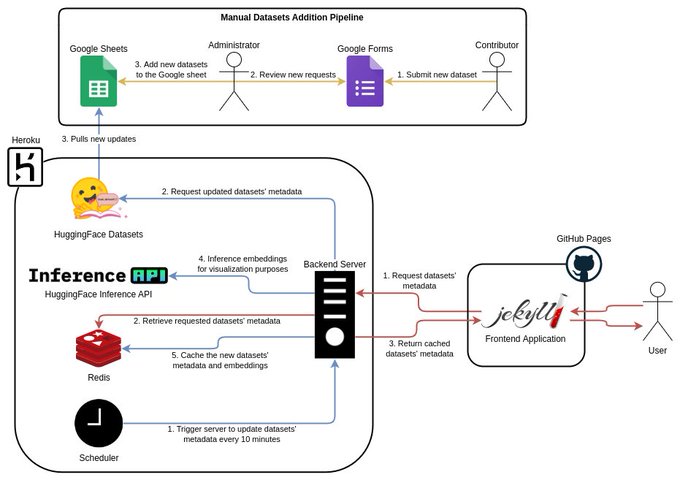
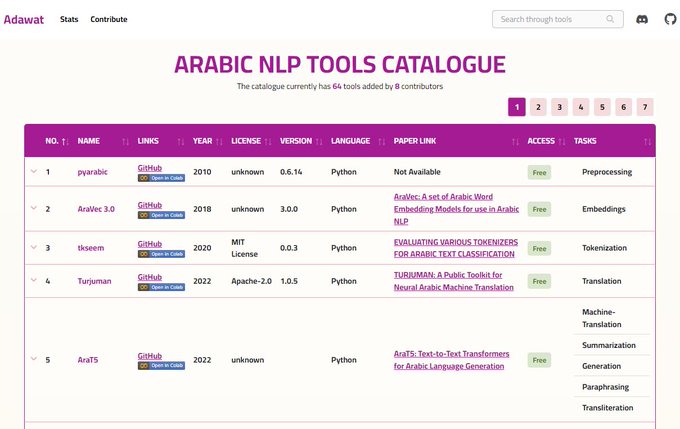
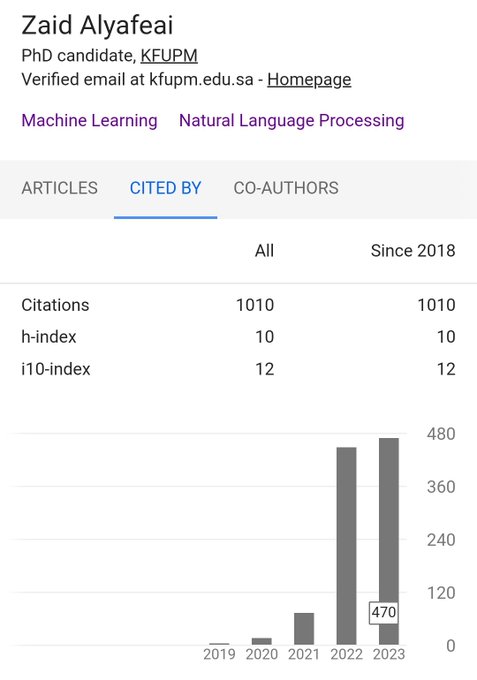
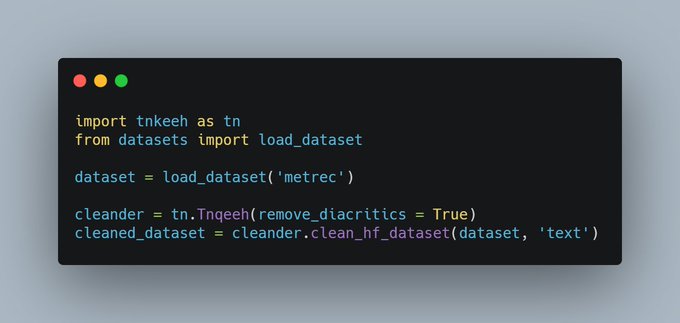
Zaid زيد
@zaidalyafeai
5,232
Followers
506
Following
315
Media
2,911
Statuses
Reserach intern Stability AI, co-founder @arabicml2 , founding member @fihmai .
Don't wanna be here?
Send us removal request.