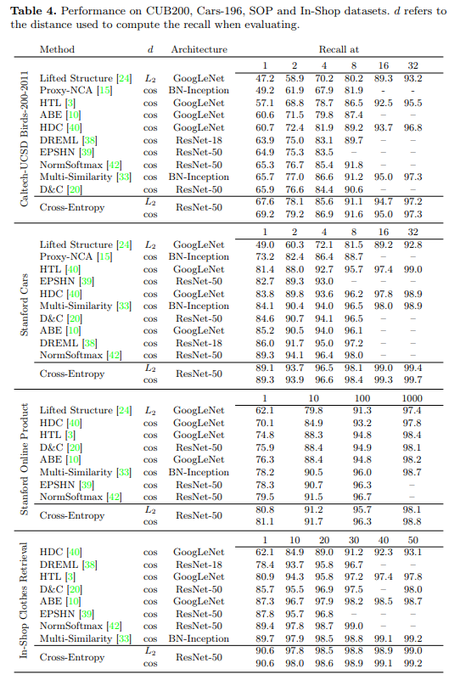
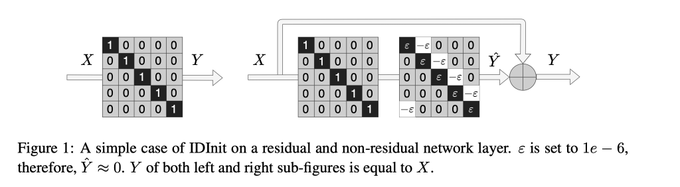
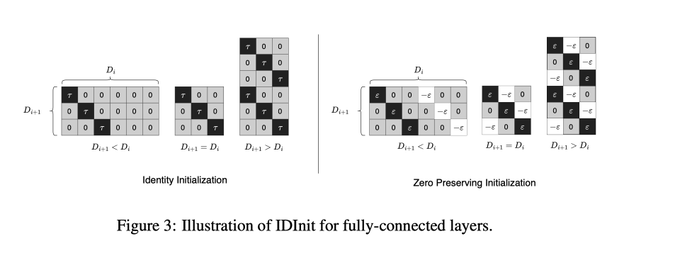
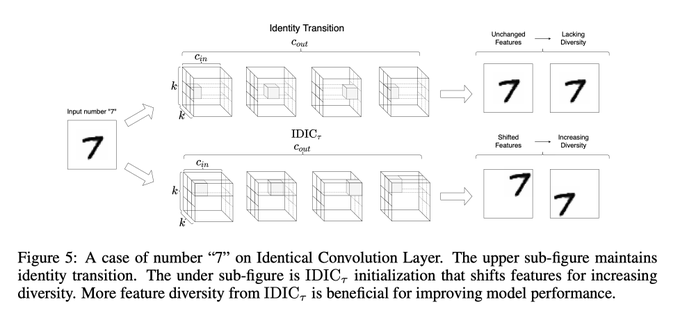
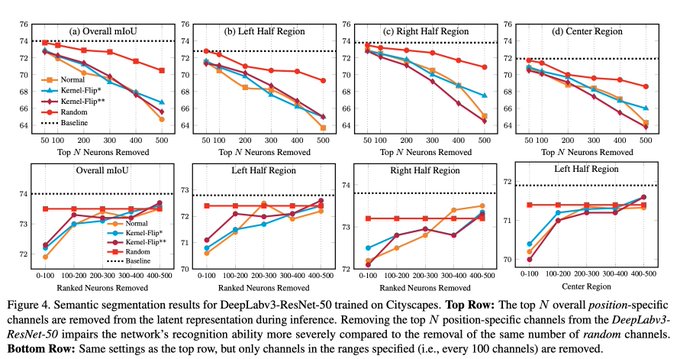
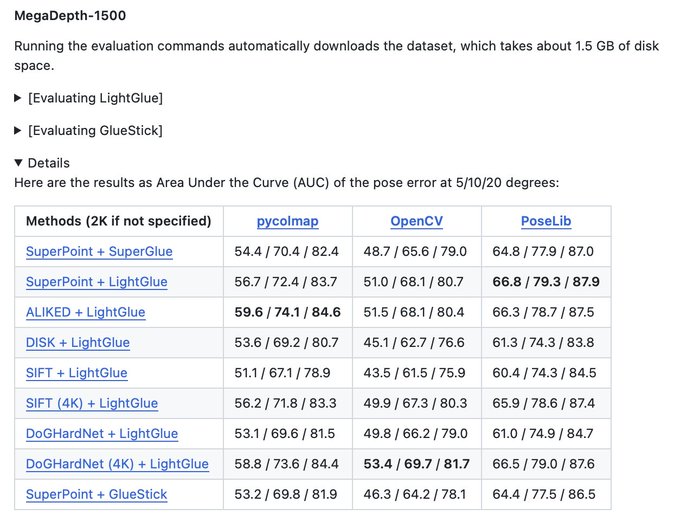
