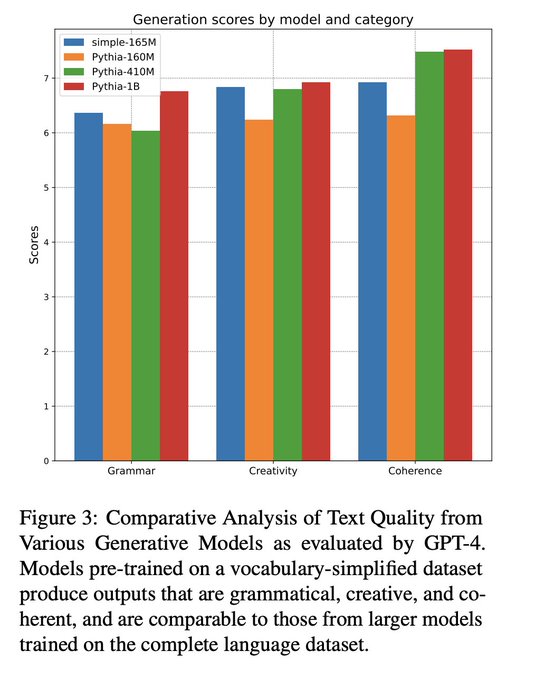
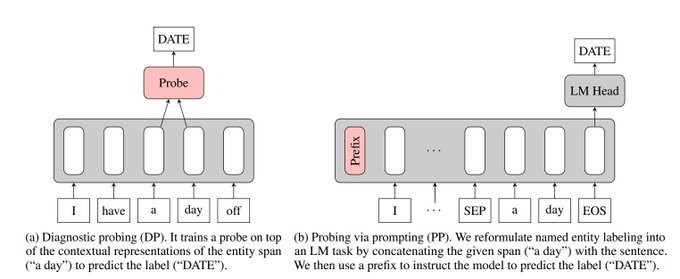
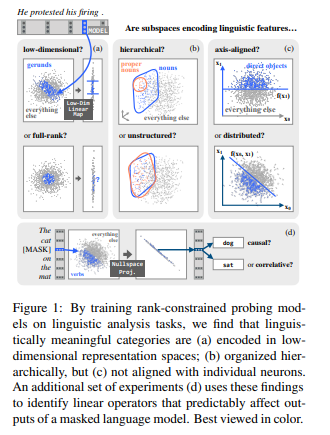
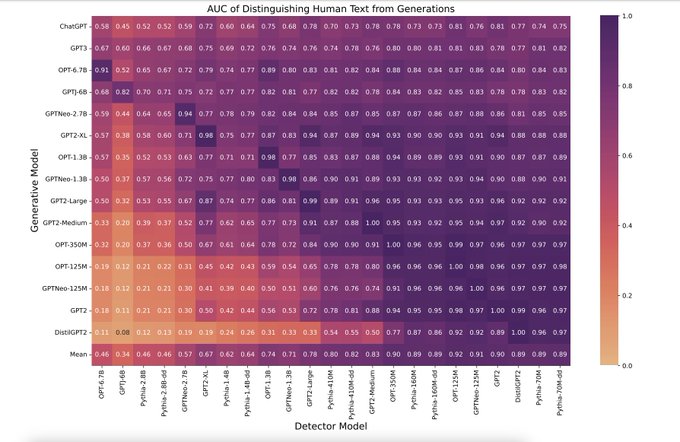
Leshem Choshen 🤖🤗
@LChoshen
3,590
Followers
589
Following
632
Media
7,490
Statuses
🥇 Collaborative LLMs 🥈 Opinionatedly sharing #ML & #NLP 🥉 Propagating us underdogs we owe science an alternative hype @IBMResearch & @MIT_CSAIL
Don't wanna be here?
Send us removal request.