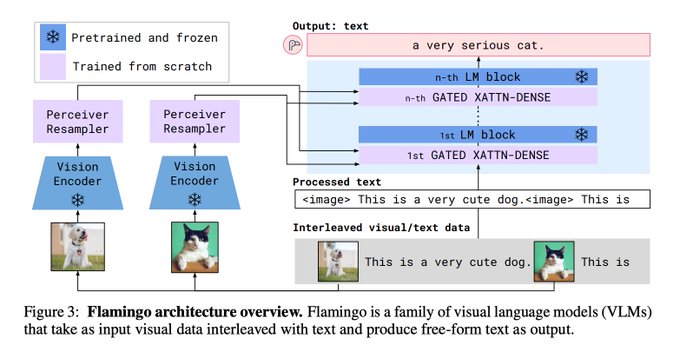
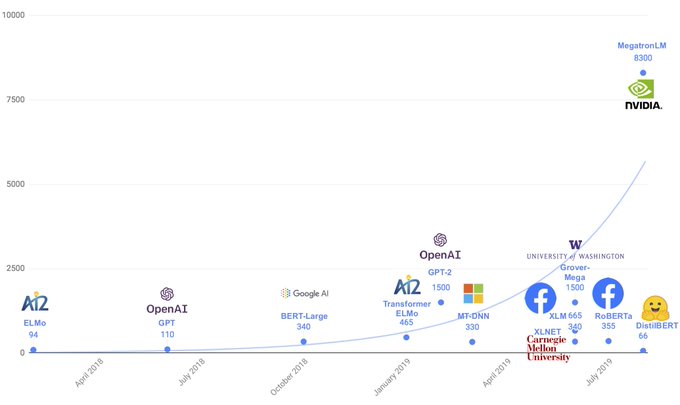
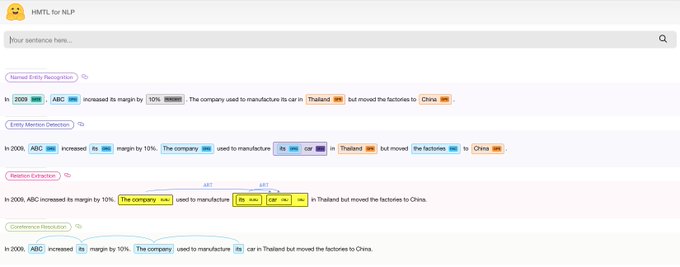
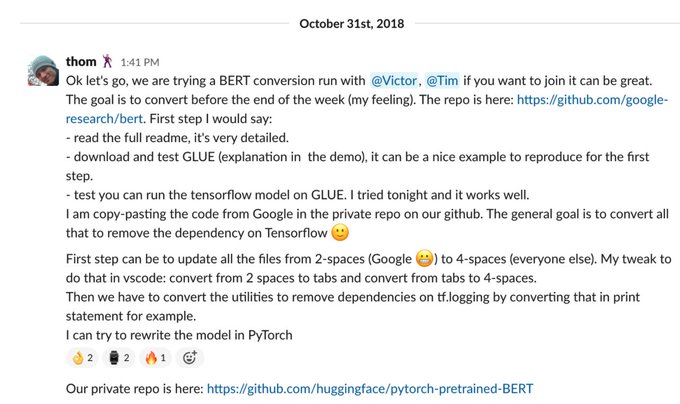
Victor Sanh
@SanhEstPasMoi
8,582
Followers
2,369
Following
188
Media
2,320
Statuses
Dog sitter by day, Scientist at @huggingface 🤗 by night
New York City
Joined May 2012
Don't wanna be here?
Send us removal request.