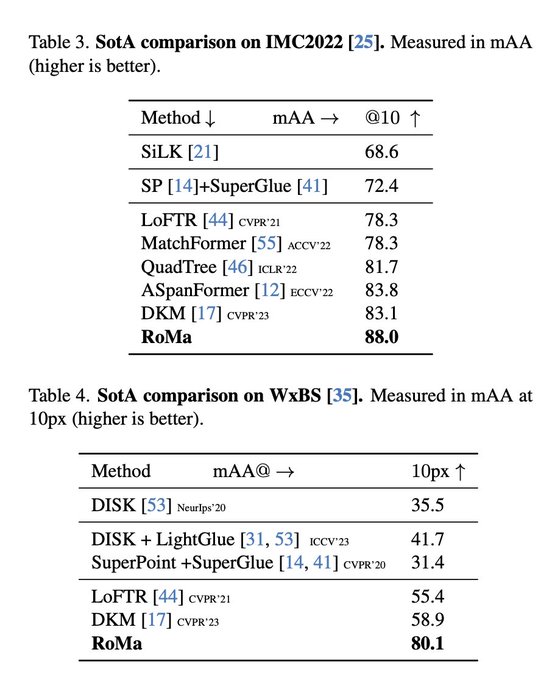
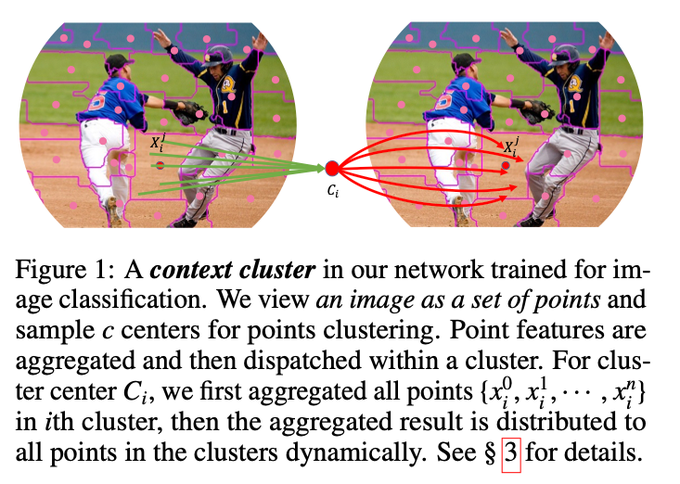
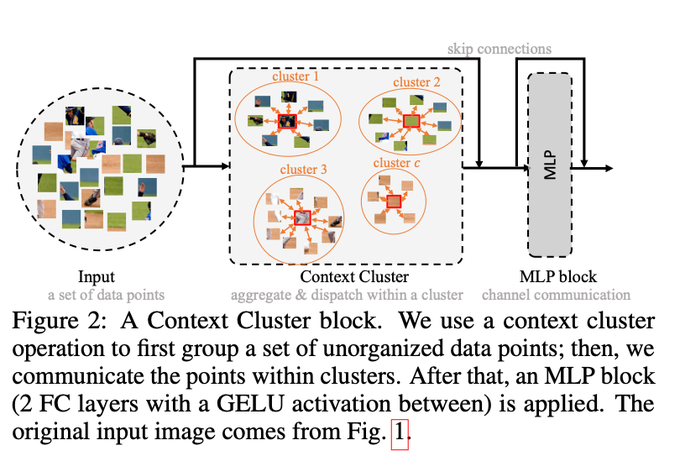
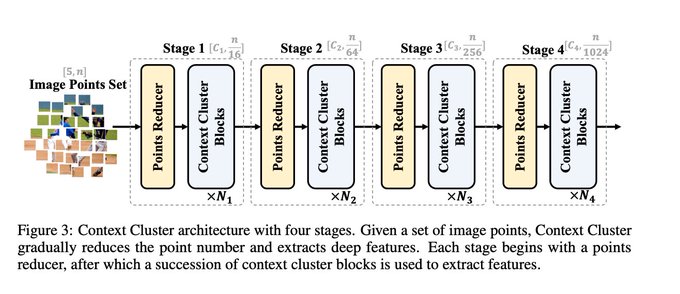
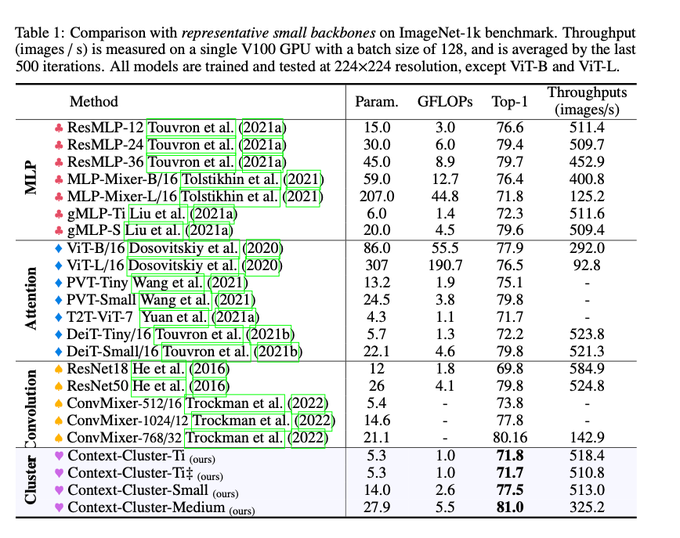
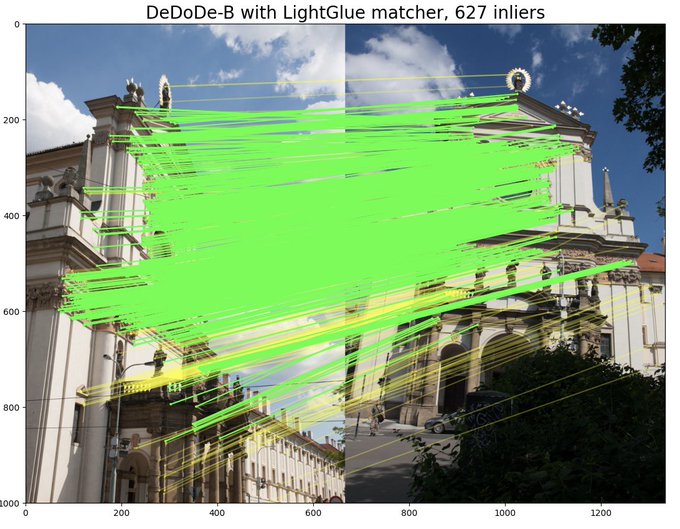
