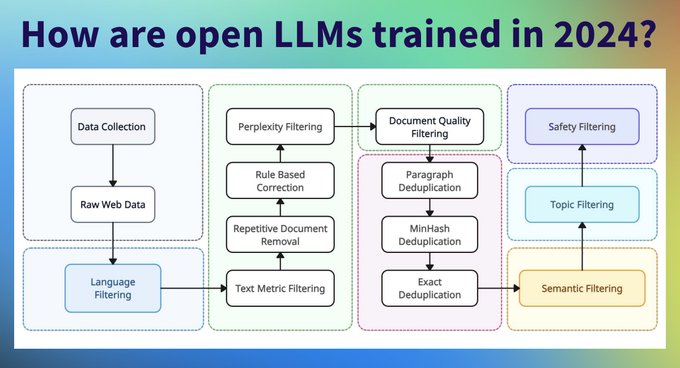
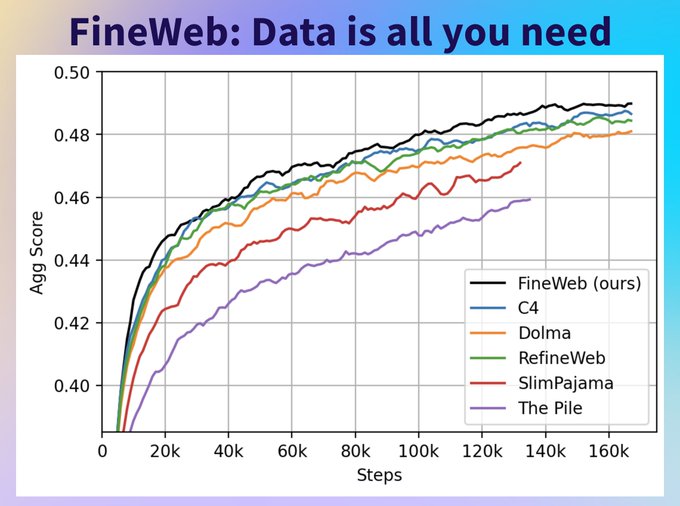
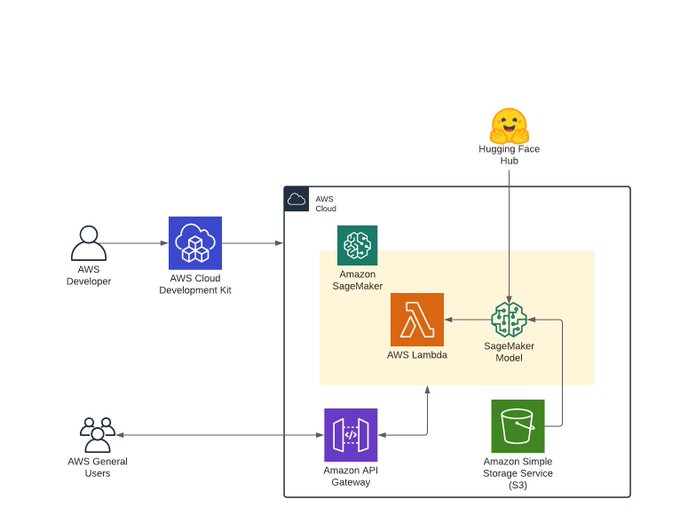
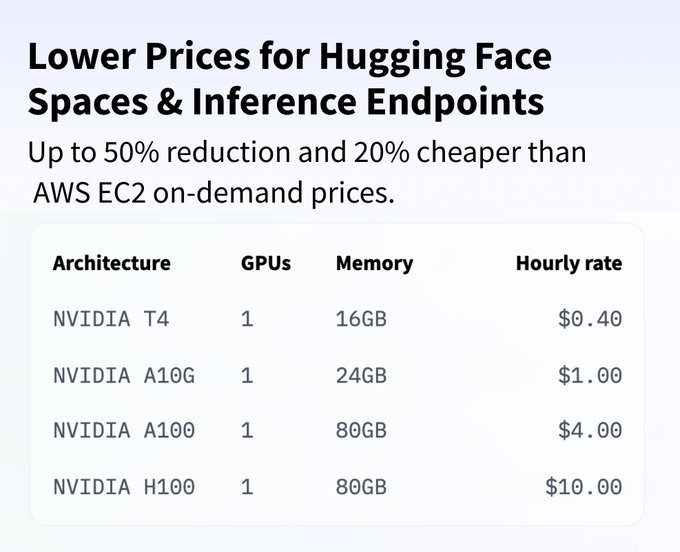
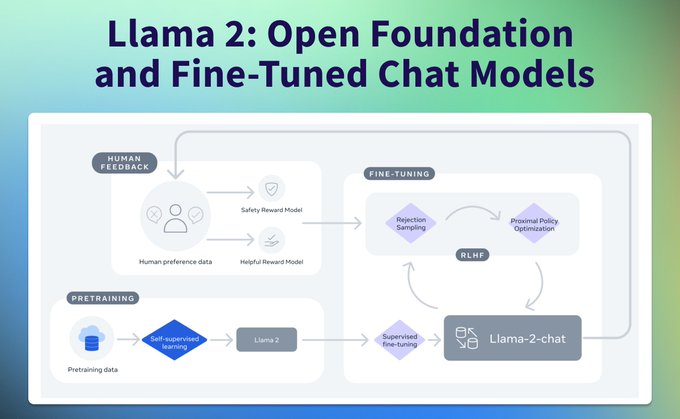
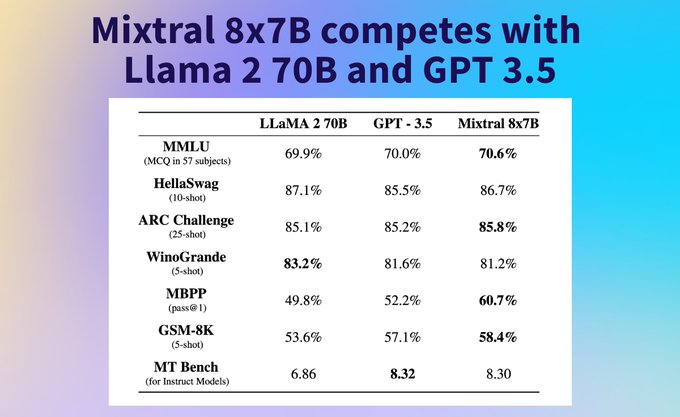
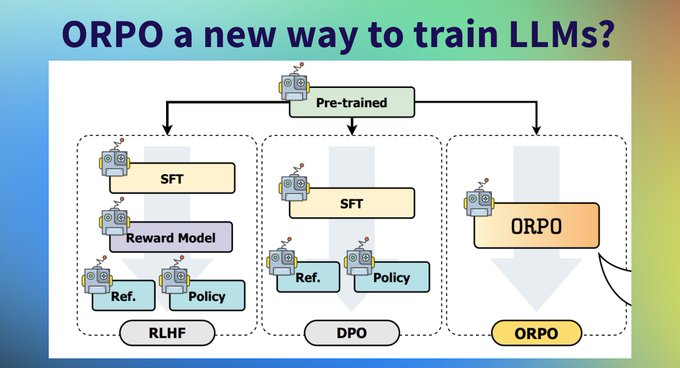
Philipp Schmid
@_philschmid
16,404
Followers
658
Following
462
Media
1,856
Statuses
Tech Lead and LLMs at @huggingface 👨🏻💻 🤗 AWS ML Hero 🦸🏻 | Cloud & ML enthusiast | 📍Nuremberg | 🇩🇪
Don't wanna be here?
Send us removal request.