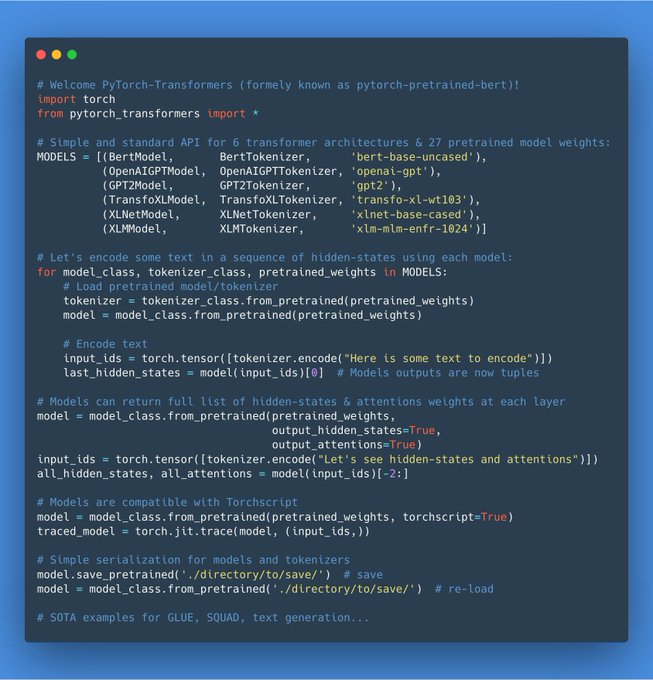
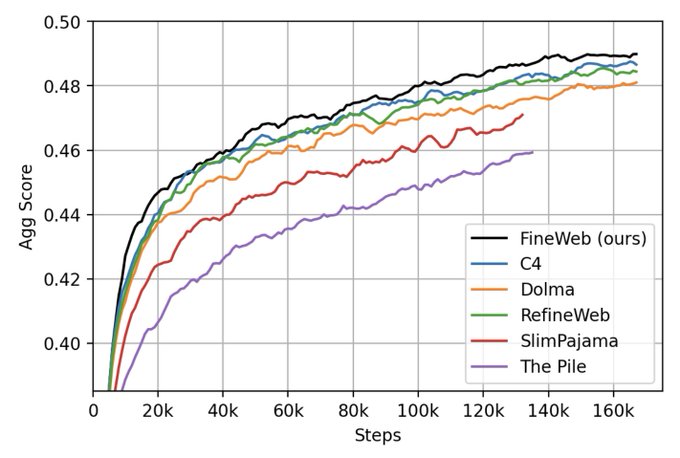
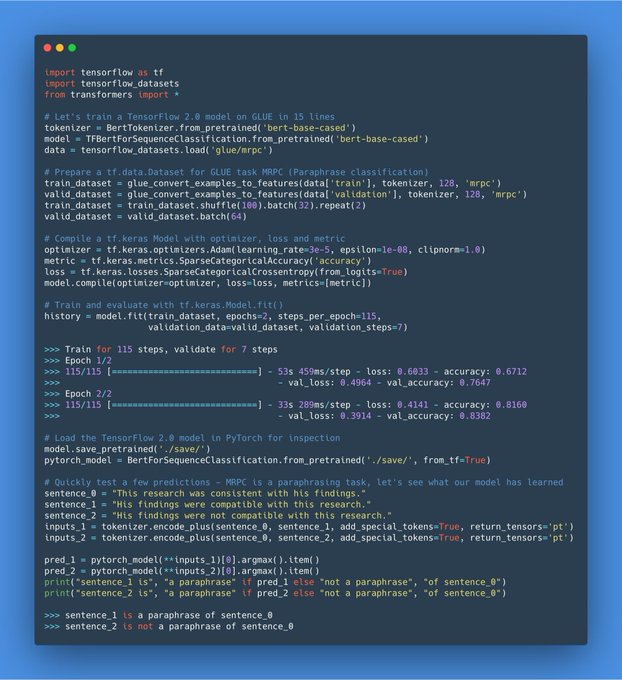
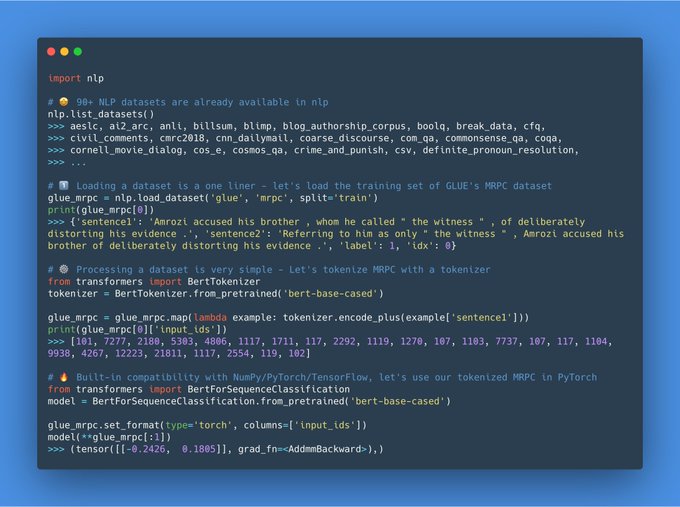
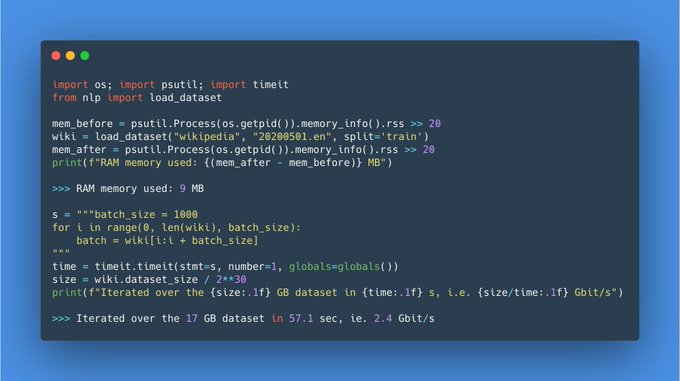
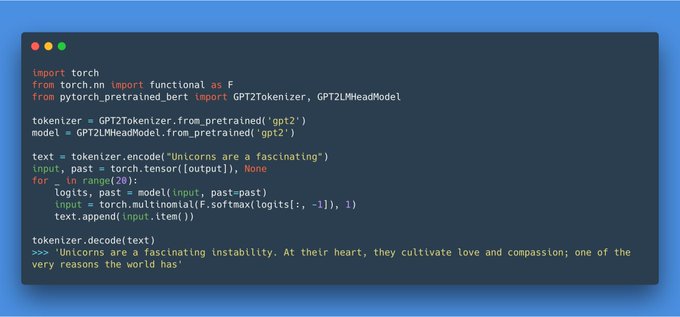
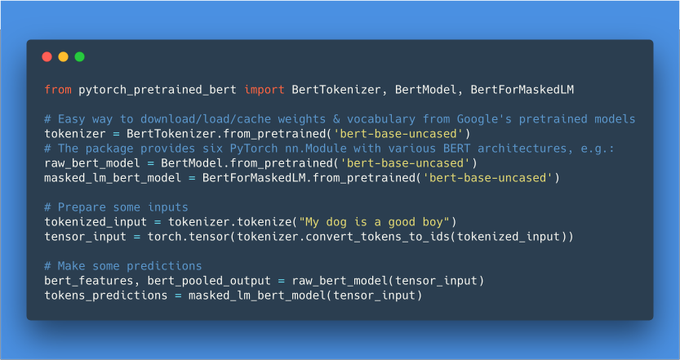
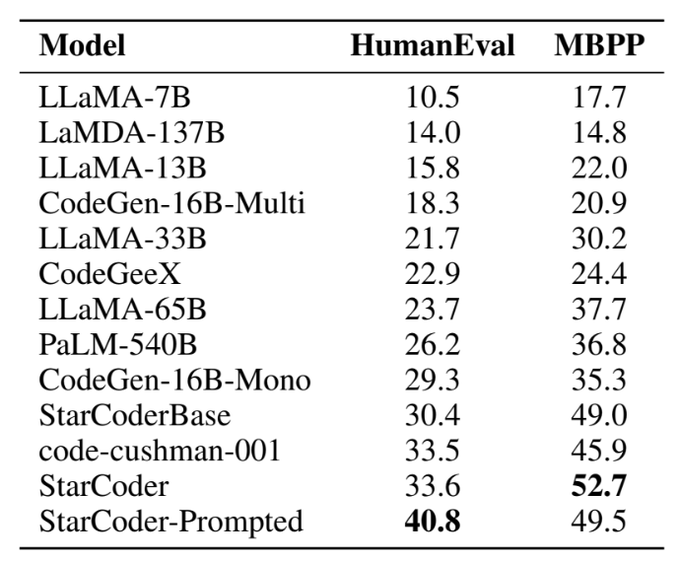
