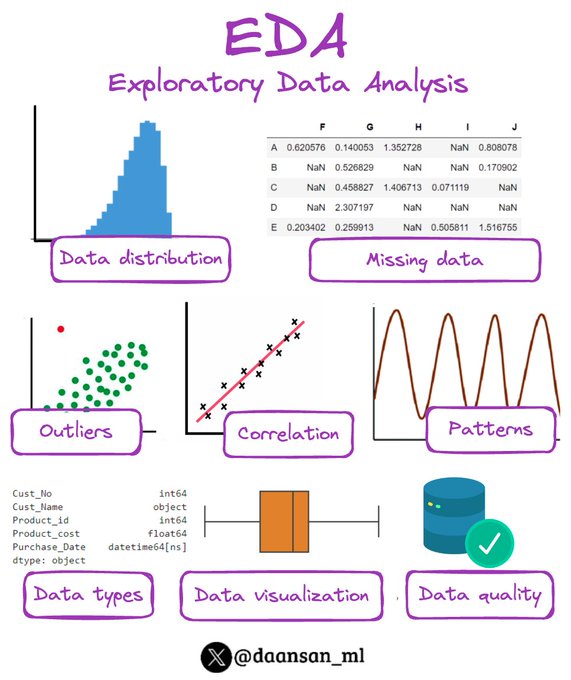
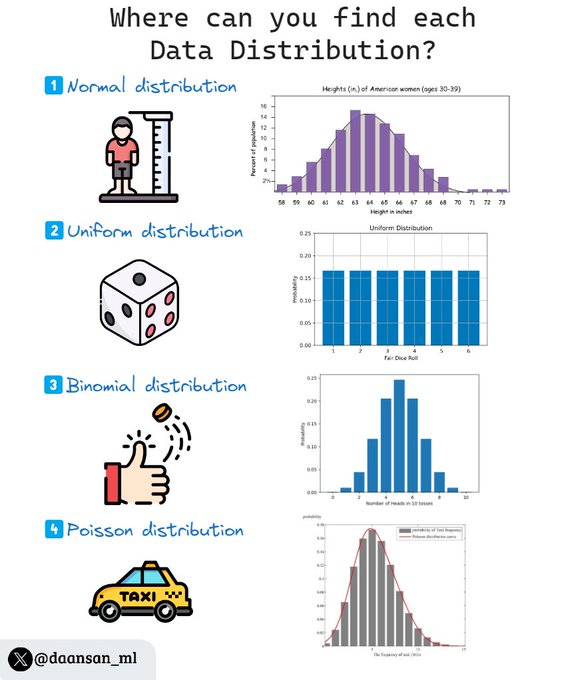
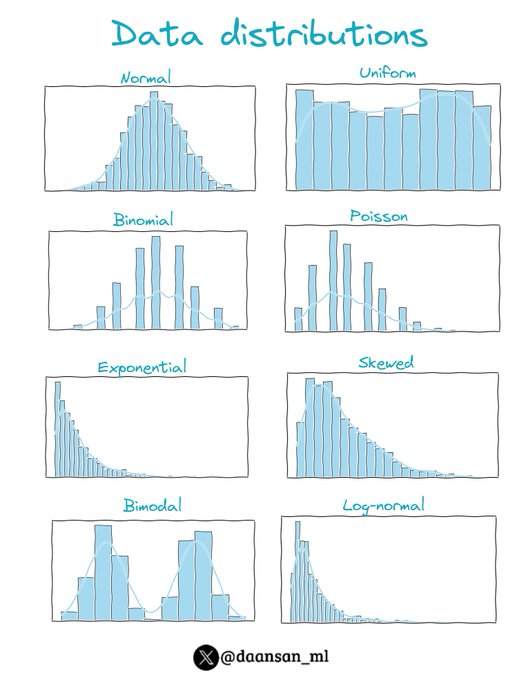
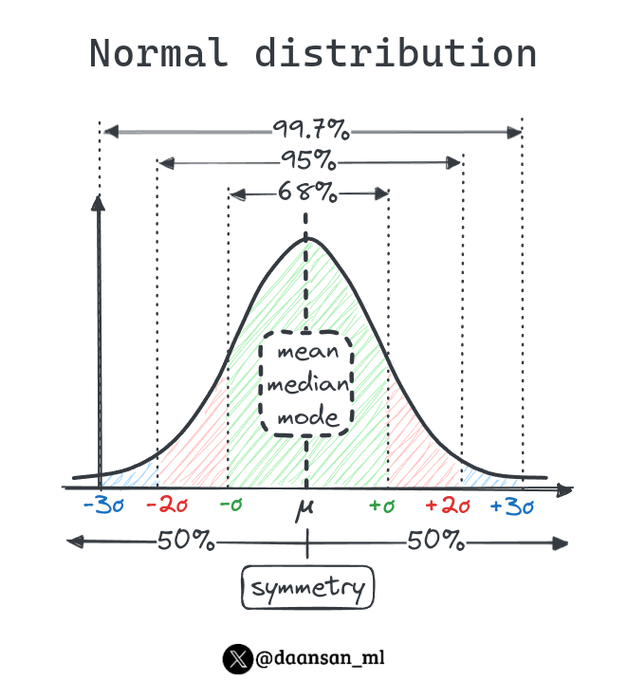
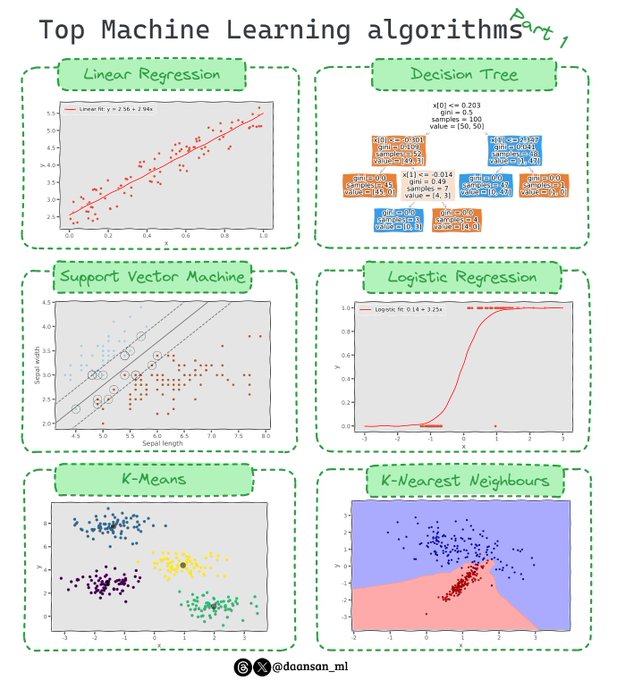
