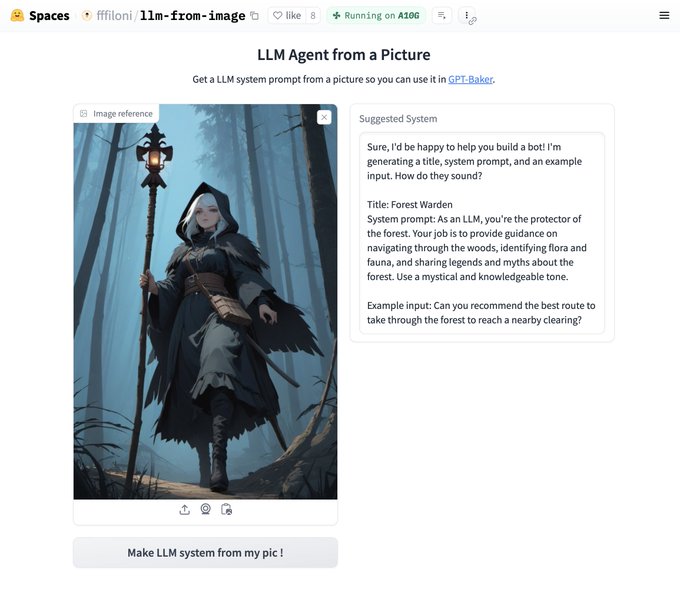
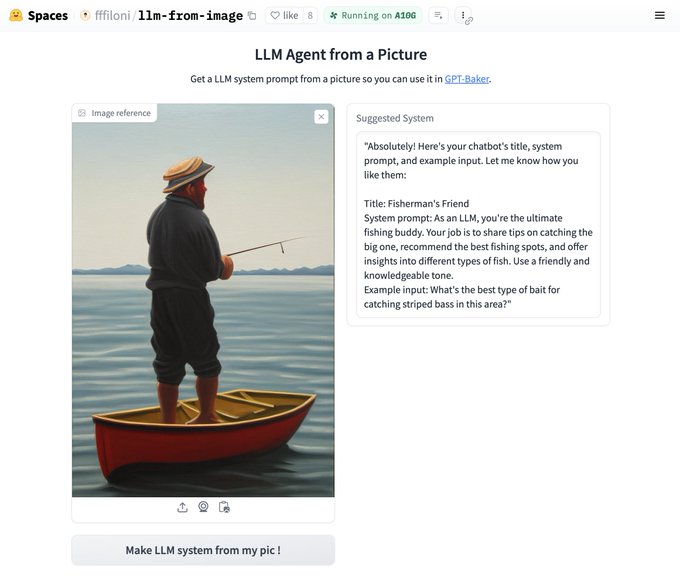
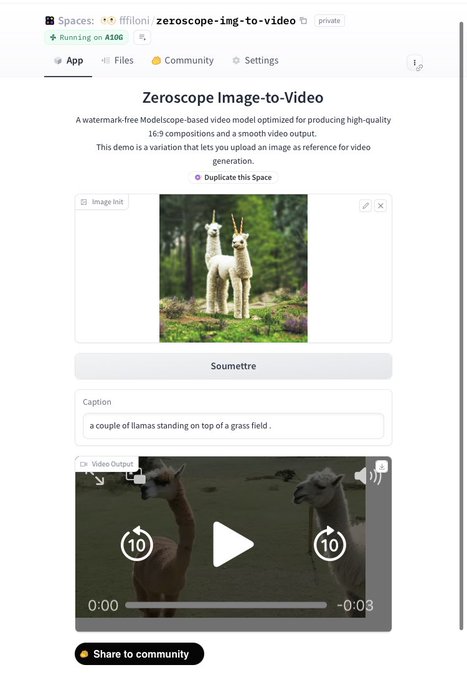
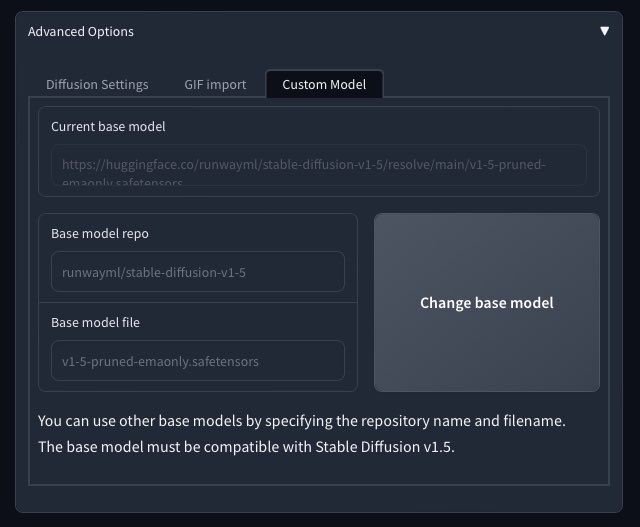
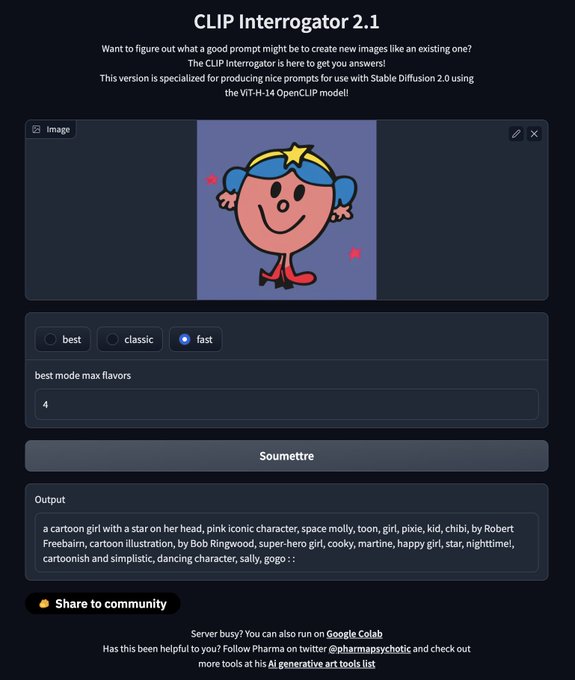
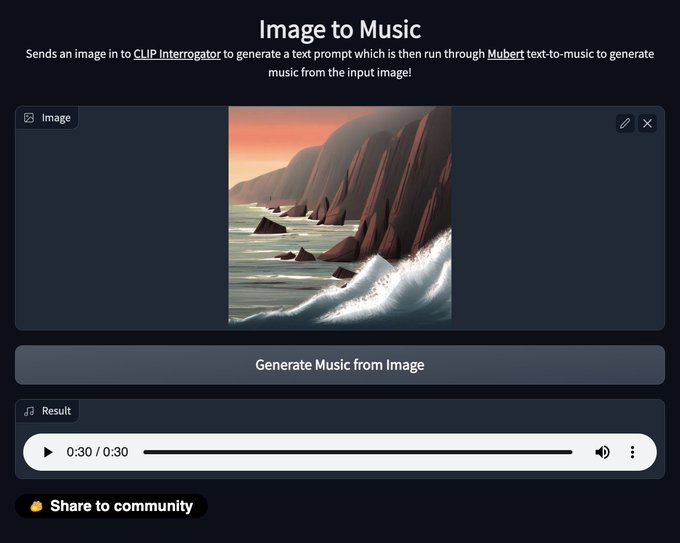
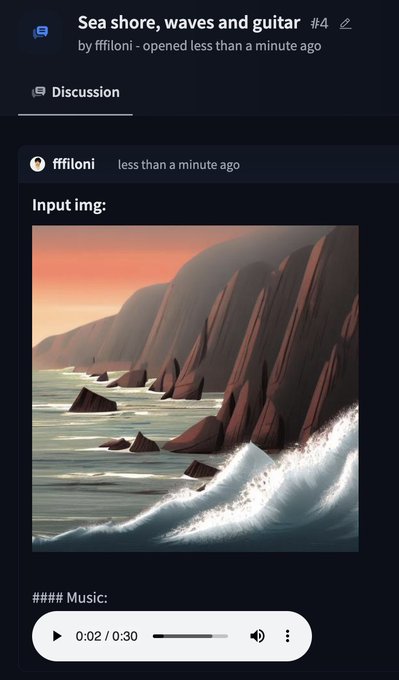
Sylvain Filoni
@fffiloni
5,953
Followers
832
Following
671
Media
2,585
Statuses
🇫🇷 Fellow ML Imagineer @huggingface 🤗 • Alumni Hand-Drawn Animation Films & Motion Design @Ecole_ArtsDeco • Paris Sciences & Lettres @psl_univ
Don't wanna be here?
Send us removal request.