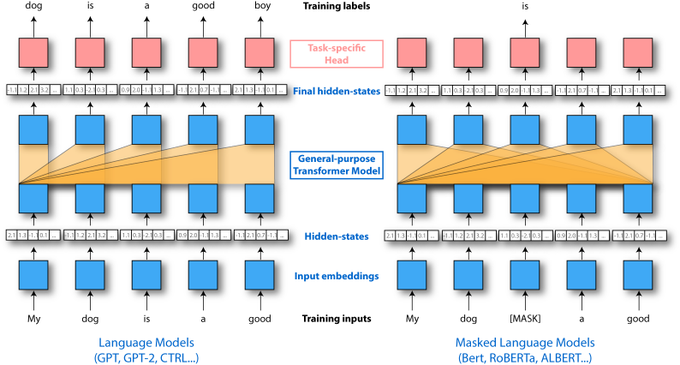
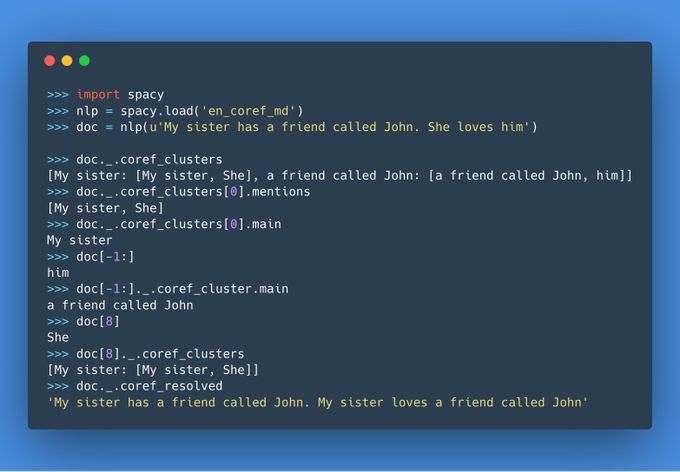
Thomas Wolf
@Thom_Wolf
68,313
Followers
4,341
Following
318
Media
3,572
Statuses
Co-founder and CSO @HuggingFace - open-source and open-science
Joined February 2011
Don't wanna be here?
Send us removal request.