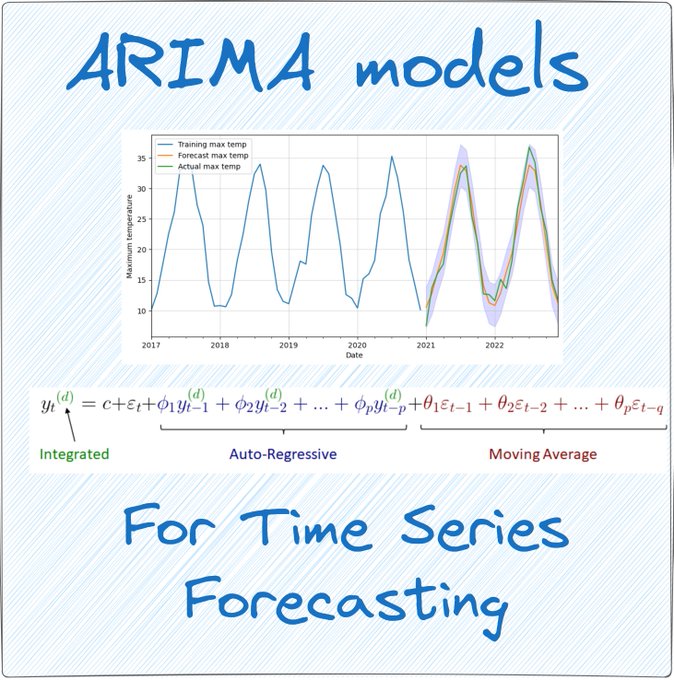
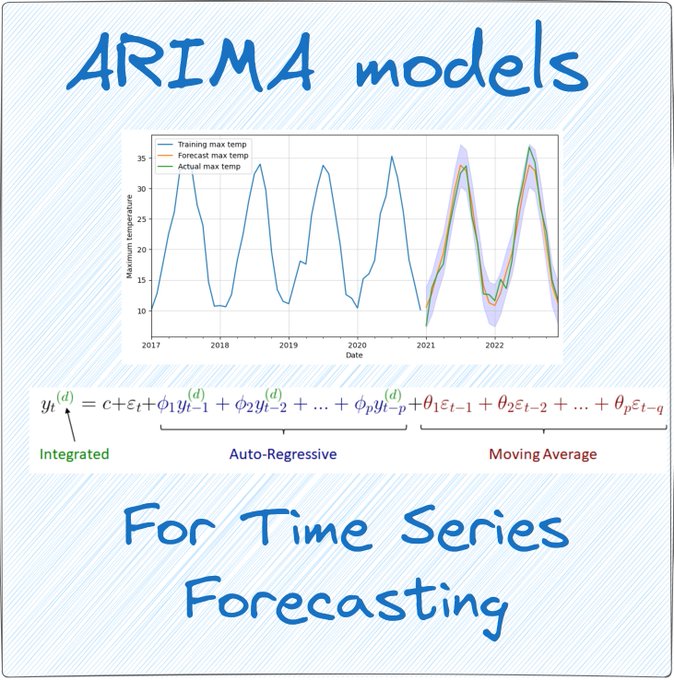
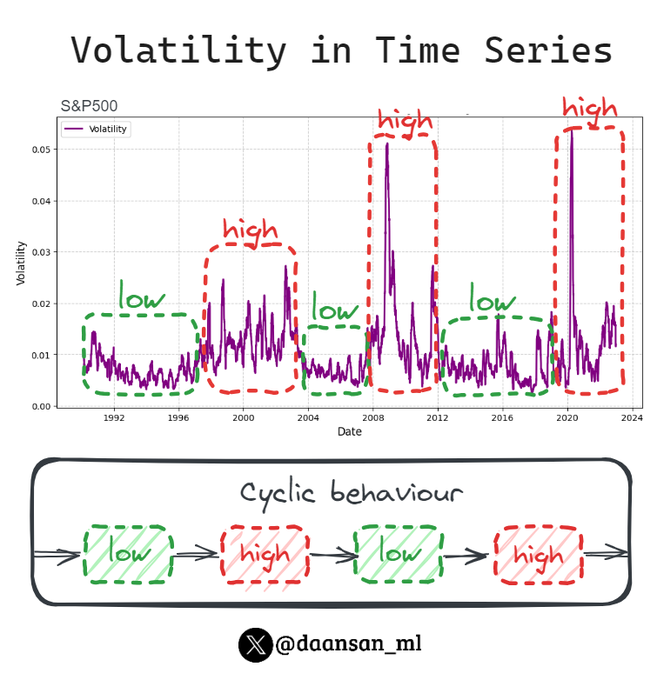
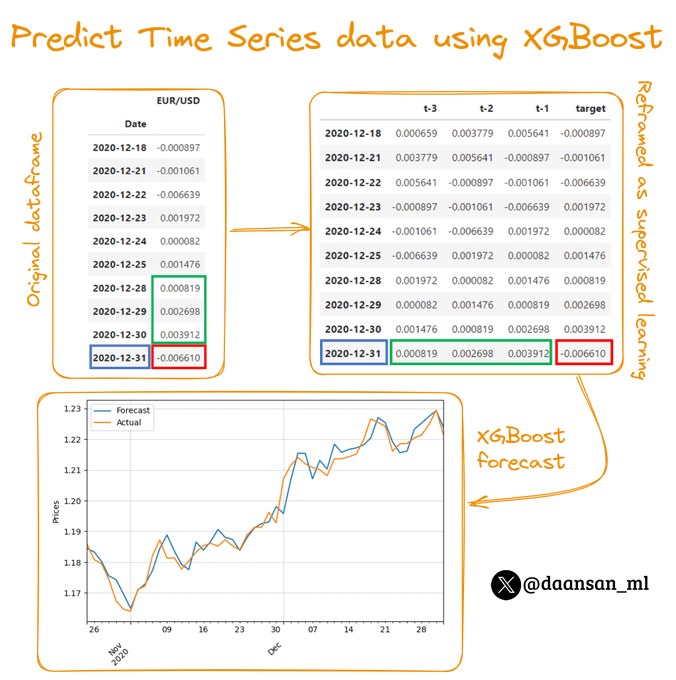