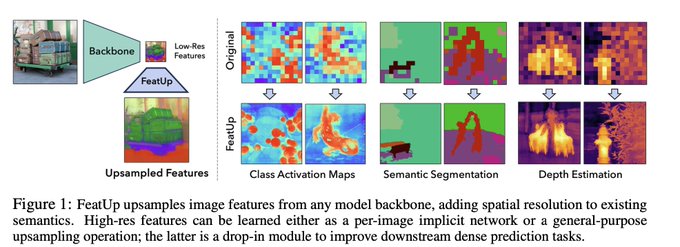
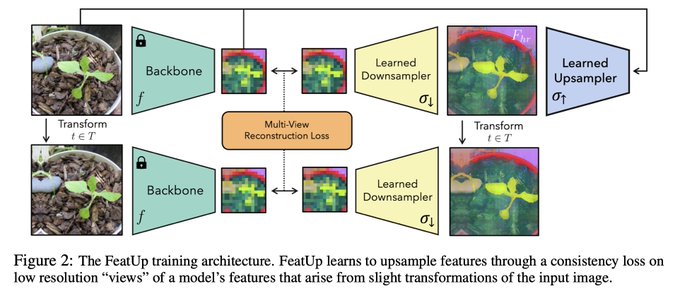
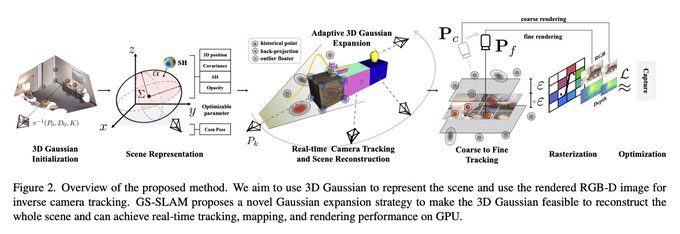
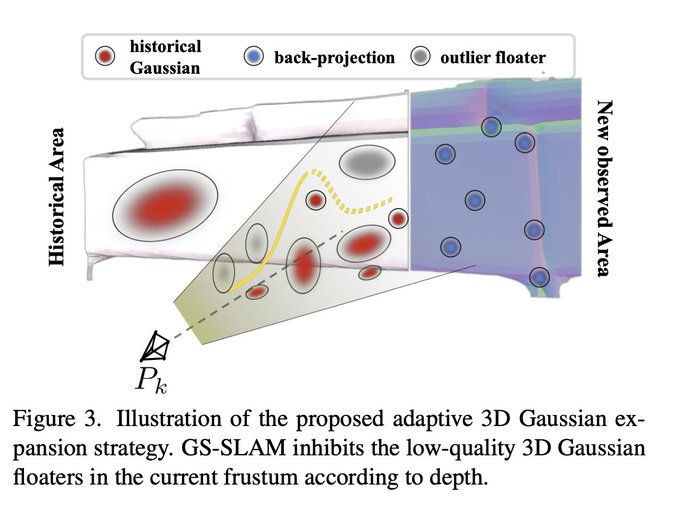
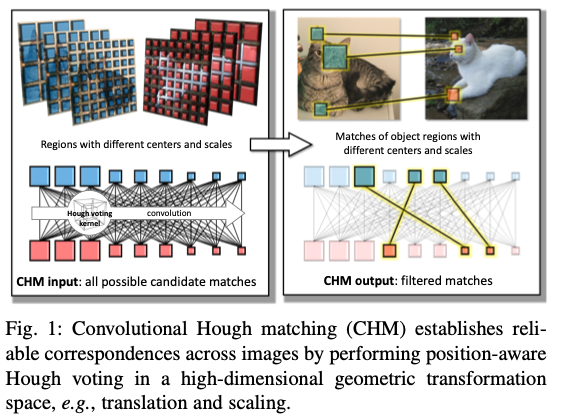
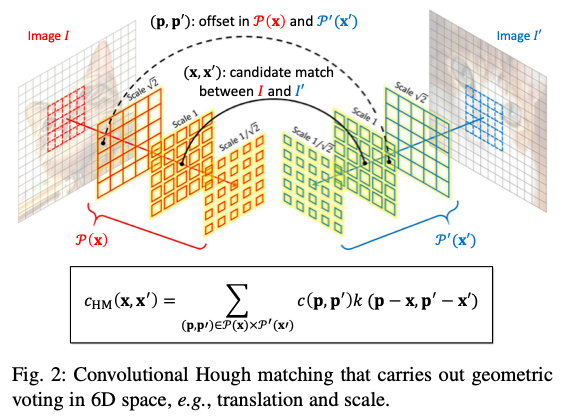
