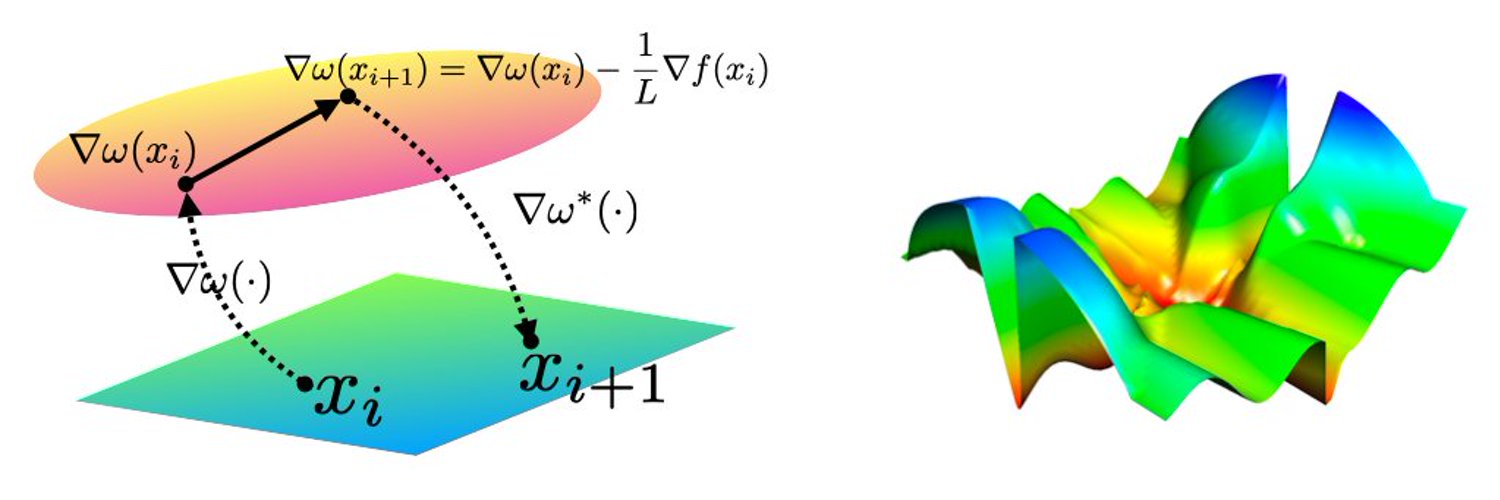

Konstantin Mishchenko
@konstmish
4,324
Followers
563
Following
129
Media
511
Statuses
Research Scientist at Samsung AI Center Outstanding Paper Award @icmlconf 2023 Action Editor @TmlrOrg I tweet about ML papers and math
Don't wanna be here?
Send us removal request.