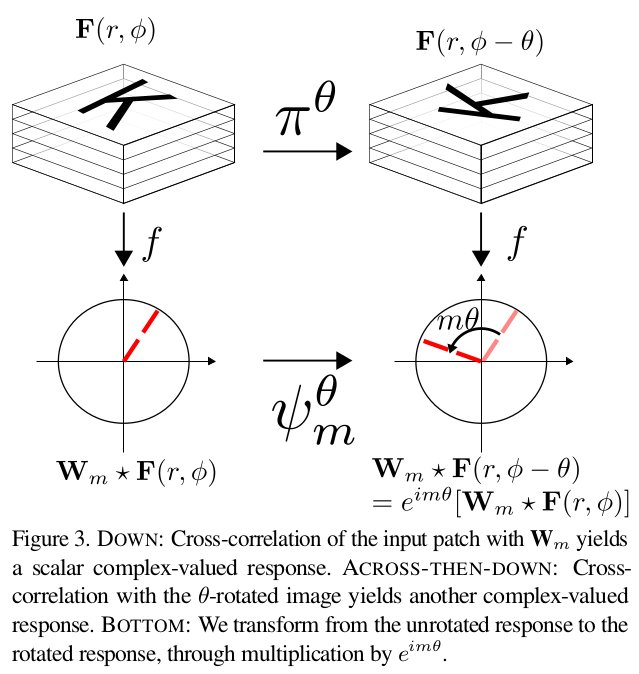
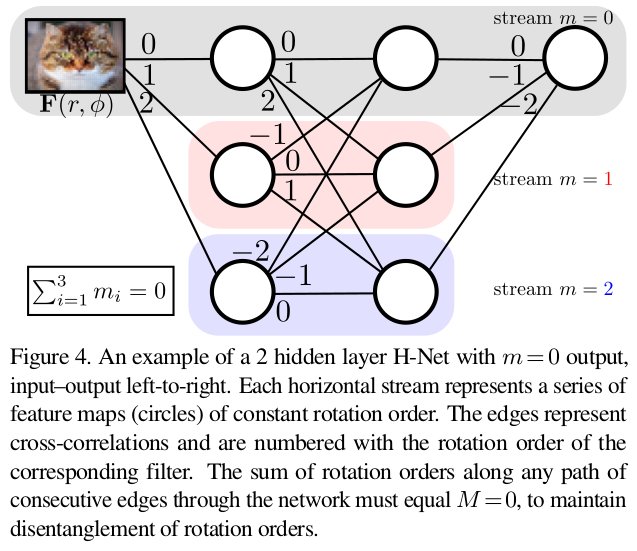
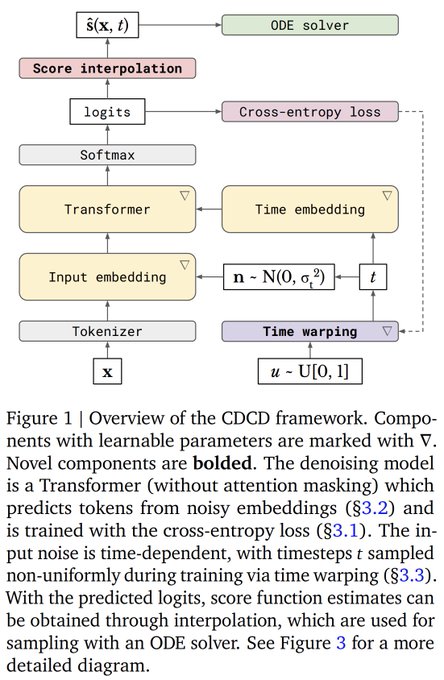
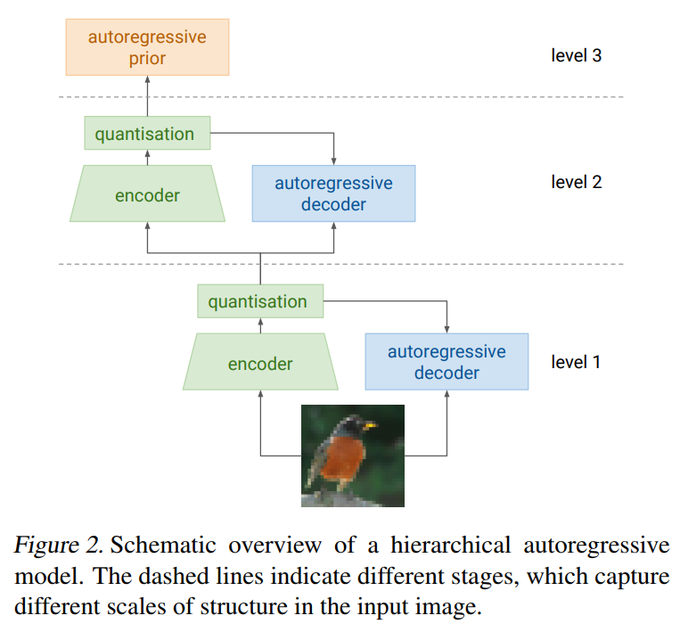
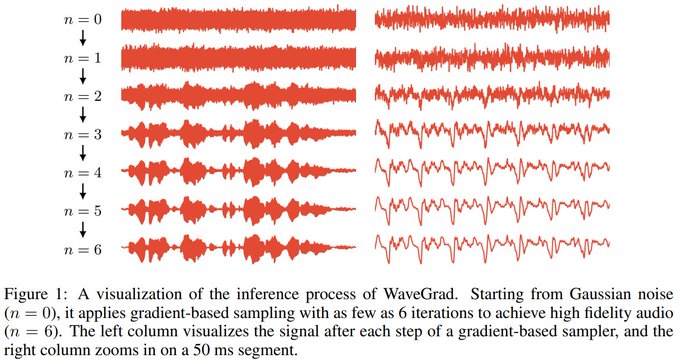
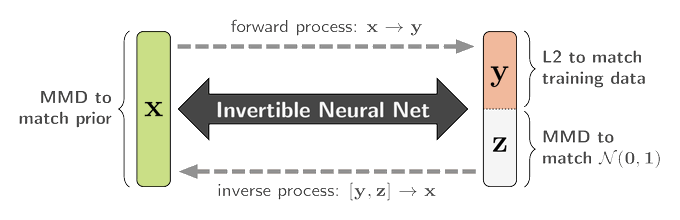
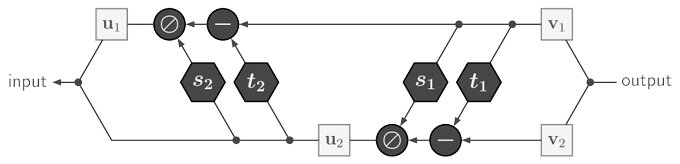
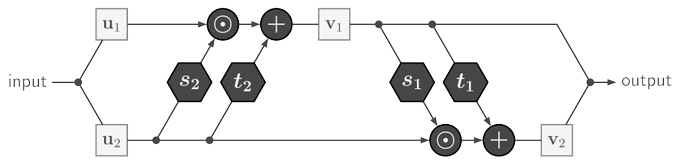
Sander Dieleman
@sedielem
50,525
Followers
1,541
Following
74
Media
1,848
Statuses
Research Scientist at Google DeepMind. I tweet about deep learning (research + software), music, generative models (personal account).
Don't wanna be here?
Send us removal request.