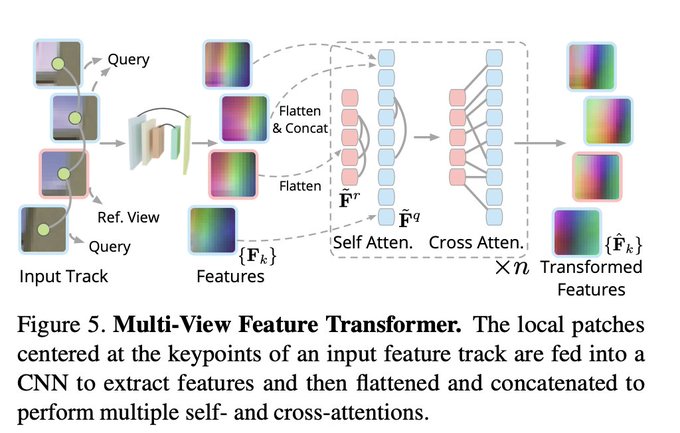
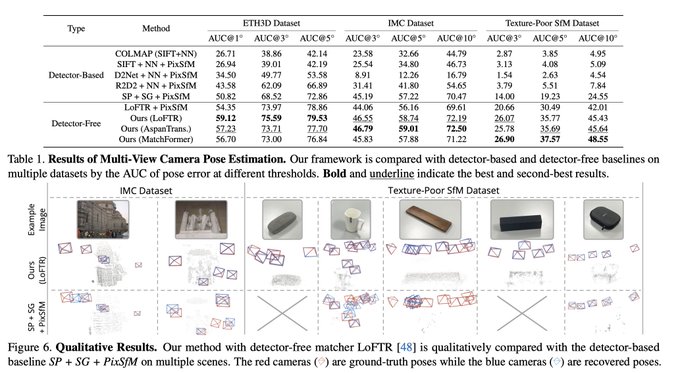
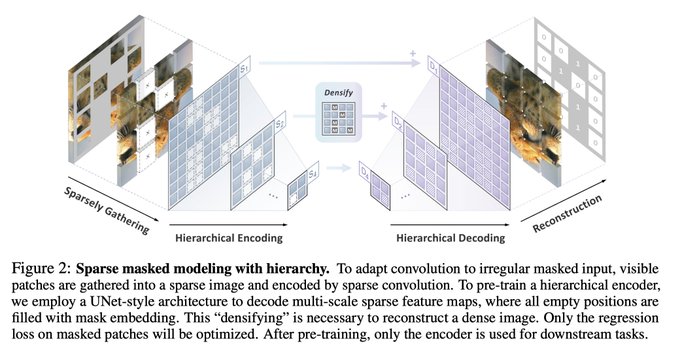
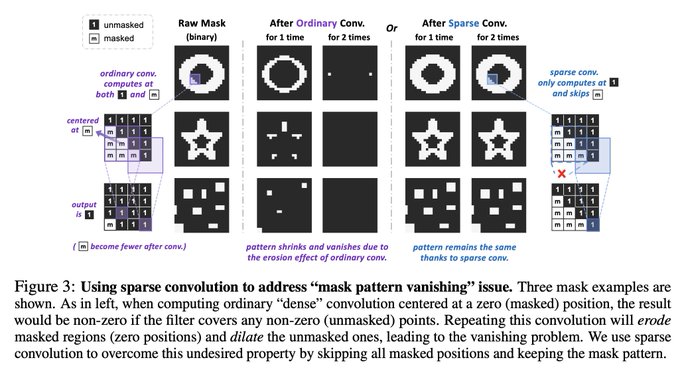
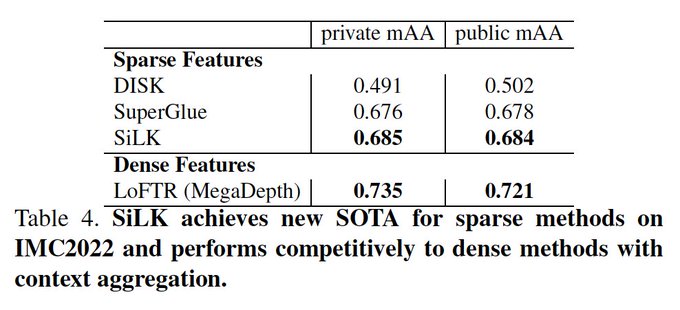
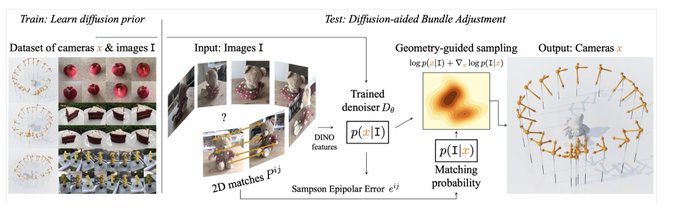
