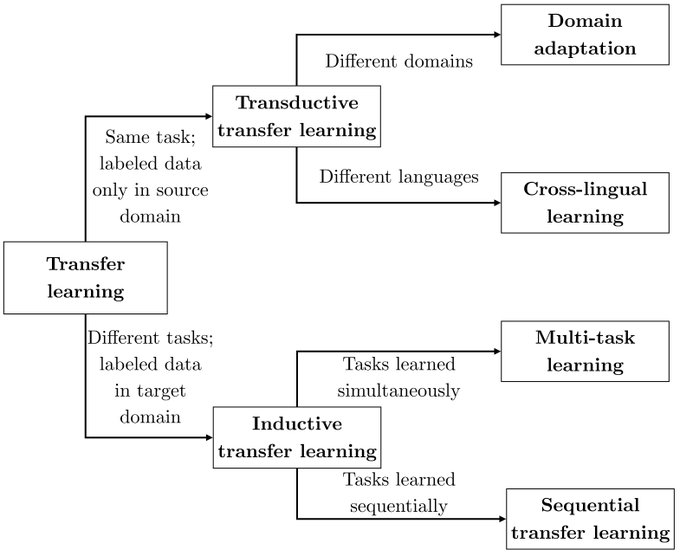
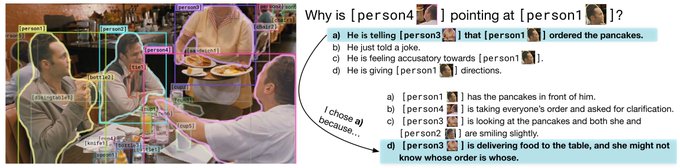
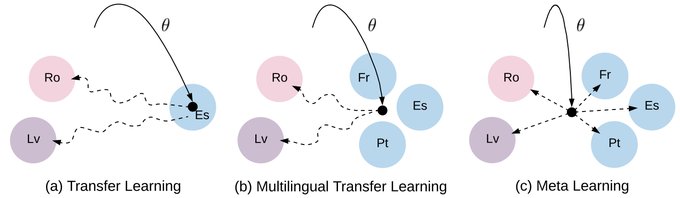
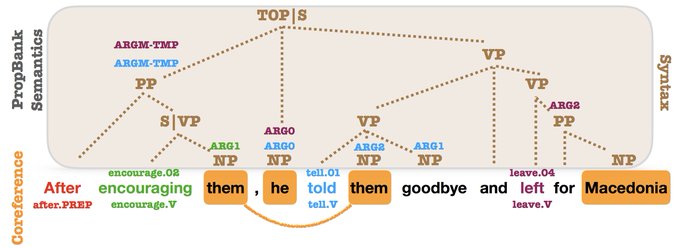
Sebastian Ruder
@seb_ruder
80,543
Followers
1,460
Following
365
Media
4,268
Statuses
Multilingual LLMs @cohere • Prev: @GoogleDeepMind • Newsletter:
Don't wanna be here?
Send us removal request.