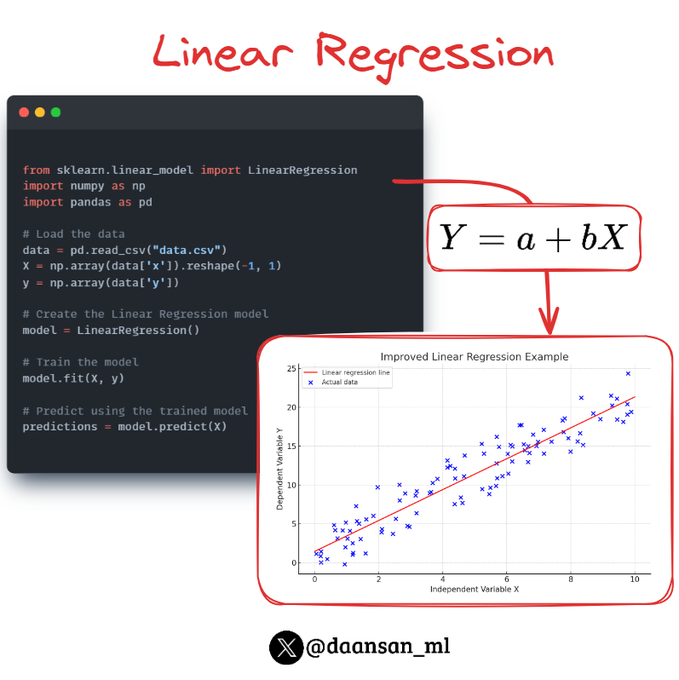
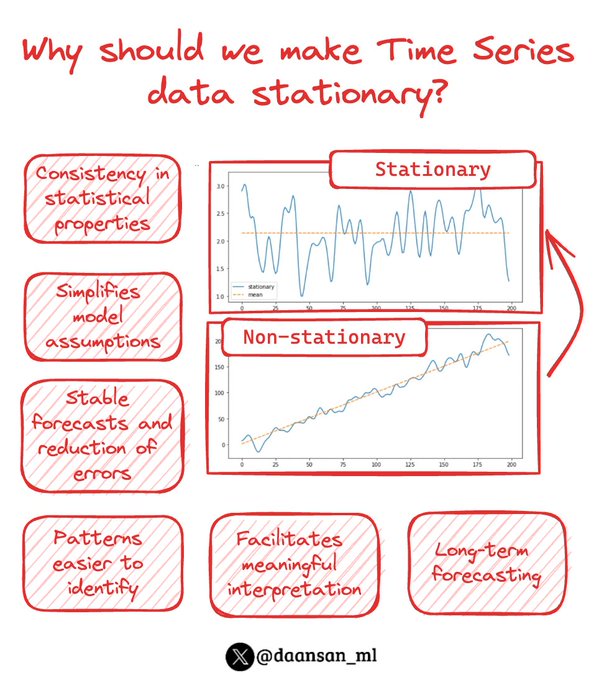
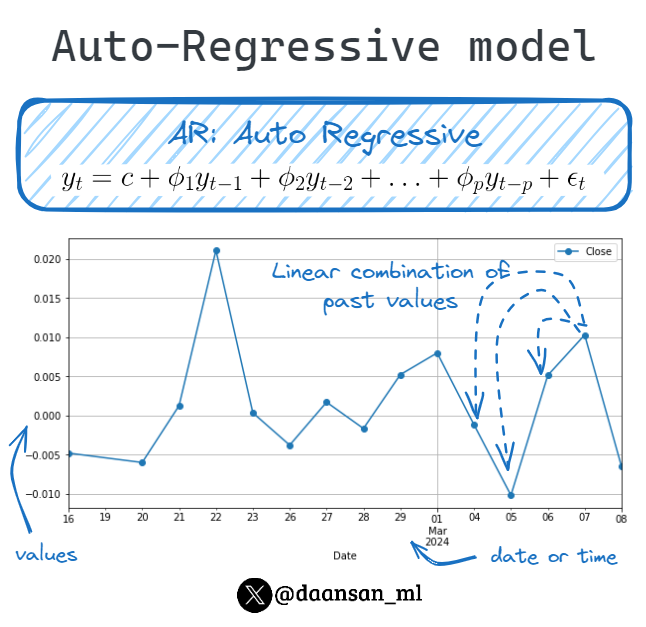
David Andrés 🤖📈🐍
@daansan_ml
9,904
Followers
396
Following
818
Media
9,084
Statuses
📈 I summarise Machine Learning and Time Series concepts in an easy and visual way • 💊Follow me in 👉 Inquiries in david @mlpills .dev
Don't wanna be here?
Send us removal request.