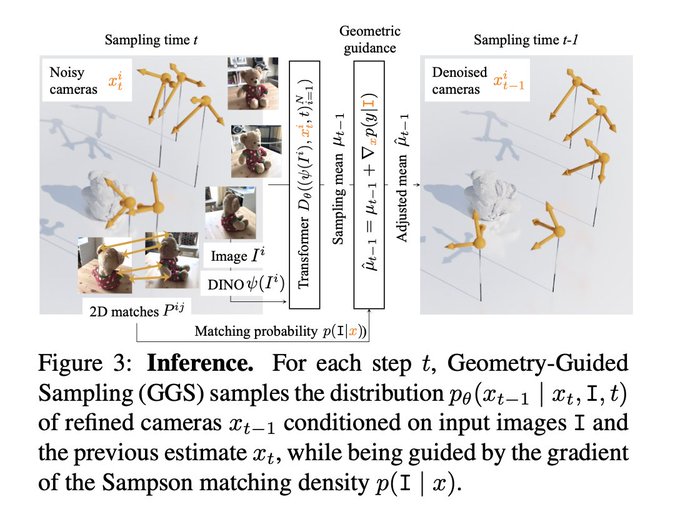
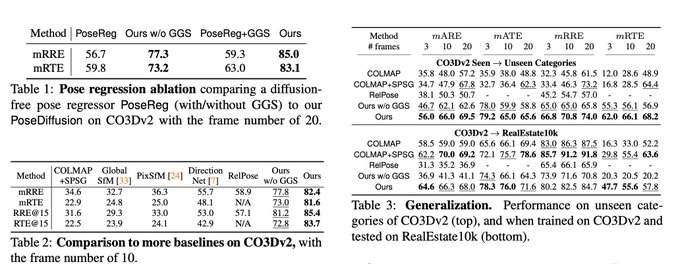
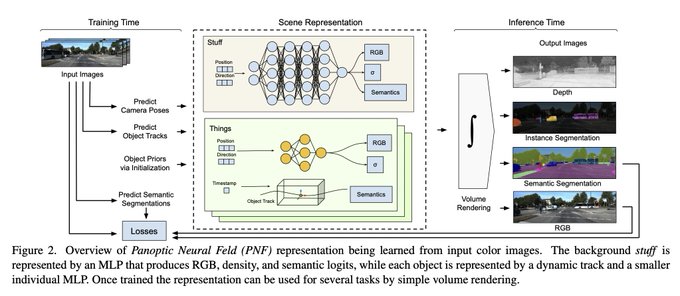
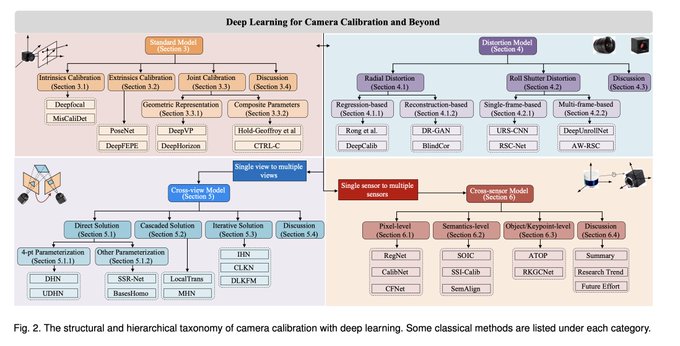
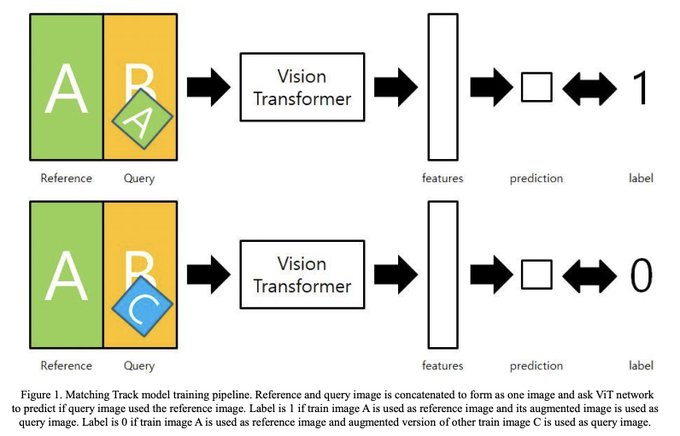
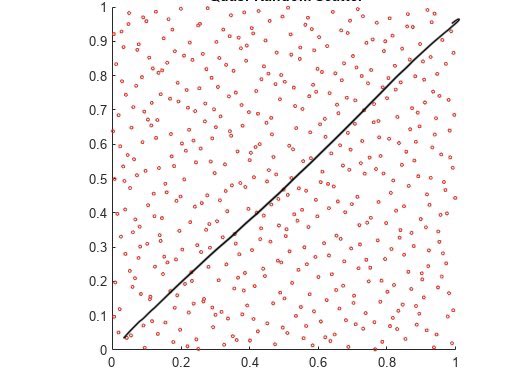
Dmytro Mishkin 🇺🇦
@ducha_aiki
18,326
Followers
591
Following
3,285
Media
17,421
Statuses
Marrying classical CV and Deep Learning. I do things, which work, rather than being novel, but not working.
Don't wanna be here?
Send us removal request.