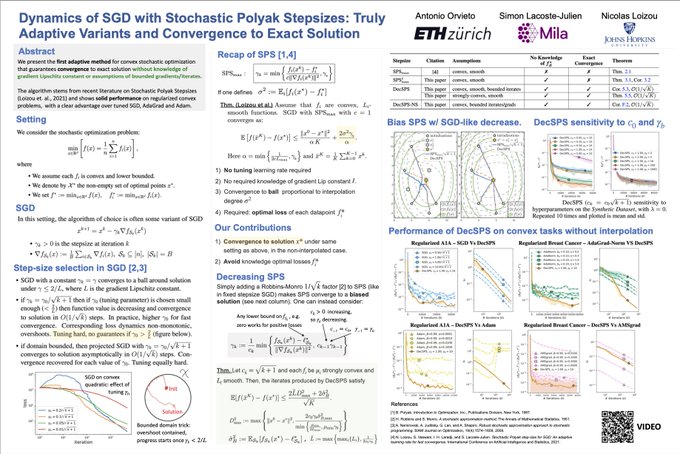
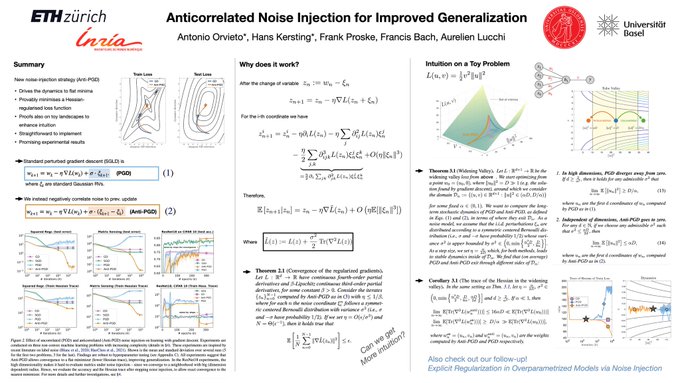
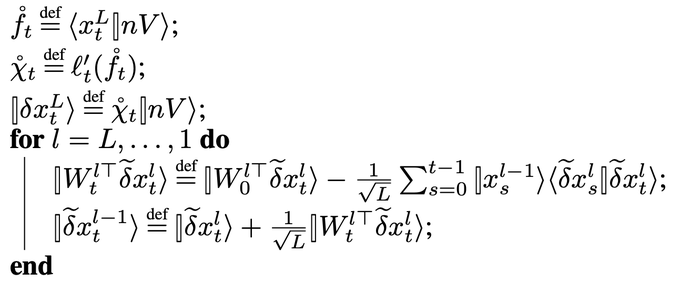Antonio Orvieto
@orvieto_antonio
1,456
Followers
1,118
Following
31
Media
212
Statuses
Deep Learning PI @ELLISInst_Tue , Group Leader @MPI_IS . I compute stuff with lots of gradients 🧮, I like Kierkegaard & Lévi-Strauss 🧙♂️
Don't wanna be here?
Send us removal request.