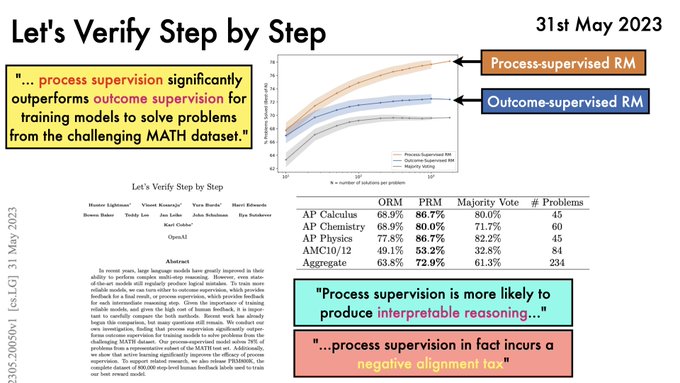
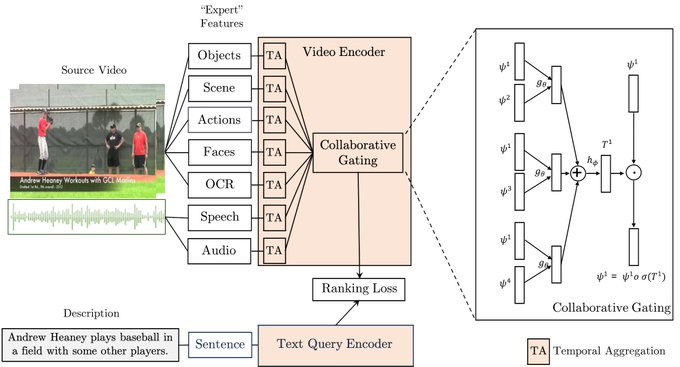
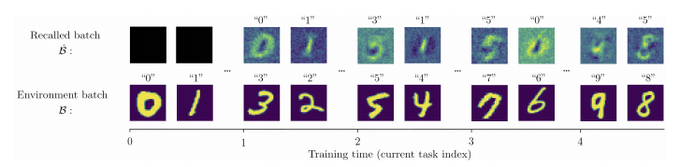
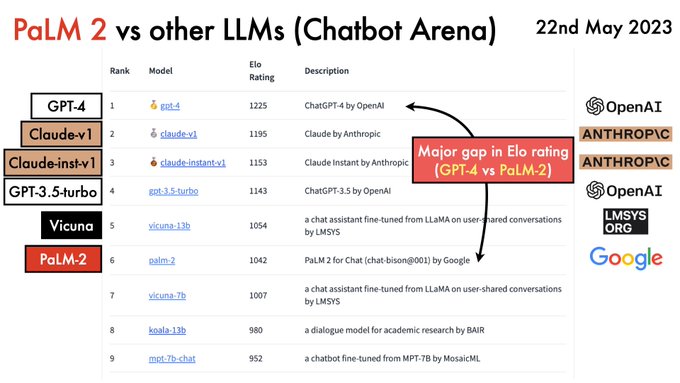
Samuel Albanie
@SamuelAlbanie
3,066
Followers
493
Following
302
Media
479
Statuses
Assistant prof. @Cambridge_Uni
Don't wanna be here?
Send us removal request.